Clear Sky Science · de
Ein multimodaler Lern- und Simulationsansatz zur Wahrnehmung in autonomen Fahrsystemen
Intelligentere selbstfahrende Autos
Selbstfahrende Autos versprechen sicherere Straßen und weniger Verkehr — vorausgesetzt, sie können die Welt um sie herum wirklich verstehen. Dieses Papier untersucht einen neuen Ansatz, der autonomen Fahrzeugen hilft, ihre Umgebung ähnlich wie ein aufmerksamer menschlicher Fahrer "zu sehen", "zu fühlen" und "vorherzusehen": durch das Zusammenführen verschiedener Sensoren, das sichere Testen in einer virtuellen Kopie der realen Welt und durch Maßnahmen, die die Entscheidungen des Fahrzeugs für Menschen transparenter machen.
Die Straße mit vielen „Sinnen“ wahrnehmen
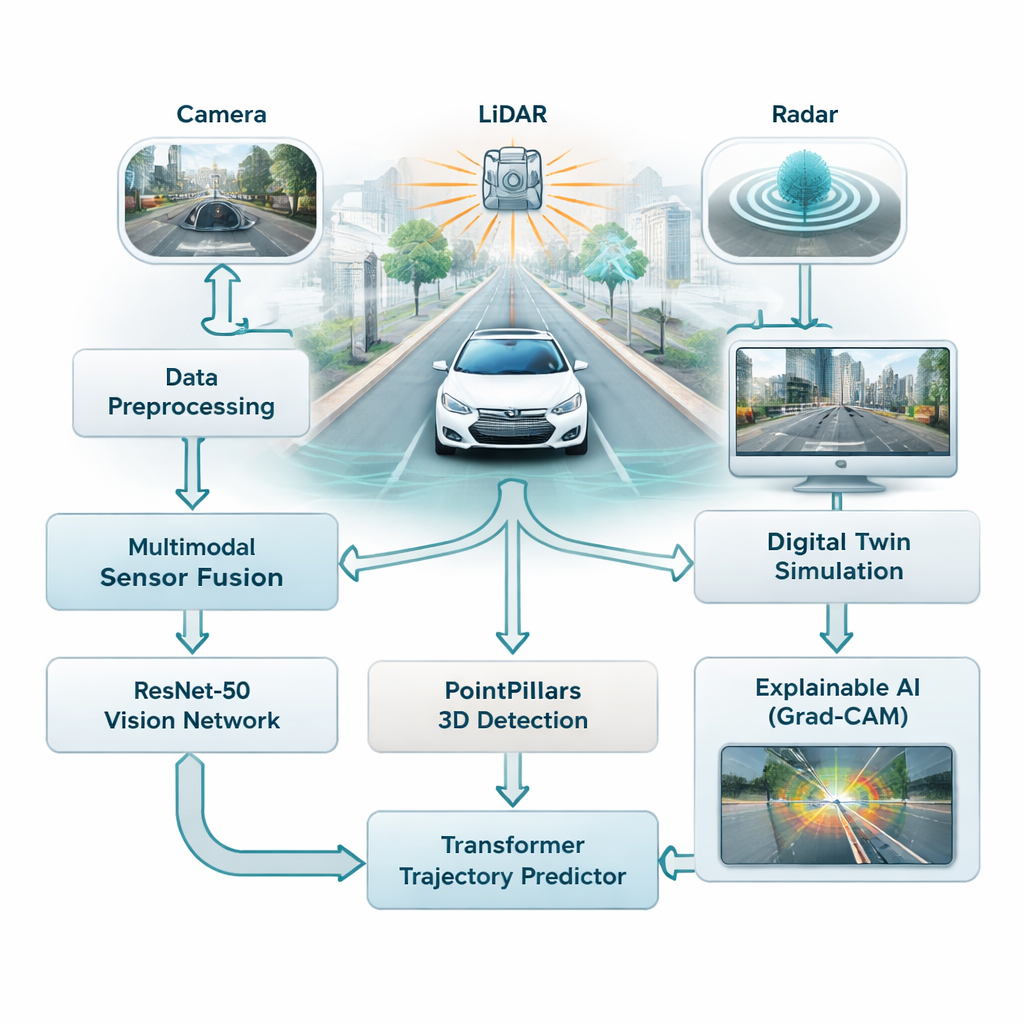
Die meisten Fahrerassistenzsysteme setzen heute stark auf Kameras, die bei gutem Licht gut funktionieren, bei Nebel, Regen oder in der Nacht jedoch Probleme haben. Diese Studie kombiniert drei verschiedene Sensortypen — Kameras, Laserscanner (LiDAR) und Radar — damit das Fahrzeug nicht von einer einzigen, anfälligen Informationsquelle abhängig ist. Kameras liefern reiche Farb- und Detailinformationen, LiDAR erzeugt ein präzises 3D-Bild der Szene und Radar bleibt bei schlechtem Wetter zuverlässig. Die Autoren verschmelzen alle drei Datenströme zu einer einheitlichen Sicht auf den Verkehr und verschaffen dem Fahrzeug so ein vollständigeres, robusteres Verständnis von Straßen, Fußgängern und anderen Fahrzeugen.
