Clear Sky Science · de
Ein hybrides intelligentes Bewertungsmodell für den Englisch-Übersetzungsunterricht mit verbessertem BERT und SVM
Warum eine intelligentere Bewertungsroutinen für Übersetzungen wichtig sind
Jedes Jahr verbringen Sprachlehrende unzählige Stunden damit, Schülerübersetzungen zu korrigieren. Zu entscheiden, ob ein Satz „gut genug“ ist, ist langsam, subjektiv und kann von Lehrkraft zu Lehrkraft stark variieren. Dieses Papier untersucht, ob künstliche Intelligenz diese Last teilen kann — durch schnelle, konsistente Bewertungen und Hinweise darauf, was schiefgelaufen ist — ohne die Lehrperson zu ersetzen. Vorgestellt wird ein neues Computermodell namens BERT-SVM EduScore, das speziell dafür entwickelt wurde, die Qualität englischer Übersetzungen im Unterricht zu beurteilen.
Von grobem Wortabgleich zu tieferem Verständnis
Seit Jahrzehnten beurteilen Computer Übersetzungen hauptsächlich, indem sie zählen, wie viele Wörter oder kurze Phrasen mit einer Referenzantwort übereinstimmen. Bekannte Werkzeuge wie BLEU oder METEOR tun dies sehr schnell, haben aber Schwierigkeiten mit der Flexibilität natürlicher Sprache: Zwei Sätze können dieselbe Bedeutung mit sehr unterschiedlicher Formulierung ausdrücken. Im Klassenzimmer, wo Lernende mit Synonymen und variierenden Satzstrukturen experimentieren, bestrafen diese älteren Metriken gültige Paraphrasen unfair und liefern wenig Hinweise auf konkrete Fehler. Forschende wenden sich daher neueren Methoden zu, die Bedeutungen statt Oberflächenwörtern vergleichen und leistungsfähige Sprachmodelle nutzen, die auf riesigen Textmengen trainiert wurden.
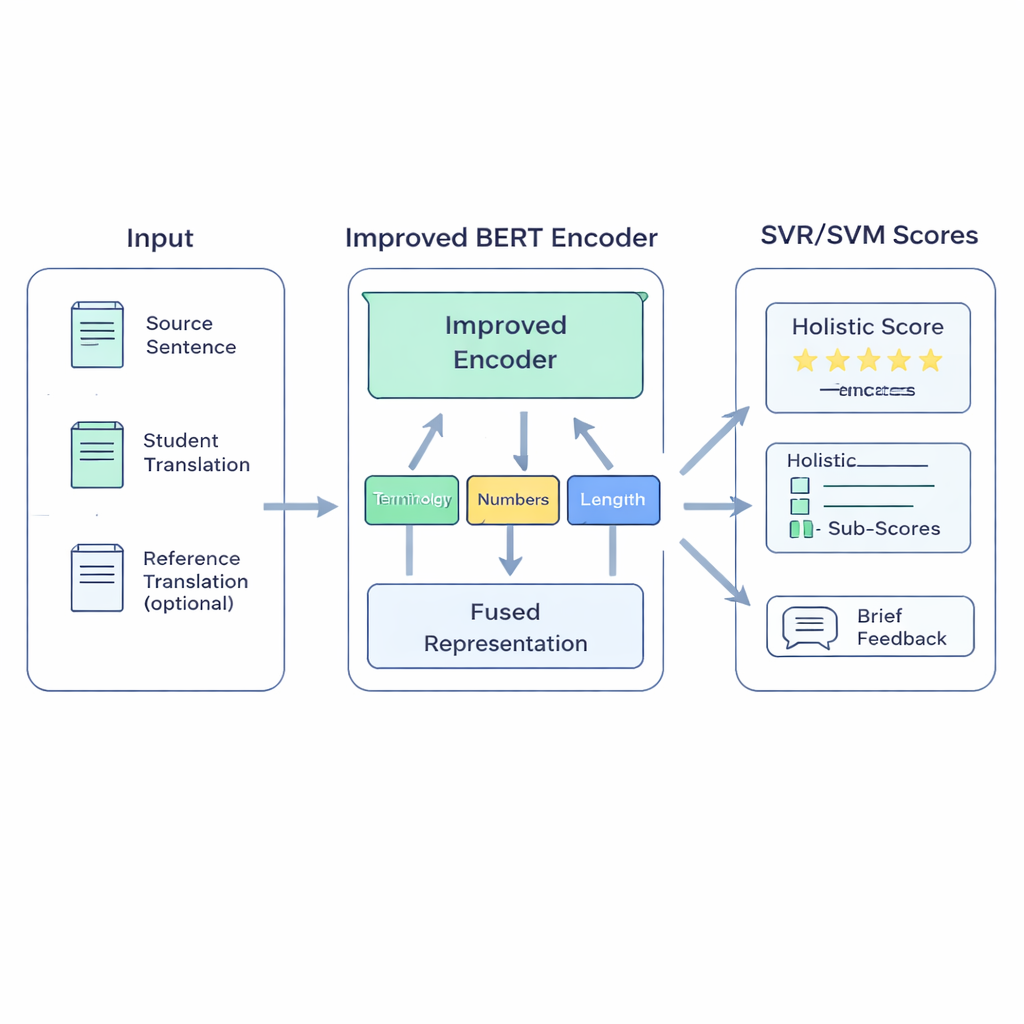
Ein hybrides Modell, gebaut für den Unterricht
