Clear Sky Science · de
Domain‑adaptive Faster R‑CNN zur Erkennung fehlender PSA auf Baustellen aus körpergetragenen und allgemeinen Bildern
Warum fehlende Schutzkleidung dennoch durchrutscht
Sicherheitshelme, Warnwesten, Masken, Handschuhe und feste Schuhe sollten auf Baustellen unverzichtbar sein — dennoch treten Lücken auf, und sie können tödlich sein. Viele Projekte setzen inzwischen Kameras und künstliche Intelligenz ein, um Arbeiter ohne vorgeschriebene Ausrüstung zu markieren, doch diese Systeme tun sich schwer, weil echte Verstöße selten sind und schwer auf Film zu bekommen. Diese Studie untersucht einen Weg, Detektionssysteme klüger zu trainieren, indem sie Beispiele aus alltäglichen Straßenfotos nutzt, sodass automatisierte Sicherheitsprüfungen zuverlässiger werden, ohne auf Unfälle oder eine Häufung von Verstößen warten zu müssen.
Alltagsfotos als Sicherheitslektion nutzen
Die Grundidee ist einfach: Menschen an öffentlichen Orten oder in Büros tragen selten Baustellenausrüstung, daher enthalten Fotos aus diesen Umgebungen viele Beispiele dafür, „was man auf einer Baustelle nicht tragen sollte“. Die Herausforderung ist, dass diese Szenen sehr anders aussehen als echte Baustellen — Hintergründe, Beleuchtung und Kamerawinkel verändern das Erscheinungsbild von Personen. Der Autor behandelt diese beiden Welten als verschiedene „Domänen“: eine Source-Domäne mit zahlreichen Non‑PSA‑Beispielen aus allgemeinen Bildern und eine Target-Domäne mit weniger, aber realistischeren Baustellenbildern, viele davon aufgenommen von Helmkameras. Die Arbeit zeigt, dass durch sorgfältiges Angleichen dessen, was das Modell aus beiden Domänen lernt, das System fehlende Ausrüstung auf realen Baustellen deutlich genauer erkennt, als wenn es nur mit Baustellen‑Daten trainiert würde.
Wie der neue Sicherheitsprüfer eine Szene sieht
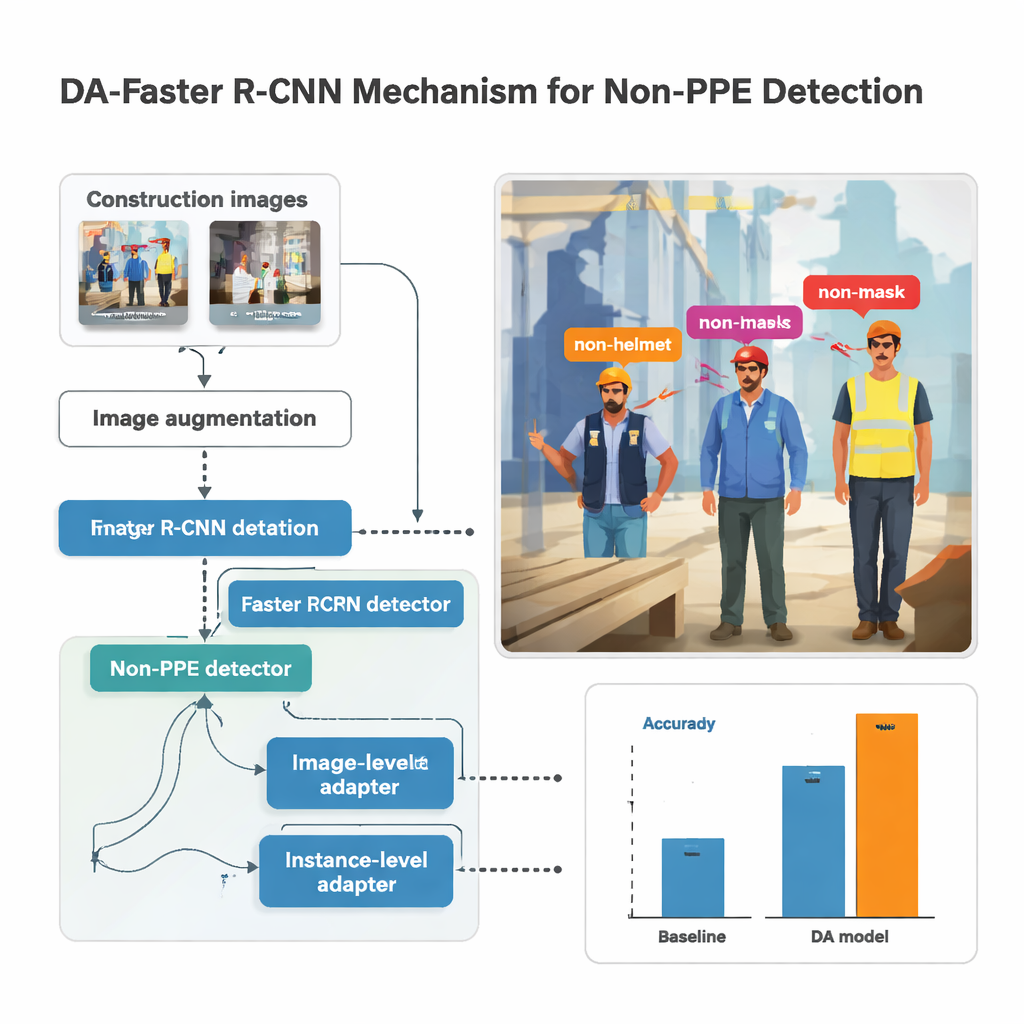
Die Forschung baut auf einem verbreiteten Objekterkennungssystem namens Faster R‑CNN auf, das ein Bild scannt, Regionen vorschlägt, die wahrscheinlich Personen oder Körperteile enthalten, und dann klassifiziert, was sich in jedem Rechteck befindet. Hier ist der Detektor darauf trainiert, fünf Arten fehlender Ausrüstung zu erkennen: kein Helm, keine Maske, keine Handschuhe, keine Weste und keine Sicherheitsschuhe. Bevor Bilder ins Modell gelangen, werden sie stark augmentiert — aufgehellt oder abgedunkelt, rotiert, verwischt und verzerrt — um wackelige Kameras, grelles Sonnenlicht und ungünstige Winkel zu simulieren, wie sie auf belebten Baustellen häufig vorkommen. Diese synthetische Vielfalt hilft dem Modell, stabil zu bleiben, wenn das reale Filmmaterial nicht perfekt ist, wie es oft bei Aufnahmen von körpergetragenen Kameras der Fall ist.
