Clear Sky Science · de
Hybride Merkmalsauswahl mit neuem Deep-Learning-Modell zur COVID-19-Risikovorhersage
Warum die Vorhersage des COVID-19-Risikos weiterhin wichtig ist
Auch wenn die Welt lernt, mit COVID-19 zu leben, ist das Virus nicht verschwunden. Neue Varianten tauchen immer wieder auf, Krankenhäuser können nach wie vor belastet sein, und besonders gefährdete Menschen haben weiterhin ein höheres Risiko für schwere Verläufe oder Tod. Ärztinnen und Ärzte benötigen daher schnelle und verlässliche Wege, um einzuschätzen, wie wahrscheinlich es ist, dass ein infizierter Patient schwer erkrankt. Diese Arbeit stellt ein neues Computer-Modell vor, das Krankenhausdaten und fortgeschrittene künstliche Intelligenz nutzt, um das COVID-19-Risiko genauer vorherzusagen und damit Klinikerinnen und Klinikern zu helfen, zu entscheiden, wer engmaschiger überwacht, früh behandelt oder intensivmedizinisch versorgt werden sollte.
Von rohen Patientendaten zu nutzbaren Signalen
Die Studie beginnt mit einem sehr großen klinischen Datensatz: mehr als eine Million anonymisierter Patientinnen und Patienten, jeweils beschrieben durch 21 einfache, meist Ja/Nein-Merkmale wie Altersgruppe, Vorerkrankungen und weitere Risikofaktoren. Reale Krankenhausdaten sind unordentlich, deshalb ist der erste Schritt deren „Bereinigung“. Die Autorinnen und Autoren wenden einen mathematischen Trick namens Log-Skalierung an, der extreme Werte komprimiert und Cluster sehr kleiner Werte auseinanderzieht. Diese Transformation macht die Daten stabiler und leichter handhabbar für Algorithmen und verringert die Wahrscheinlichkeit, dass ungewöhnliche Zahlen oder spärliche Indikatoren das Modell in die Irre führen.
Die aussagekräftigsten Merkmale auswählen
