Clear Sky Science · de
Vorhersage wurzelnaher Proteine mithilfe eines großen Protein-Sprachmodells und Hypergraph-Convolutional-Netzwerken
Warum Wurzeln und ihre verborgenen Helfer wichtig sind
Wenn wir daran denken, Pflanzen gesund zu halten, stellen wir uns meist Blätter und Früchte vor. Viel vom Erfolg einer Pflanze spielt sich jedoch unsichtbar im Boden ab. Dort helfen spezielle wurzelnahen Proteine der Pflanze, Wasser und Nährstoffe aufzunehmen und mit Stressfaktoren wie Dürre oder schlechten Böden umzugehen. Diese wichtigen Proteine allein im Labor zu finden, ist langsam und teuer. Diese Studie stellt ein leistungsfähiges Computermodell vor, Hypergraph-Root genannt, das Proteinsequenzen rasch scannen und vorhersagen kann, welche davon wahrscheinlich wurzelnah sind — ein schnellerer Weg zu widerstandsfähigeren Nutzpflanzen und besseren Ernten.
Verborgene Arbeitstiere im Boden
Pflanzenwurzeln verankern die Pflanze nicht nur. Sie nehmen dauerhaft ihre Umgebung wahr, ziehen Mineralstoffe ein und kommunizieren mit Bodenmikroben. Wurzelnahen Proteine sind zentral für all dies: Sie beeinflussen, wie Wurzeln wachsen, wie sie auf Hitze, Trockenheit oder Nährstoffmangel reagieren und wie sie mit nützlichen Mikroben interagieren. Weil diese Proteine Ertrag und Widerstandsfähigkeit stark beeinflussen, interessieren sich Landwirte und Züchter für sie, auch wenn sie sie nie direkt sehen. Trotzdem bleiben viele dieser Proteine unentdeckt, vor allem weil traditionelle Methoden — wie Proteomik und Genexpressionsstudien — teure Geräte, komplexe Analysen und mühsame Experimente erfordern.