Dem System beibringen, den Hintergrund zu ignorieren
Einfach Straßenfotos mit Baustellenaufnahmen zu mischen reicht nicht aus; das Modell könnte lernen, fehlende Ausrüstung mit städtischen Bürgersteigen statt mit Personen zu assoziieren. Um das zu verhindern, führt die Studie „Domain‑Adaptation“-Module ein, die das System behutsam dazu bringen, sich auf Personen und Kleidung statt auf die Umgebung zu konzentrieren. Ein Modul betrachtet das Bild als Ganzes und bringt das Netzwerk dazu, so zu lernen, dass Bau‑ und Nicht‑Bau‑Fotos trotz unterschiedlicher Beleuchtung oder Ausrüstung ähnliche Gesamtmuster erzeugen. Ein anderes Modul arbeitet auf der Ebene jeder detektierten Person und sorgt dafür, dass die visuelle Signatur etwa eines ungeschützten Kopfes ähnlich aussieht, egal ob sie auf einem Gerüst oder in einer Einkaufsstraße erscheint. Diese Module werden adversarial trainiert: Ein kleiner Klassifikator versucht zu erkennen, aus welcher Domäne ein Bild stammt, während das Hauptnetzwerk lernt, diese Information zu verbergen und seinen Fokus auf die Schutzausrüstung zu richten.
Den Ansatz auf die Probe stellen
Der Autor stellte einen umfangreichen Datensatz zusammen, indem er Helmkameramaterial von fünf Baustellen in Südkorea mit mehreren öffentlichen Bildersammlungen kombinierte. Nach manueller Beschriftung jedes einzelnen Auftretens fehlender Helme, Masken, Handschuhe, Westen und Sicherheitsschuhe wurden Hunderte von Modellen mit verschiedenen Netzwerk‑Backbones und Parameterkonfigurationen trainiert. Der beste Performer nutzte ein tiefes Netzwerk namens ResNet‑152 zusammen mit intensiver Bildaugmentierung und den Domain‑Adaptation‑Modulen. Auf zuvor ungesehenen Baustellenbildern erzielte dieses Setup eine mean Average Precision — einen Gesamtwert für die Detektionsqualität — von etwa 86,8 Prozent, während es mit rund 33 Bildern pro Sekunde lief, schnell genug für nahezu Echtzeit‑Überwachung. Im Vergleich zu konventionelleren überwachten Systemen verbesserte das adaptierte Modell die Genauigkeit um bis zu 14 Prozentpunkte und gegenüber einer einfacheren Baseline sogar um bis zu 39 Punkte.
Was das für sicherere Baustellen bedeutet
Für Nicht‑Fachleute lautet die Botschaft: Klügeres Training, nicht nur größere Datensätze, kann die automatisierte Sicherheitsüberwachung deutlich verlässlicher machen. Indem das System sowohl aus Alltagsfotos als auch aus realen Baustellen lernt und ihm beigebracht wird, unwichtige Hintergrunddetails zu ignorieren, erkennt der vorgeschlagene Ansatz fehlende Helme, Westen, Handschuhe, Masken und Sicherheitsschuhe mit hoher Zuverlässigkeit, selbst wenn echte Verstöße selten sind. Während die aktuelle Arbeit sich auf fünf Ausrüstungsarten und einen Hauptbaustellendatensatz konzentriert, bietet sie einen praxisnahen Leitfaden für künftige Systeme, die Gurte, Seile und andere Schutzausrüstung auf vielen Baustellen verfolgen könnten, sodass Aufsichtspersonen Probleme früh erkennen und Arbeiter sicherer halten können, ohne den ganzen Tag Videobilder beobachten zu müssen.
Zitation: Wang, S. Domain-adaptive faster R-CNN for non-PPE identification on construction sites from body-worn and general images. Sci Rep 16, 4793 (2026). https://doi.org/10.1038/s41598-026-35148-7
Schlüsselwörter: Baustellensicherheit, persönliche Schutzausrüstung, Computer Vision, Domain‑Anpassung, Objekterkennung