Clear Sky Science · de
Kompakte Deep‑Learning‑Modelle für Kolon‑Histopathologie: Fokus auf Leistungs‑ und Generalisierungsprobleme
Warum diese Forschung für Patienten und Ärzte wichtig ist
Kolonkarzinom gehört zu den tödlichsten Krebserkrankungen weltweit, doch die Diagnose beruht weiterhin darauf, dass Spezialisten Gewebeproben unter dem Mikroskop sorgfältig begutachten — eine zeitaufwändige Aufgabe, die anfällig für Meinungsverschiedenheiten ist. Diese Studie untersucht, ob sehr kleine, effiziente Künstliche‑Intelligenz‑(KI‑)Modelle Krebsgewebe im Kolon zuverlässig genug markieren können, um in der täglichen klinischen Praxis nützlich zu sein, auch in Einrichtungen mit begrenzter Rechenleistung. Sie offenbart außerdem eine versteckte Schwäche: Modelle, die während der Entwicklung nahezu perfekt erscheinen, können bei neuen, realen Daten trotzdem schwer versagen.
Computern beibringen, Mikroskopbilder zu lesen
Bei einer Kolonbiopsie untersuchen Pathologen dünne, gefärbte Gewebeschnitte unter dem Mikroskop. Krebsgewebe zeigt verzerrte Drüsen, unregelmäßige Zellformen und Invasion in umliegende Strukturen, während gesundes Gewebe geordnete, regelmäßige Muster aufweist. Die Autoren nutzten eine öffentliche Sammlung von 24.000 digitalen Bildern solcher Schnitte, gleichmäßig aufgeteilt in Krebs (Kolonadenokarzinom) und gutartiges Gewebe. Sie skalierten alle Bilder auf ein einheitliches kleines Format und wandten realistische Variationen an — kleine Drehungen, Spiegelungen, Zooms und sanfte Farbverschiebungen — um die natürlichen Unterschiede beim Schneiden, Färben und Scannen der Präparate zu simulieren. Diese sorgfältige Vorbereitung hilft den KI‑Modellen, sich auf relevante Gewebemerkmale statt auf oberflächliche Details wie exakte Orientierung oder Helligkeit zu konzentrieren.
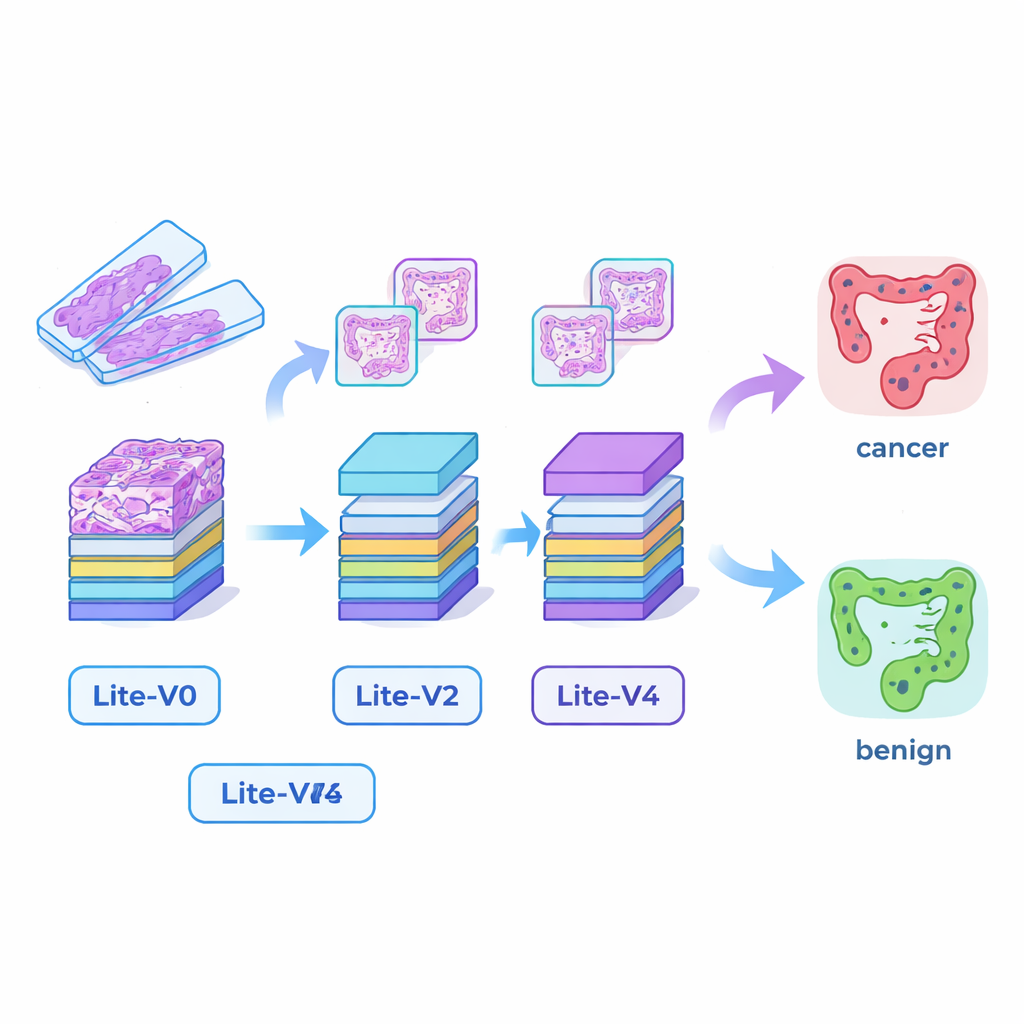
Kleine, aber fähige KI‑„Augen“ bauen