Das vorgeschlagene System BERT-SVM EduScore kombiniert zwei Ansätze: tiefes Sprachverständnis und klassische, robuste Statistik. Zunächst verwendet es eine verbesserte Version des BERT-Sprachmodells, um drei Textstücke zu lesen: den Ursprungssatz, die Übersetzung der Schülerin bzw. des Schülers und — falls vorhanden — eine Referenzübersetzung. BERT wandelt diese in eine reichhaltige numerische Zusammenfassung um, die nicht nur wiedergibt, welche Wörter vorkommen, sondern auch, wie gut die Bedeutungen übereinstimmen. Darüber hinaus fügt das System eine kleine Reihe handgefertigter Prüfungen hinzu, die Lehrende interessieren — beispielsweise ob Fachbegriffe konsistent übersetzt werden, Zahlen und Einheiten erhalten bleiben, die Zeichensetzung sinnvoll ist und die Länge der Übersetzung dem Original entspricht.
Wie das System lernt, wie eine Lehrkraft zu bewerten
Diese Signale werden anschließend in Support-Vektor-Maschinen eingespeist, eine Familie von Algorithmen, die dafür bekannt ist, gut mit begrenzten Daten zu funktionieren. Ein Teil sagt eine Gesamtpunktzahl voraus; andere Teile können separate Bewertungen für Bereiche wie Genauigkeit oder Flüssigkeit liefern oder Übersetzungen in Qualitätsstufen einordnen. Damit sich das Modell an die im Unterricht typische Sprache anpasst, trainieren die Autoren BERT zunächst mit Texten, die Schülerarbeiten ähneln — ein Vorgehen, das als Domain-Adaptation bezeichnet wird. Sie schärfen BERTs Unterscheidungsvermögen weiter, indem es übt, gute von leicht veränderten schlechten Versionen eines Satzes zu unterscheiden. Schließlich, wenn hochwertige automatische Metriken wie COMET oder BLEURT verfügbar sind, lernt das System, einige ihrer Urteile zu imitieren, nimmt ihre Stärken auf, bleibt dabei aber an menschliche Bewertungen angepasst.
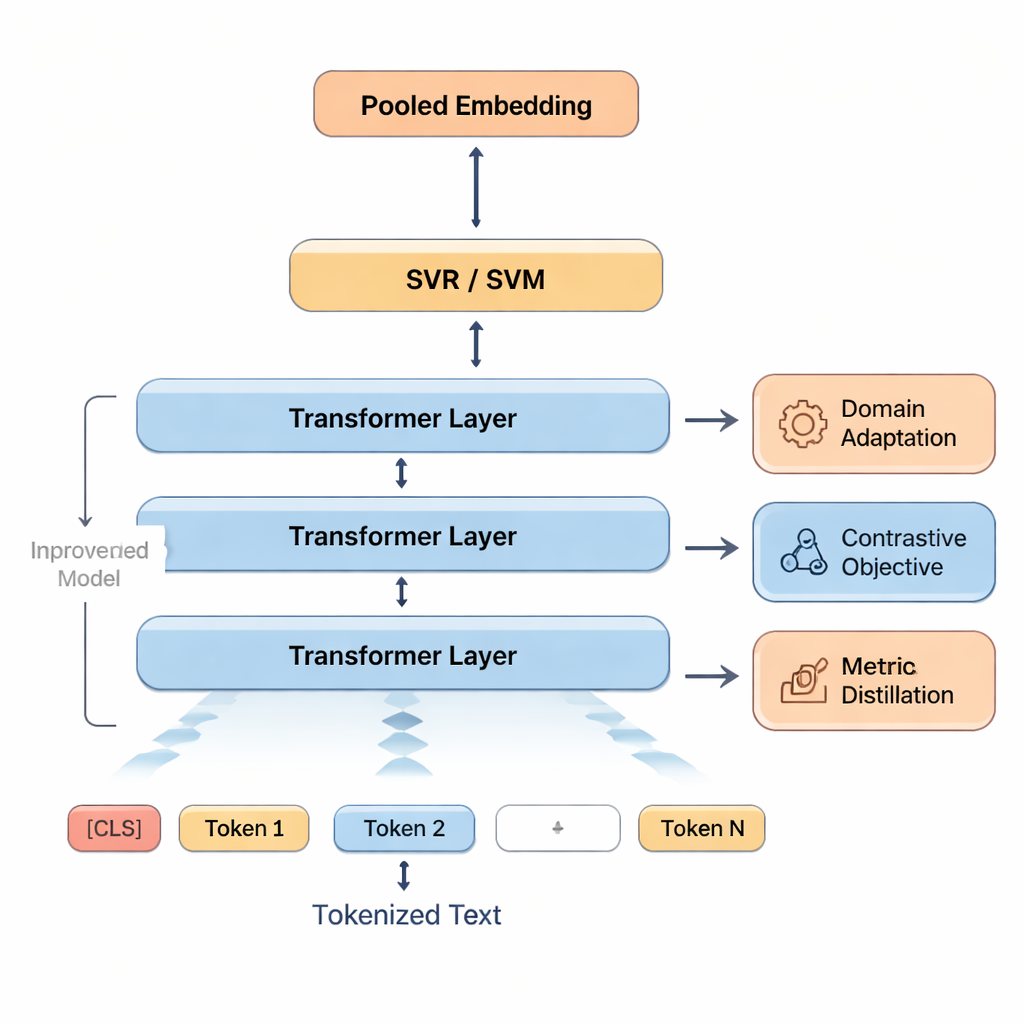
Wie das Modell getestet wurde