Proteinsequenzen in Hinweise verwandeln
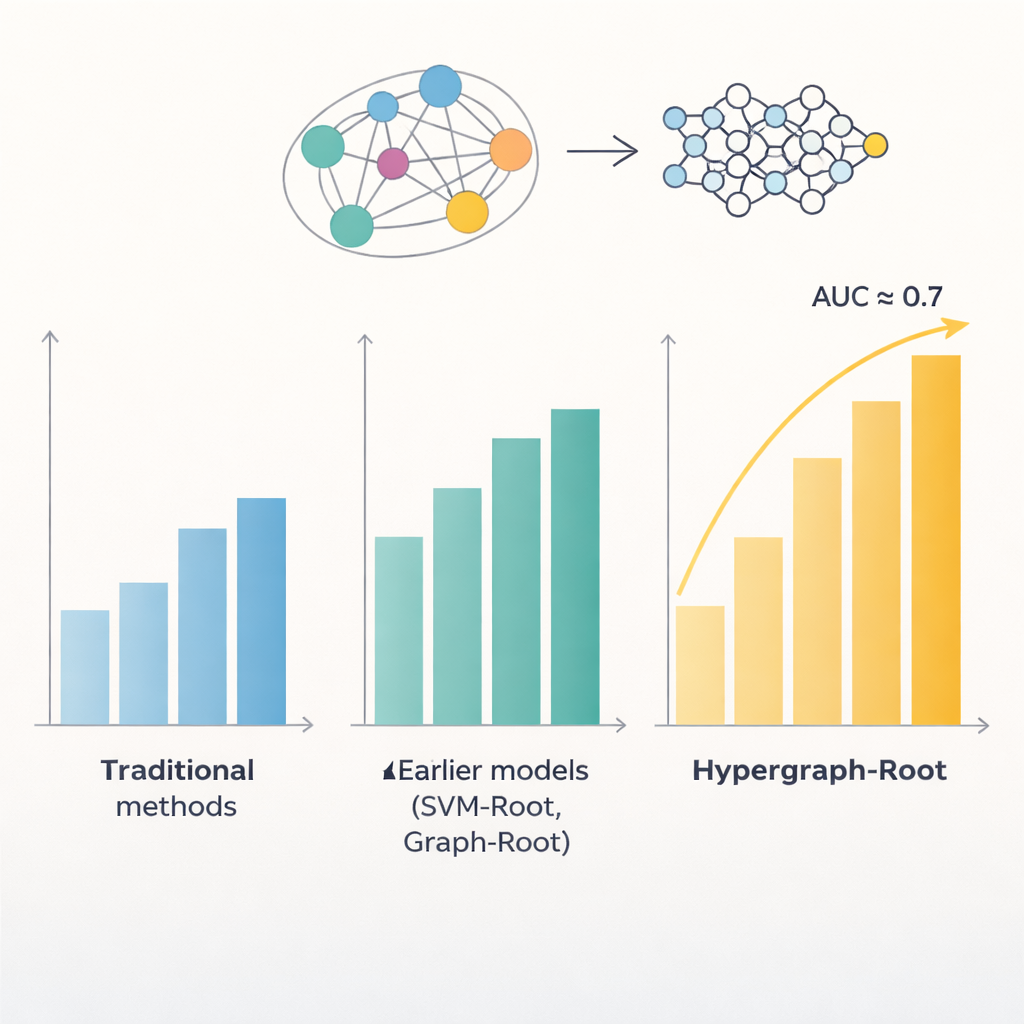
Proteine bestehen aus Reihen von Aminosäuren, und Muster in diesen Reihen verraten oft, wo ein Protein in der Pflanze wirkt und was es tut. Frühere Computermodelle versuchten, diese Muster zu nutzen, um wurzelnahen Proteine zu erkennen, erreichten jedoch nur Genauigkeiten unterhalb von 80 Prozent. Ein Problem war, dass sie Beziehungen zwischen Aminosäuren recht einfach behandelten, meist als Paare. Ein weiteres, dass sie sich auf eingeschränkte Arten von Merkmalen stützten, die aus Sequenzen extrahiert wurden. Die Autoren vermuteten, dass reichhaltigere Darstellungen jedes Proteins zusammen mit intelligenteren Methoden zur Modellierung von Aminosäurebeziehungen subtilere Muster aufdecken könnten, die mit Wurzelfunktionen verknüpft sind.
Tricks aus Sprache und Netzwerken entleihen
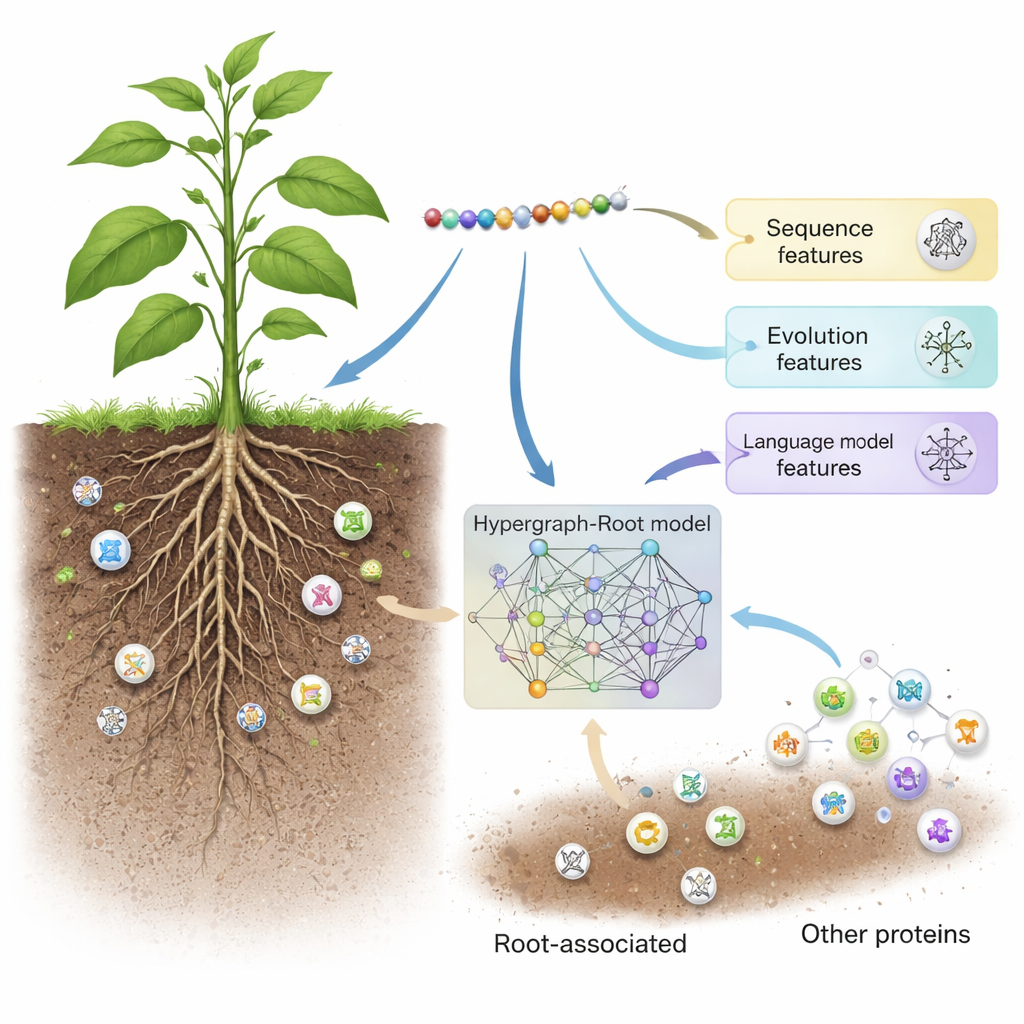
Hypergraph-Root beginnt damit, jedes Protein auf drei komplementäre Weisen zu beschreiben. Es verwendet traditionelle Sequenzbewertungsschemata (BLOSUM62 und positionsspezifische Scoring-Matrizen), die erfassen, wie Aminosäuren sich evolutionär gegenseitig ersetzen. Hinzu kommt eine moderne Beschreibung aus einem Protein-Sprachmodell namens ProtT5 — Software, die auf Millionen von Proteinsequenzen trainiert wurde, ähnlich wie ein Textvorhersagemodell mit menschlicher Sprache trainiert wird. ProtT5 erzeugt für jede Aminosäure eine reichhaltige numerische Einbettung, die strukturelle und funktionelle Hinweise kodiert. Zusammen liefern diese drei Perspektiven einen detaillierten Fingerabdruck jedes untersuchten Proteins.