Viele erfolgreiche medizinische KI‑Systeme beruhen auf sehr großen Deep‑Learning‑Modellen, die leistungsstarke Grafikkarten und viel Speicher benötigen und sich daher schwer in kleineren Krankenhäusern oder am Krankenbett einsetzen lassen. Um diese Lücke zu schließen, entwarfen die Forschenden vier kompakte Faltungsnetzwerke — Lite‑V0, Lite‑V1, Lite‑V2 und Lite‑V4. Jedes betrachtet dieselben Eingabebildausschnitte, unterscheidet sich jedoch in der Anzahl der Schichten und Filter, mit denen visuelle Merkmale wie Kanten, Texturen und Drüsenformen erkannt werden. Alle vier folgen einem einfachen, transparenteren Aufbau: wiederholte Blöcke aus Standard‑Convolution, Normalisierung und Pooling, gefolgt von einem kleinen „Entscheidungskopf“, der die Wahrscheinlichkeit für Krebs oder gutartiges Gewebe ausgibt. Ziel war es zu ermitteln, wie viel Genauigkeit sich aus Modellen herausholen lässt, die klein genug sind, um bequem auf einfacher Klinik‑Hardware zu laufen.
Beeindruckende Werte im Labor
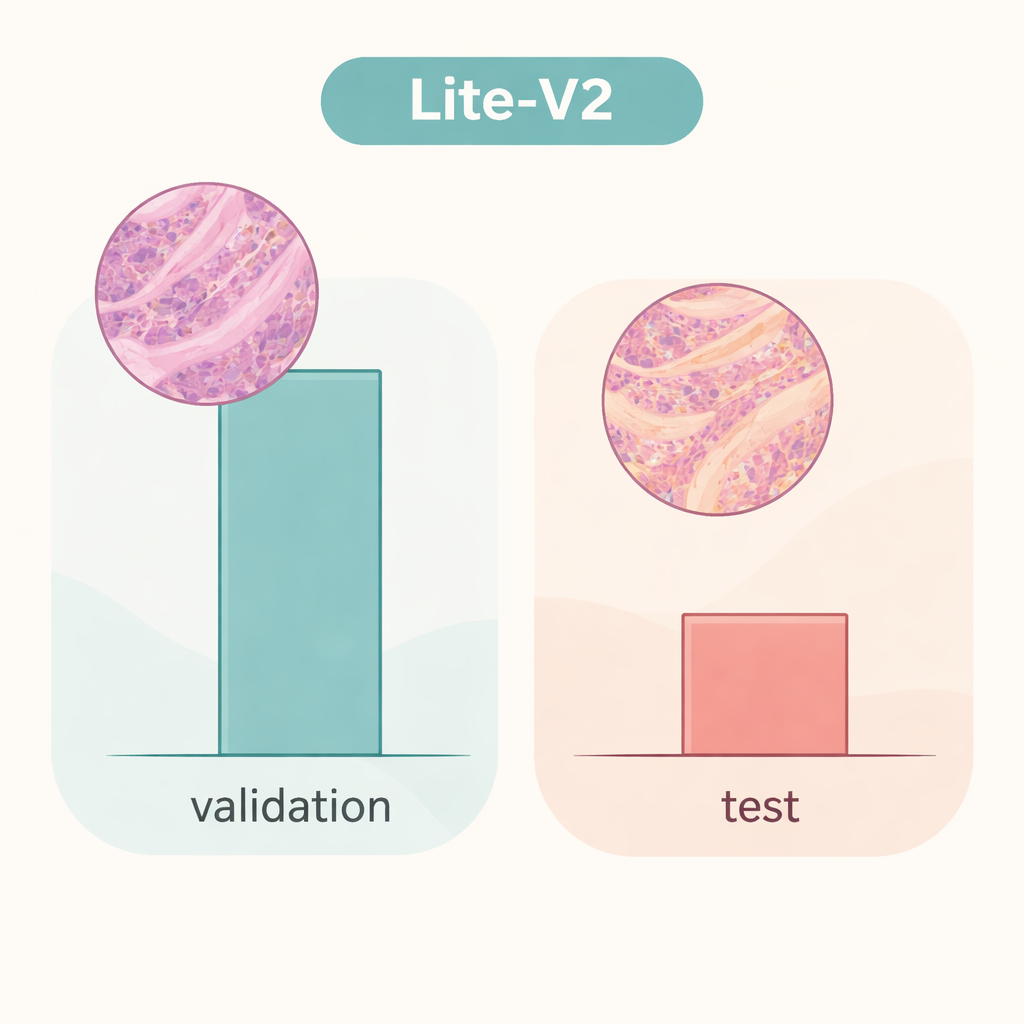
Das Team trainierte und verglich alle vier Modelle anhand einer festen Aufteilung des Datensatzes und verwendete allgemein akzeptierte Kennzahlen: Genauigkeit, einen balancierten F1‑Score, der Fehler in beiden Klassen gleich gewichtet, Konfusionsmatrizen sowie diagnostische Plots wie ROC‑ und Precision‑Recall‑Kurven. Ein mittelgroßes Modell, Lite‑V2, erwies sich als Spitzenreiter. Trotz einer Größe von nur etwa 1,5 Megabyte und rund 128.000 trainierbaren Parametern erreichte es auf dem internen Validierungsset fast fehlerfreie Ergebnisse, mit einem makro F1‑Score von etwa 0,999 sowie nahezu perfekter Sensitivität und Spezifität. Anders gesagt: In dieser sorgfältig vorbereiteten Umgebung konnte Lite‑V2 fast immer zwischen krebsartigem und gutartigem Kolongewebe unterscheiden und blieb dabei schnell und leichtgewichtig genug für den Einsatz auf bescheidener Hardware.
Wenn reale Variationen den Zauber brechen
