Clear Sky Science · de
Vorrang von Feature-Engineering gegenüber architektonischer Komplexität für die Prognose intermittierender Nachfrage
Warum die Vorhersage seltener Verkäufe wichtig ist
Hinter jeder Autowerkstatt oder jedem Ersatzteillager verbirgt sich ein stilles Rätsel: wie viele langsam drehende Ersatzteile sollten im Regal liegen? Diese Artikel verkaufen sich selten und unvorhersehbar, müssen aber verfügbar sein, wenn ein Fahrzeug ausfällt. Überbestellung bindet Geld in verstaubtem Lagerbestand; Unterbestellung führt dazu, dass Kundinnen und Kunden warten, während Teile eilbestellt werden. Dieser Artikel geht dieses alltägliche, aber kostenintensive Problem an und stellt eine einfache Frage: Lohnt es sich, immer kompliziertere Vorhersagemodelle zu verwenden, oder ist es besser, bestehende Modelle mit klügeren, sorgfältig gestalteten Signalen aus den Daten zu versorgen?
Von langen Nulllinien zu plötzlichen Spitzen
In vielen Lieferketten, insbesondere bei Automobilersatzteilen, ist die Nachfrage nicht gleichmäßig wie bei Milch oder Brot. Stattdessen gibt es lange Perioden mit monatelangen Nullverkäufen, unterbrochen von plötzlichen Bestellungen von wenigen Einheiten. Die Autorinnen und Autoren analysieren mehr als 56.000 Händler‑Teil‑Kombinationen, die etwa 1,4 Millionen Monatsaufzeichnungen umfassen, und stellen fest, dass die meisten Reihen extrem spärlich sind: im Mittel gibt es viele Nullmonate pro Verkaufsmonat, und die Bestellmengen schwanken stark. Traditionelle statistische Verfahren wie Crostons Ansatz und seine Verfeinerungen wurden für diese Art von „Ein/Aus“-Nachfrage entwickelt und liefern stabile, interpretierbare Prognosen, behandeln aber jedes Teil isoliert und können Zusatzinformationen wie Preise oder Produktmerkmale nur schwer nutzen. Moderne Machine‑Learning‑Systeme können prinzipiell all diese Informationen verwenden, tun sich jedoch schwer, wenn die Daten größtenteils Nullen enthalten und nur gelegentlich aussagekräftig sind.
Eine einfache Idee: dem Modell beibringen, was wirklich zählt
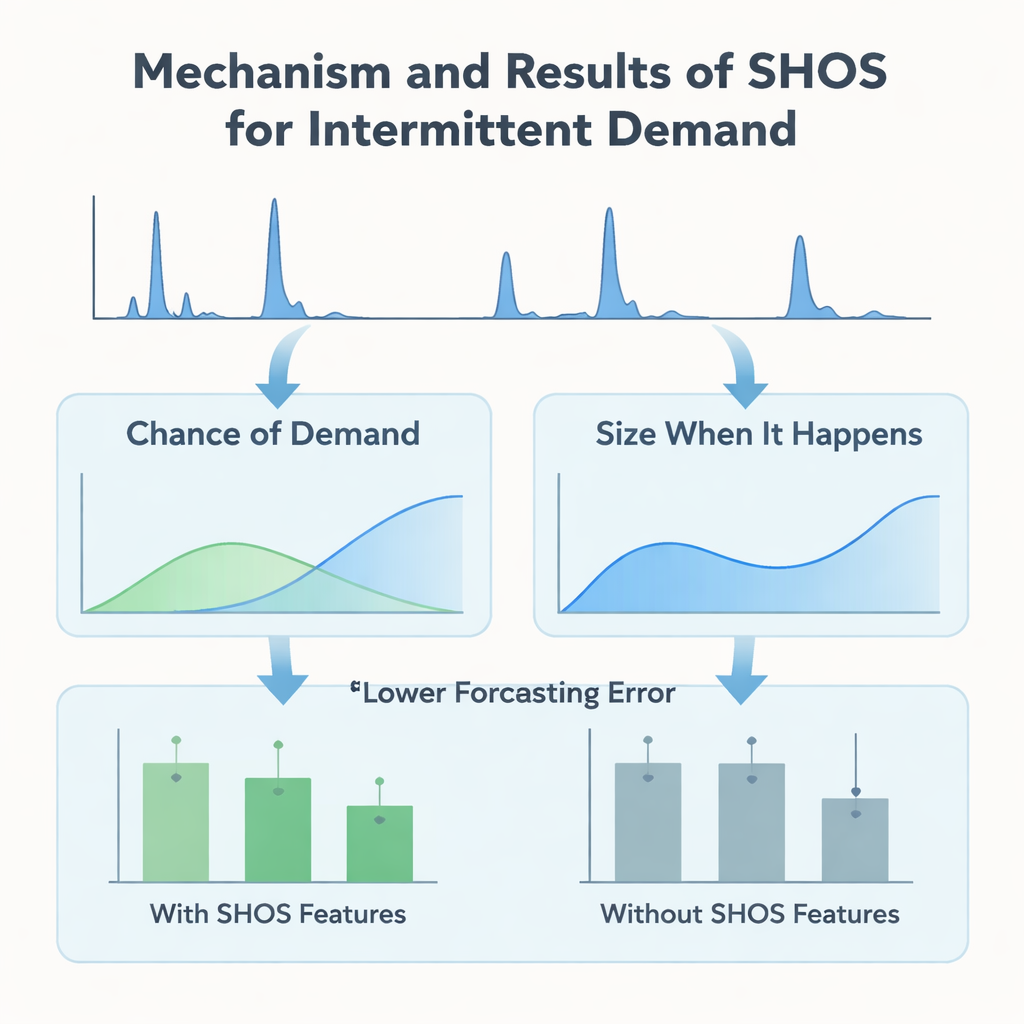
Statt immer aufwendigere Machine‑Learning‑Architekturen zu entwickeln, konzentrieren sich die Autorinnen und Autoren darauf, was dem Modell zugeführt wird. Sie stellen das Smoothed Hybrid Occurrence–Size (SHOS) Framework vor, eine schlanke statistische Routine, die über jede Nachfragereihe läuft. In jedem Monat erzeugt SHOS zwei Zahlen: die geschätzte Wahrscheinlichkeit, dass im nächsten Monat überhaupt Nachfrage auftritt, und die typische Größe dieser Nachfrage, falls sie eintritt. Dies erreicht es durch sorgfältiges Glätten vergangener Nullen und Nicht‑Nullen, passt sein Verhalten für sehr spärliche Reihen an und reagiert schneller, wenn die Nachfrage nach einer langen Pause plötzlich zurückkehrt. Entscheidend ist, dass SHOS nicht das finale Vorhersagemodell ist. Seine Ausgaben werden zu zusätzlichen Eingabe‑Features für Standard‑Machine‑Learning‑Algorithmen, neben einfachen Merkmalen wie jüngsten Verkäufen, gleitenden Durchschnitten und statischen Produktdetails.
