Clear Sky Science · de
Bewertung von ChatGPT-4o und Gemini für die Gicht‑Behandlung: eine vergleichende Analyse anhand der EULAR‑Leitlinien
Warum smarte Chatbots und schmerzende Gelenke wichtig sind
Gicht, eine schmerzhafte Form der Arthritis, die häufig den Großzeh befällt, wird weltweit immer häufiger. Ärztinnen und Ärzte haben bereits klare, wissenschaftlich fundierte Leitlinien zur Diagnose und Behandlung, trotzdem erhalten viele Patientinnen und Patienten nicht die optimale Versorgung. Gleichzeitig halten leistungsfähige KI‑Chatbots wie ChatGPT‑4o und Gemini Einzug in Kliniken, was eine einfache, aber entscheidende Frage aufwirft: Können diese Werkzeuge tatsächlich sichere, leitlinienkonforme Empfehlungen zur Gicht geben, oder können sie Ärztinnen, Ärzte und Patientinnen und Patienten in die Irre führen?
Prüfung, wie gut die Chatbots das Regelwerk befolgen
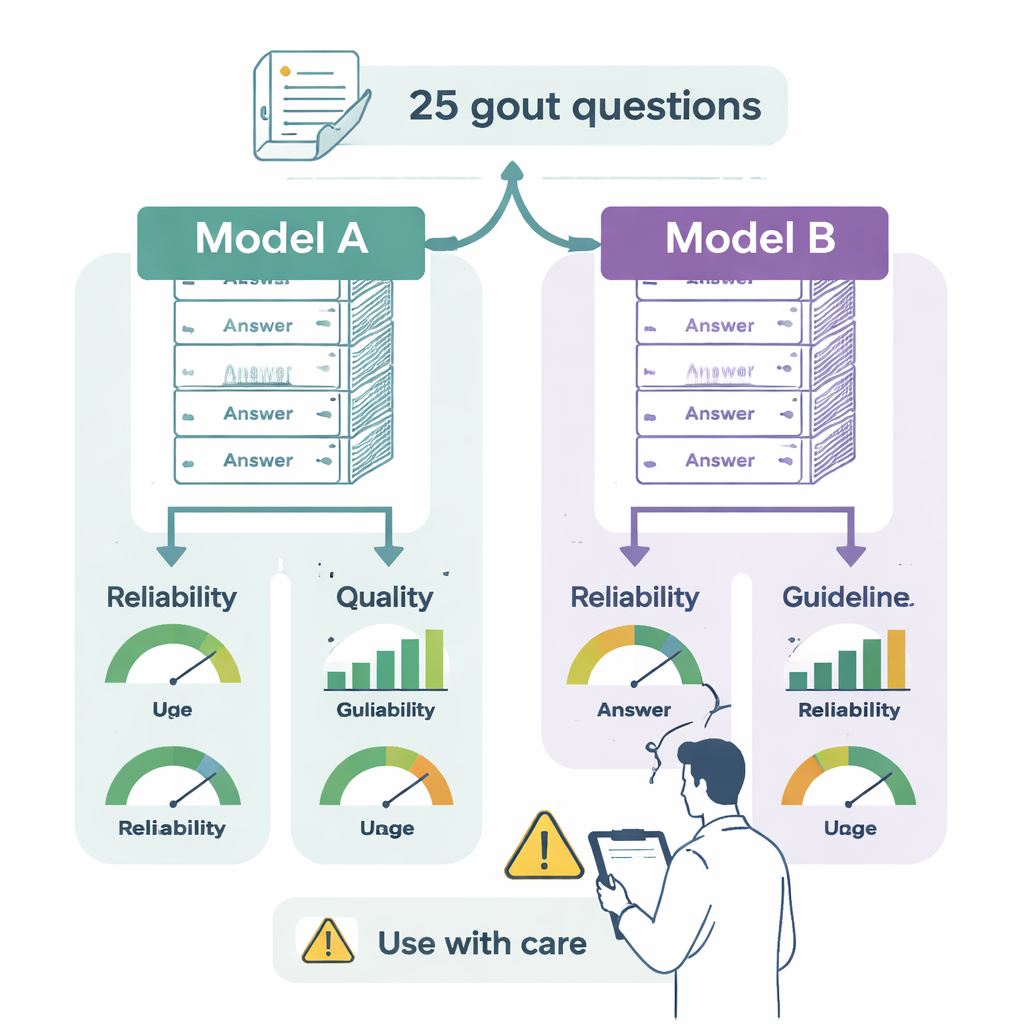
Die Forschenden prüften zwei führende Sprachmodelle – ChatGPT‑4o und Gemini 2.0 Flash – anhand der offiziellen europäischen (EULAR) Leitlinien zur Gicht. Zwei Spezialistinnen bzw. Spezialisten überführten 25 zentrale Empfehlungen aus den Leitlinien in arztähnliche Fragen zu Praxisfragen: wie Gicht zu diagnostizieren ist, wann uratsenkende Medikamente begonnen werden sollten, wie Anflüge zu behandeln sind, welche Zielwerte im Blut anzustreben sind und wie Lebensstil oder andere Medikamente anzupassen sind. Beide Chatbots erhielten dieselben Fragen in getrennten, sauberen Sitzungen, damit vorherige Antworten keine neuen beeinflussen konnten.