Die Geschichte ändert sich jedoch dramatisch, wenn dasselbe Lite‑V2‑Modell auf einen unabhängigen Bildsatz getestet wird, der sich subtil in Weisen unterscheidet, die Präparate aus einem anderen Labor nachahmen — was Forschende als „Domänenverschiebung“ bezeichnen. Auf diesem ungesehenen Testsatz sank die Gesamtgenauigkeit auf etwa 50 %, und der balancierte F1‑Score fiel auf ungefähr 0,33. Das Modell erkannte weiterhin viele Krebsproben, tat sich aber bei gesundem Gewebe schwer und etikettierte einen großen Anteil fälschlich als malign. Das zeigt, dass das Netzwerk Details gelernt hatte, die eng an die ursprüngliche Datenquelle gebunden waren — etwa Färbestil oder Scanner‑Eigenschaften — statt robuste, übertragbare Krankheitsmerkmale. Die Arbeit macht deutlich, dass glänzende Ergebnisse bei interner Validierung ein falsches Sicherheitsgefühl vermitteln können, wenn Modelle nicht mit wirklich unterschiedlichen Daten geprüft werden.
Was das für zukünftige KI‑Diagnosetools bedeutet
Für Laien ist die Botschaft zweigeteilt. Erstens: Kompakte KI‑Systeme können tatsächlich Expertenniveau bei Kolon‑Gewebebildern erreichen und zugleich klein und effizient genug für eine breite Verfügbarkeit bleiben, was schnellere Screenings und Entlastung für überlastete Pathologen ermöglicht. Zweitens und ebenso wichtig: Ein Modell, das auf seinem Heimdatensatz „perfekt“ wirkt, kann bei Bildern aus einem neuen Krankenhaus massiv versagen. Die Autorinnen und Autoren plädieren dafür, dass künftige Arbeiten darauf abzielen müssen, diese leichtgewichtigen Modelle robust gegen Änderungen bei Färbung, Scannern und Patientenpopulationen zu machen — etwa durch färbungs‑robustes Training, Domänenanpassung und breitere multizentrische Datensätze. Bis dahin sollte KI als vielversprechende Assistenz angesehen werden, nicht als alleinentscheidendes Instrument in der Krebsdiagnostik.
Zitation: Hanif, F., Raza, A. & Mohammed, H.A. Compact deep learning models for colon histopathology focusing performance and generalization challenges. Sci Rep 16, 5489 (2026). https://doi.org/10.1038/s41598-026-35119-y
Schlüsselwörter: kolonkarzinom, histopathologie, deep learning, leichtgewichtige CNN, Domänenverschiebung