Nicht jede erfasste Variable ist gleichermaßen nützlich für Vorhersagen, und zu viele schwache Signale können ein KI-System verunsichern. Die Forschenden führen daher eine Merkmalsauswahl durch — ein Verfahren, das weniger hilfreiche Informationen herausfiltert und die informativsten Faktoren behält. Ihr hybrider Ansatz kombiniert zwei Ideen: Eine Maßzahl bewertet, wie gut ein Merkmal Hochrisiko- von Niedrigrisikopatienten trennt, und eine andere prüft, wie stark Merkmale untereinander überlappen. Indem beide Blickwinkel auf einer gemeinsamen Skala ausbalanciert werden, bevorzugt die Methode Merkmale, die sowohl aussagekräftig als auch nicht redundant sind. Dieses Beschneiden beschleunigt das Training, reduziert Overfitting und fokussiert das Modell auf die klinisch relevantesten Muster.
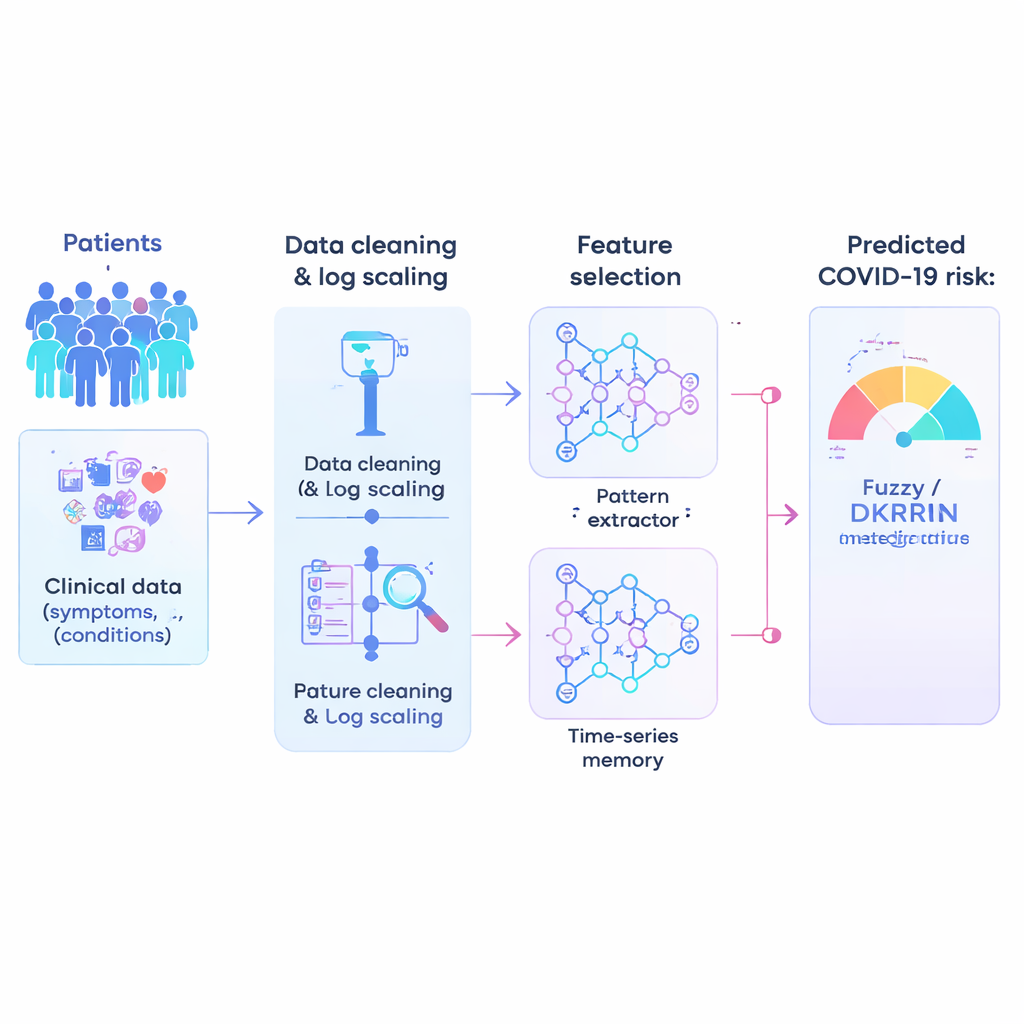
Mustererkennung mit fuzzy-basierter Schlussfolgerung verbinden
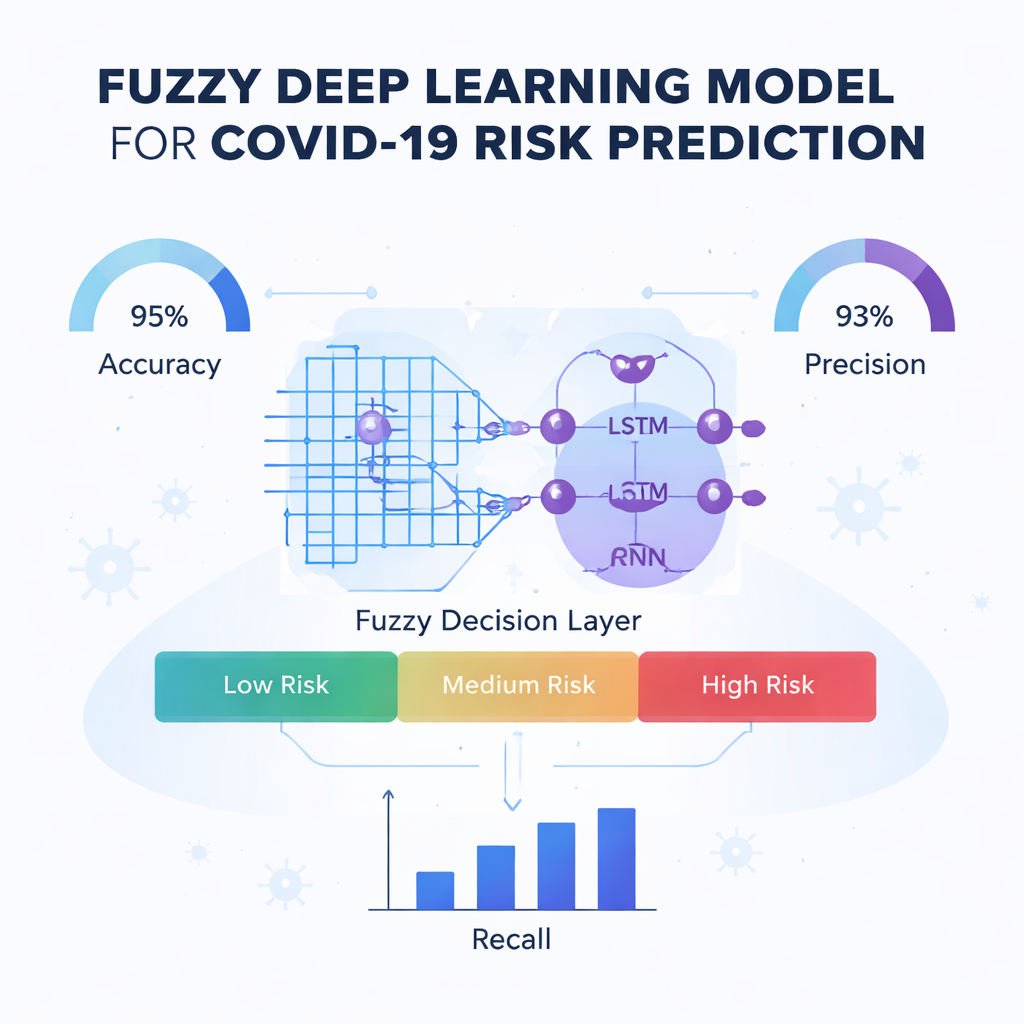
Der Kern der Arbeit ist eine neue Vorhersage-Engine namens Fuzzy-Deep Kronecker Recurrent Neural Network, oder Fuzzy-DKRNN. Sie verbindet mehrere komplementäre Techniken. Eine Komponente, ein Deep Kronecker Network, ist darauf ausgelegt, kompakte, strukturierte Muster in den klinischen Daten aufzudecken. Eine andere Komponente, ein tiefes rekurrentes Netzwerk, eignet sich gut zum Erfassen von Abhängigkeiten und Trends, etwa wenn eine Kombination von Faktoren über die Zeit das Risiko beeinflusst. Darüber legen die Autorinnen und Autoren ein Fuzzy-Logik-System. Anstatt nur harte Ja-oder-Nein-Entscheidungen zu treffen, drücken fuzzy Regeln Aussagen wie „wenn mehrere Risikoindikatoren mäßig erhöht sind, ist der Patient wahrscheinlich Hochrisiko“ aus. Jede Regel trägt einen Grad an Gewissheit, wodurch das Modell mit der Unsicherheit und den Zwischenstufen umgehen kann, die in der Medizin häufig vorkommen.
Wie gut arbeitet das Modell?