Komplexe Verbindungen innerhalb von Proteinen abbilden
Um über einfache paarweise Vergleiche hinauszugehen, sagten die Forschenden voraus, wie nahe Aminosäuren in der 3D-Struktur eines Proteins zueinander liegen, und verwendeten diese Information, um einen Hypergraphen zu bauen — ein Netzwerk, in dem eine einzelne Verbindung mehr als zwei Aminosäuren gleichzeitig verknüpfen kann. Ein spezialisiertes neuronales Netzwerk, das Hypergraph-Convolutional-Network, verarbeitet dieses strukturbewusste Netzwerk und verfeinert die Protein-Fingerabdrücke zu höherstufigen Merkmalen. Ein Multi-Head-Attention-Modul lernt dann, welche Teile des Proteins die nützlichsten Signale enthalten, um zu entscheiden, ob es wurzelnah ist. Schließlich wandelt ein Standard-Klassifikator diese verdichteten Merkmale in eine Wahrscheinlichkeitsbewertung um: wurzelnah oder nicht. In vielen Trainingsläufen und sowohl auf ausgeglichenen als auch unausgeglichenen Testmengen erreichte Hypergraph-Root Genauigkeiten über 83 Prozent und eine Fläche unter der ROC-Kurve (AUC) von etwa 0,9 und übertraf damit deutlich frühere Modelle.
Was das Modell offenbart und warum das wichtig ist
Über die reine Genauigkeit hinaus lieferte das Modell Einsichten, welche Informationen am wichtigsten sind. Merkmale aus dem ProtT5-Sprachmodell trugen stärker bei als traditionelle sequenz- und evolutionsbasierte Merkmale, was darauf hindeutet, dass große, vortrainierte Modelle subtile biologische Signale erfassen können, die ältere Methoden übersehen. Auch die Hypergraph-Komponente erwies sich als wichtig: Ihr Entfernen oder Ersetzen durch ein einfacheres Graphmodell verringerte die Leistung. Als die Forschenden Hypergraph-Root auf Proteine anwendeten, die zuvor nicht als wurzelnah eingestuft waren, hob es einige Kandidaten hervor, deren bekannte Funktionen — etwa Membrantransport und Protein-Markierung in Wurzeln — stark darauf hindeuten, dass sie eine Rolle in der Wurzelbiologie spielen. Diese Kandidaten liefern jetzt klare Shortlists für experimentelle Biologinnen und Biologen, die sie im Labor testen können.
Von schlauen Vorhersagen zu stärkeren Nutzpflanzen
Alltäglich gesprochen ist Hypergraph-Root wie eine expertin/ein Experte in der Pflanzenbiologie-Bibliothek: Ausgehend allein von den "Buchstaben" eines Proteins schätzt es ab, ob dieses Protein wahrscheinlich in den Wurzeln wirkt. Indem es Erkenntnisse aus Sprachmodellen, evolutionsgeschichtliche Informationen und komplexe strukturelle Beziehungen kombiniert, verbessert es frühere Vorhersagewerkzeuge deutlich. Es ersetzt zwar keine Experimente, kann aber Tausende von Möglichkeiten auf einige handhabbare Kandidaten reduzieren und so Zeit und Geld sparen. Langfristig könnten solche Modelle die Entdeckung wurzelnaher Proteine beschleunigen, die Pflanzen helfen, Hitze, Dürre oder schlechte Böden zu überstehen — ein wichtiger Schritt hin zu widerstandsfähigerer Landwirtschaft in einem sich wandelnden Klima.
Zitation: Chen, L., Xun, X. & Zhou, B. Root-associated protein prediction using a protein large language model and hypergraph convolutional networks. Sci Rep 16, 4876 (2026). https://doi.org/10.1038/s41598-026-35110-7
Schlüsselwörter: wurzelnahen Proteine, Pflanzen-Bioinformatik, Deep Learning, Protein-Sprachmodelle, Ernte-Resilienz