Die Forschenden evaluieren BERT-SVM EduScore anhand eines großen öffentlichen Datensatzes mit englisch–chinesischen maschinellen Übersetzungen, die von Menschen bewertet wurden. Zwar handelt es sich dabei nicht um Schüleraufgaben, doch ähneln die Satzbewertungen jener im Klassenzimmer und bieten einen realistischen Belastungstest. Das neue System wurde mit traditionellen wortbasierten Metriken, neueren bedeutungsbasierten Maßen und mehreren starken neuronalen Modellen verglichen. Es stimmt nicht nur enger mit menschlichen Urteilen überein — zeigt höhere Übereinstimmung und geringere durchschnittliche Fehler —, sondern läuft auch schnell genug, um auf üblicher Grafik-Hardware etwa 44 Sätze pro Sekunde zu verarbeiten. Sorgfältige Experimente zeigen, dass die Anpassung von BERT an die richtige Textart den größten Leistungszuwachs bringt, während die zusätzlichen Lerntricks stetige, kleinere Verbesserungen liefern, ohne das System merklich zu verlangsamen.
Was das für Lehrende und Lernende bedeuten könnte
Einfach gesagt zeigt die Studie, dass ein sorgfältig gestaltetes Hybrid aus Deep Learning und klassischen Methoden Übersetzungen zuverlässiger bewerten kann als bestehende automatische Werkzeuge, dabei aber schnell genug für den Echtzeit-Einsatz im Klassenzimmer bleibt. BERT-SVM EduScore ist noch kein plug-in Ersatz für menschliche Lehrkräfte: Getestet wurde es bisher nur an maschinellen Übersetzungen, nicht an echten Schülerarbeiten, und es hat keine Klassenzimmerversuche oder Fairness-Prüfungen durchlaufen. Die Ergebnisse deuten jedoch darauf hin, dass ein solches System Lehrende bald unterstützen könnte, indem es stabile Bewertungen liefert und wahrscheinliche Probleme hervorhebt — etwa falsch übersetzte Fachbegriffe oder fehlende Zahlen —, sodass sich menschliches Feedback auf tiefere, kreativere Aspekte der Übersetzung konzentrieren kann.
Zitation: Lin, C. A hybrid intelligent assessment model for English translation education with improved BERT and SVM. Sci Rep 16, 5466 (2026). https://doi.org/10.1038/s41598-026-35042-2
Schlüsselwörter: Übersetzungsbewertung, Sprachunterricht, BERT, Support-Vektor-Maschinen, Qualitätsschätzung