Das Auto lehren zu erkennen und vorherzusagen
Um diese Datenflut zu verstehen, nutzt das Framework zwei Familien moderner KI-Modelle. Zuerst analysiert ein tiefes Bildnetzwerk namens ResNet-50 Kamerabilder, um die Gesamtsituation zu erfassen — wie überfüllt die Straße ist, wo Fahrspuren sichtbar sind und wie die Szene strukturiert ist. Parallel dazu verarbeitet ein 3D-Modell namens PointPillars LiDAR-Punktwolken, um Fahrzeuge und andere Objekte im dreidimensionalen Raum zu lokalisieren. Diese Informationen werden dann in einen Transformer eingespeist, eine ursprünglich für Sprache entwickelte KI-Architektur, die hervorragend darin ist, zeitliche Veränderungen zu verstehen. Hier lernt sie vorherzusagen, wie sich nahe Fahrzeuge und andere bewegte Objekte in den nächsten Sekunden vermutlich bewegen werden, wobei sowohl deren bisherige Bewegung als auch die Straßenstruktur berücksichtigt werden.
Eine sichere virtuelle Teststrecke aufbauen
Anstatt riskante Situationen direkt auf öffentlichen Straßen zu testen, binden die Forscher ihr System in einen Digital Twin ein — eine virtuelle Replik realer Stadtstraßen, basierend auf einem großen öffentlichen Datensatz aus Boston und Singapur. In dieser simulierten Welt werden die Sensoren, Bewegungen und Umgebungen des Fahrzeugs wiedergegeben und beliebig verändert, während die KI versucht, Objekte zu verfolgen und deren zukünftige Bahnen vorherzusagen. Das System kann diese "Was-wäre-wenn?"-Szenarien in Echtzeit ausführen, mit Reaktionszeiten unter 50 Millisekunden, sodass Ingenieure Randfälle wie plötzliches Bremsen, enge Kurven oder überfüllte Kreuzungen erkunden können, ohne jemanden zu gefährden.
Ein Blick in die „Black Box“ der KI
Eine häufige Kritik an Deep Learning ist, dass es schwierig sein kann nachzuvollziehen, warum ein Modell eine bestimmte Entscheidung getroffen hat. Zur Lösung dieses Problems verwenden die Autoren eine Methode namens Grad-CAM, die die Bildbereiche hervorhebt, die die Ausgabe des Modells am stärksten beeinflusst haben. Diese Heatmaps zeigen beispielsweise, ob das Netzwerk bei der Schätzung von Trajektorien auf ein anderes Fahrzeug, einen Fußgänger oder eine Fahrbahnmarkierung achtet. Obwohl dieser Erklärungsbaustein offline läuft und nicht in der Echtzeitschleife des Fahrzeugs, hilft er Ingenieuren und Sicherheitsprüfern zu verifizieren, dass das System auf die richtigen Hinweise achtet — ein entscheidender Faktor für den Aufbau öffentlichen Vertrauens.
Wie viel besser fährt es?
Bei Tests in Hunderten städtischer Fahrszenen erkennt das vorgeschlagene Framework 3D-Objekte genau und sagt Bewegungen präziser voraus als einfache physikalische Regeln, die konstante Geschwindigkeit oder gleichmäßige Beschleunigung annehmen. Seine Prognosefehler — wie weit die vorhergesagten Positionen von der Realität abweichen — sind deutlich geringer als bei solchen Baselines und liegen nahe an einem starken rekurrenten KI-Modell, während es dennoch schnell genug für den Echtzeiteinsatz läuft. Sorgfältige Experimente, die verschiedene Netzwerkdesigns vergleichen, zeigen, dass ein tieferes Bildmodell und ein mittelstarker 3D-Detektor das beste Gleichgewicht zwischen Genauigkeit und Geschwindigkeit bieten und dass das System nach Modellkompression auch auf kleineren Bordcomputern einsetzbar ist.
Was das für Alltagsfahrer bedeutet
Für Nicht-Spezialisten lautet die Botschaft: Sicherere, zuverlässigere selbstfahrende Autos dürften aus einem Ansatz entstehen, der mehrere Sensoren kombiniert, vorhersagt, wie sich die Szene entwickeln wird, und in realistischen virtuellen Welten gründlich getestet wird. Indem Wahrnehmung, Vorhersage, Simulation und für Menschen verständliche Erklärungen in einem Design zusammengeführt werden, rückt diese Arbeit autonome Fahrzeuge näher an das Verhalten vorsichtiger, transparenter Partner im Straßenverkehr — statt an rätselhafte Maschinen.
Zitation: Almadhor, A., Al Hejaili, A., Alsubai, S. et al. A multimodal learning and simulation approach for perception in autonomous driving systems. Sci Rep 16, 5505 (2026). https://doi.org/10.1038/s41598-026-35095-3
Schlüsselwörter: autonomes Fahren, Sensorfusion, Trajektorienvorhersage, 3D-Objekterkennung, Digital-Twin-Simulation