Die Autorinnen und Autoren testen ihr Fuzzy-DKRNN-Modell sorgfältig gegen mehrere moderne Alternativen, einschließlich Systemen, die auf Thorax-Röntgenbildern basieren, herkömmlicher Machine Learning-Methoden und anderen Deep-Learning-Ansätzen. Anhand standardisierter Kennzahlen wie Genauigkeit (Accuracy), Präzision, Recall und F1-Score schneidet ihre Methode konstant besser ab. In der besten Konfiguration klassifiziert das Modell insgesamt etwa 91 % der Fälle korrekt, mit hoher Fähigkeit sowohl Patienten zu erkennen, die schwer erkranken werden, als auch unnötige Alarme bei denen zu vermeiden, die es nicht tun. Diese Verbesserungen bleiben stabil, wenn die Menge an Trainingsdaten und interne Validierungseinstellungen variiert werden, was darauf hindeutet, dass der Ansatz robust ist und nicht nur auf ein spezielles Szenario feinabgestimmt wurde.
Was das für Patienten und Krankenhäuser bedeutet
Einfach gesagt zeigt diese Arbeit, dass die Kombination aus sorgfältiger Datenbereinigung, intelligenter Auswahl zentraler Risikofaktoren und einer Hybridlösung aus Deep Learning und Fuzzy-Logik verlässlichere COVID-19-Risikovorhersagen aus routinemäßigen klinischen Informationen liefern kann. Ein solches Werkzeug ersetzt nicht die Ärztinnen und Ärzte, könnte aber als Frühwarnassistent dienen — Patientinnen und Patienten markieren, die engmaschiger beobachtet werden sollten, die Verteilung knapper Ressourcen wie Intensivbetten steuern und letztlich helfen, vermeidbare Todesfälle zu reduzieren. Dieselbe Strategie ließe sich auch auf andere Erkrankungen anpassen, bei denen die frühzeitige Risikoerkennung aus komplexen klinischen Daten entscheidend ist.
Zitation: P, G.S., Kathiravan, M., Shanthi, S. et al. Hybrid feature selection with novel deep learning model for COVID-19 risk prediction. Sci Rep 16, 4106 (2026). https://doi.org/10.1038/s41598-026-35013-7
Schlüsselwörter: COVID-19-Risikovorhersage, Deep Learning, Fuzzy-Logik, klinische Entscheidungsunterstützung, medizinische KI-Modelle