Wie die Antworten bewertet wurden
Jede Antwort wurde von zwei erfahrenen Gicht‑Klinikerinnen bzw. -Klinikern bewertet, die nicht wussten, welches Modell den Text erzeugt hatte. Sie bewerteten drei Aspekte. Erstens Zuverlässigkeit: Wirkt die Antwort ausgewogen, objektiv und vertrauenswürdig, oder lässt sie wichtige Fakten aus bzw. überschätzt sie Vorteile? Zweitens Qualität: Ist die Antwort klar, gut strukturiert und nützlich für eine Fachperson, die Entscheidungen trifft? Drittens Leitlinienkonformität: Entspricht sie den EULAR‑Empfehlungen vollständig, stimmt sie teilweise überein mit Lücken, oder widerspricht sie den Regeln direkt? Das Team prüfte außerdem die Lesbarkeit der Antworten mit gängigen Lesbarkeitskennzahlen, die schätzen, welches Bildungsniveau nötig ist, um einen Text zu verstehen.
ChatGPT vs. Gemini: Wer schnitt besser ab?
Beide Chatbots lieferten im Allgemeinen sinnvolle, klar formulierte Antworten und erinnerten häufig daran, eine medizinische Fachperson zu konsultieren. Wichtige Unterschiede traten jedoch zutage. ChatGPT‑4o stimmte in 76 % der Fälle vollständig mit den Gicht‑Leitlinien überein und lieferte in weiteren 20 % größtenteils korrekte, aber unvollständige Antworten; nur eine einzige Antwort enthielt einen klaren medizinischen Fehler. Gemini war in 48 % der Antworten vollständig konform und in 32 % teilweise korrekt, aber unvollständig. Besorgniserregender war, dass 12 % seiner Antworten korrekte Aussagen mit falschen Informationen vermischten und 8 % den Leitlinien klar widersprachen — zum Beispiel durch die Empfehlung eines breiten Einsatzes einer wirksamen antiinflammatorischen Wirkstoffklasse (IL‑1‑Inhibitoren), die EULAR nur für ausgewählte, schwer behandelbare Patientinnen und Patienten vorsieht, oder durch das Befürworten routinemäßiger Beginns uratsenkender Medikamente während eines akuten Anfalls, wo Expertinnen und Experten zu größerer Vorsicht raten.
Lesbar, aber kein Leichtlesetext
Bezüglich Stil waren die beiden Systeme überraschend ähnlich. Auf mehreren Leseskalen erzeugten beide Texte, die mindestens ein Hochschulniveau erforderten, um bequem verstanden zu werden. Das mag für Fachärztinnen und Fachärzte akzeptabel sein, ist aber für die meisten Patientinnen und Patienten deutlich zu komplex. Keines der Modelle lieferte Quellenangaben oder Links, sofern nicht ausdrücklich danach gefragt wurde, was die Überprüfbarkeit der Informationen erschwert. Die Übereinstimmung der Gutachterinnen und Gutachter untereinander wurde als gut bis ausgezeichnet bewertet, was darauf hindeutet, dass die Bewertungsleistung konsistent war und die Unterschiede zwischen den Chatbots eher real als subjektiv sind.
Was das für Menschen mit Gicht bedeutet
Insgesamt deutet die Studie darauf hin, dass fortgeschrittene Chatbots hilfreiche Assistenten für Ärztinnen und Ärzte in der Gichtversorgung sein können, aber nicht allein arbeiten sollten. ChatGPT‑4o war zuverlässiger, vollständiger und treuer gegenüber den Expertinnen‑ und Expertenleitlinien als Gemini; selbst seine seltenen Fehler können jedoch relevant sein, wenn es um Medikamente und Sicherheit geht. Beide Werkzeuge formulierten auf einem Niveau, das für die meisten Patientinnen und Patienten zu komplex ist, und es fehlt ihnen an eingebauter Transparenz bezüglich ihrer Quellen. Die Autorinnen und Autoren plädieren daher dafür, KI vorerst als vielversprechendes Unterstützungsmittel zu betrachten, das Klinikerinnen und Klinikern sowie Lehrenden helfen kann — jedoch nur, wenn seine Empfehlungen gegen aktuelle Leitlinien und fachlichen Rat geprüft werden, insbesondere bei Erkrankungen wie Gicht, bei denen kleine Dosierungs‑ und Zeitentscheidungen großen Einfluss auf Schmerz, langfristige Schäden und Lebensqualität haben können.
Zitation: Meral, H.B., Kolak, E. Evaluation of ChatGPT-4o and Gemini for gout management: a comparative analysis based on EULAR guidelines. Sci Rep 16, 4831 (2026). https://doi.org/10.1038/s41598-026-35166-5
Schlüsselwörter: Gicht, klinische Leitlinien, künstliche Intelligenz, große Sprachmodelle, Rheumatologie