Feature‑Qualität vor Modellkomplexität
Um zu prüfen, ob diese statistische „Vorverarbeitung“ wirklich hilft, bauen die Forschenden ein kontrolliertes Experiment auf. Sie vergleichen eine Reihe populärer Modelle — Gradient‑Boosted Trees, Random Forests und lineare Methoden — mit und ohne SHOS‑Features, alle trainiert auf demselben mit Nullen gefüllten Monats‑Panel und evaluiert mittels eines strengen Rolling‑Window‑Schemas, das die reale Nutzung nachahmt. Sie testen auch ausgefeiltere zweistufige „Hurdle“-Modelle, die separat vorhersagen, ob Nachfrage auftritt und wie groß sie ist. Über 11 Validierungsfenster halbiert das Hinzufügen von SHOS‑Features nahezu den durchschnittlichen Prognosefehler für stark intermittierende Artikel und senkt eine wichtige Geschäftskennzahl, den gewichteten mean absolute percentage error, um über 40 %. Überraschenderweise übertreffen die zweistufigen Architekturen, obwohl komplexer und speziell für diese Datenart zugeschnitten, keinen einfachen, geradlinigen Regressor, der einfach die SHOS‑Signale aufnimmt.
Nachvollziehen, wie das Modell seine Entscheidungen trifft
Das Team geht über die reine Genauigkeit hinaus und untersucht, wie die Modelle die erhaltenen Informationen tatsächlich nutzen. Mit SHAP, einem Standardwerkzeug zur Interpretation von Machine‑Learning‑Vorhersagen, zeigen sie, dass die auf SHOS basierenden Features — „Wahrscheinlichkeit der Nachfrage“ und „Größe im Nachfragerfall“ — konstant zu den einflussreichsten Eingaben gehören. Während langer Null‑Nachfrageperioden drückt eine niedrige SHOS‑Wahrscheinlichkeit die Prognosen in Richtung Null und verhindert so falschen Lageraufbau. Erscheint nach einer Durststrecke eine Nachfragelawine, hebt eine Rezenter‑Anpassung in SHOS schnell die Wahrscheinlichkeits‑ und Größen‑Schätzungen an, sodass das Modell reagieren kann, ohne auf einen einzelnen Ausreißer überzureagieren. Diese Verhaltensweisen zeigen sich sowohl im einfachen einstufigen Modell als auch in den komplexeren Hurdle‑Versionen und unterstreichen, dass der Hauptgewinn von der Qualität der Signale und nicht von architektonischen Tricks kommt.
Was das für alltägliche Bestandsentscheidungen bedeutet
Für Praktikerinnen und Praktiker, die die richtigen Teile auf Lager halten wollen, ist die Botschaft praktisch und beruhigend zugleich. Die Studie zeigt, dass sorgfältig gestaltete, statistisch fundierte Features große Verbesserungen bei der Prognose seltener, unregelmäßiger Verkäufe liefern können, ohne auf fragile, schwer zu wartende Modellkonfigurationen zurückgreifen zu müssen. Ein moderates, gut abgestimmtes Gradient‑Boosted‑Tree‑Modell mit SHOS‑Features schlägt oder erreicht die Leistung aufwendigerer Pipelines und bleibt dabei leichter in großem Maßstab zu implementieren und zu überwachen. Einfach ausgedrückt: Ihr Vorhersagesystem mit besseren Zusammenfassungen darüber zu füttern, wie oft und wie viel Kundinnen und Kunden wahrscheinlich bestellen, kann wichtiger sein, als auf den neuesten, komplexesten Algorithmus umzusteigen. Diese Betonung einfacher, interpretierbarer Bausteine macht den Ansatz attraktiv für groß angelegte, reale Lieferketten und legt nahe, dass ähnliche featurezentrierte Strategien auch in anderen Branchen mit intermittierender Nachfrage Erfolg bringen könnten.
Zitation: Nathan, B.S., Aravinth, P.M., Reddy, B.V.S. et al. Primacy of feature engineering over architectural complexity for intermittent demand forecasting. Sci Rep 16, 4792 (2026). https://doi.org/10.1038/s41598-026-35197-y
Schlüsselwörter: intermittierende Nachfrage, Ersatzteilprognose, Feature-Engineering, Supply-Chain-Analytik, Maschinelles Lernen