Clear Sky Science · de
Eine genaue Echtzeit‑Unterwasserobjektsegmentierung mittels verbessertem Dual‑Domain YOLOv11‑UOS mit physikgeführter adaptiver Verstärkung und aufmerksamkeitserhöhender Mechanik
Tiefer tauchen mit schärferen digitalen Augen
Unsere Ozeane werden zunehmend nicht nur von Tauchern und Tauchbooten erkundet, sondern von intelligenten Kameras auf Unterwasserrobotern. Diese Kameras helfen beim Auffinden von Schiffswracks, bei der Inspektion von Offshore‑Leitungen sowie bei der Überwachung von Korallenriffen und Fischbeständen. Unterwasseraufnahmen sind jedoch oft trüb, blau‑grün und voller visueller Störeinflüsse, was es selbst für Menschen — geschweige denn für Rechner — schwierig macht, Objekte zu erkennen. Dieses Papier stellt ein neues Computer‑Vision‑System vor, das Unterwasserbilder säubert und anschließend Objekte schnell erkennt und umreißt, schnell genug, um Echtzeit‑Roboter‑Einsätze zu unterstützen.
Warum Sehen unter Wasser so schwierig ist
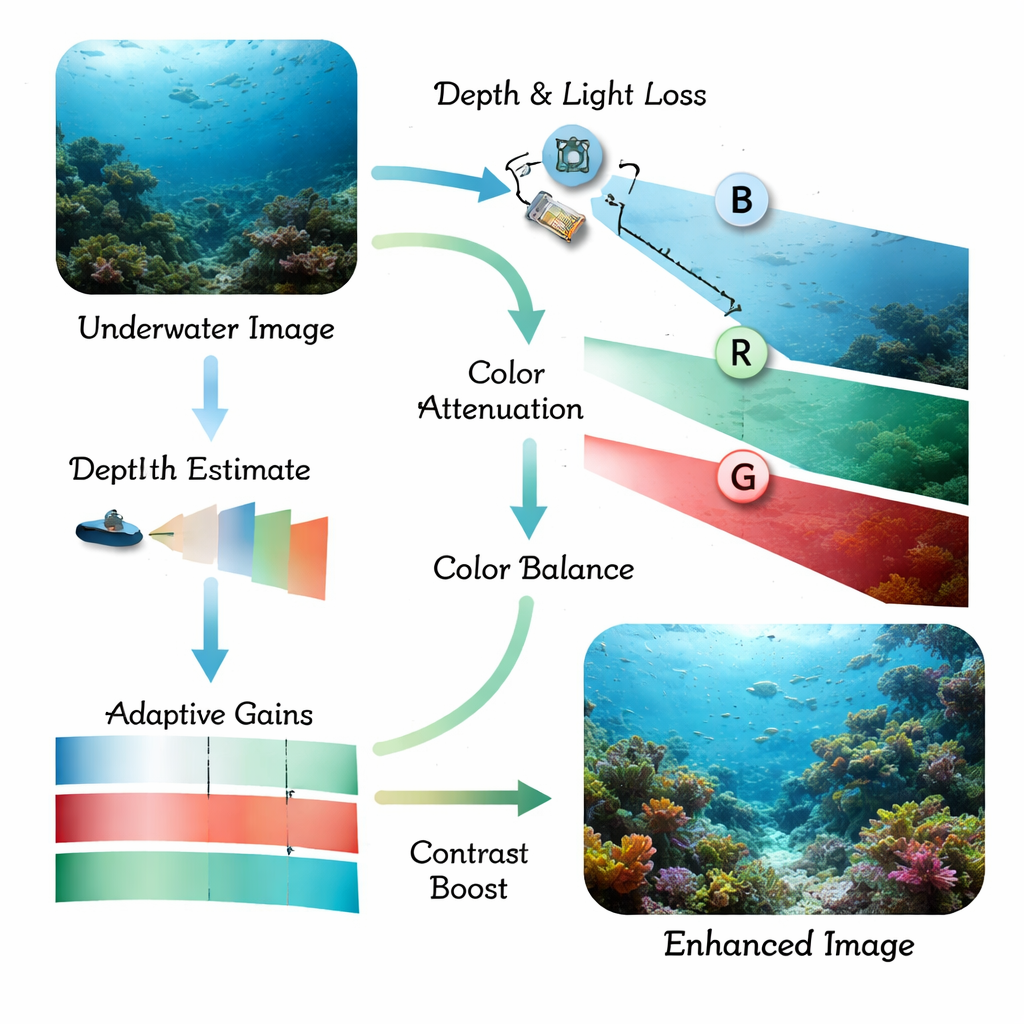
Licht verhält sich im Wasser ganz anders als in der Luft. Wenn Sonnenlicht nach unten dringt, verschwinden Rottöne zuerst, dann Grüntöne, sodass ein bläulicher Stich und matte, kontrastarme Szenen zurückbleiben. Kleinste Partikel im Wasser streuen das Licht und erzeugen Dunst, der Kanten verwischt und kleine Details verbirgt. Traditionelle Objekterkennungsprogramme und selbst moderne Deep‑Learning‑Modelle haben mit diesen verzerrten Bildern Schwierigkeiten: Fische verschmelzen mit Korallen, künstliche Strukturen gehen im Hintergrund verloren und schwach beleuchtete Szenen werden nahezu unlesbar. Frühere Arbeiten behandelten meist entweder die Bildbereinigung oder die Objekterkennung allein, was die Gesamtlösung oft zu langsam, zu fragil oder immer noch blind in besonders trübem Wasser machte.
Eine Zweistufen‑Strategie: Zuerst reinigen, dann fokussieren
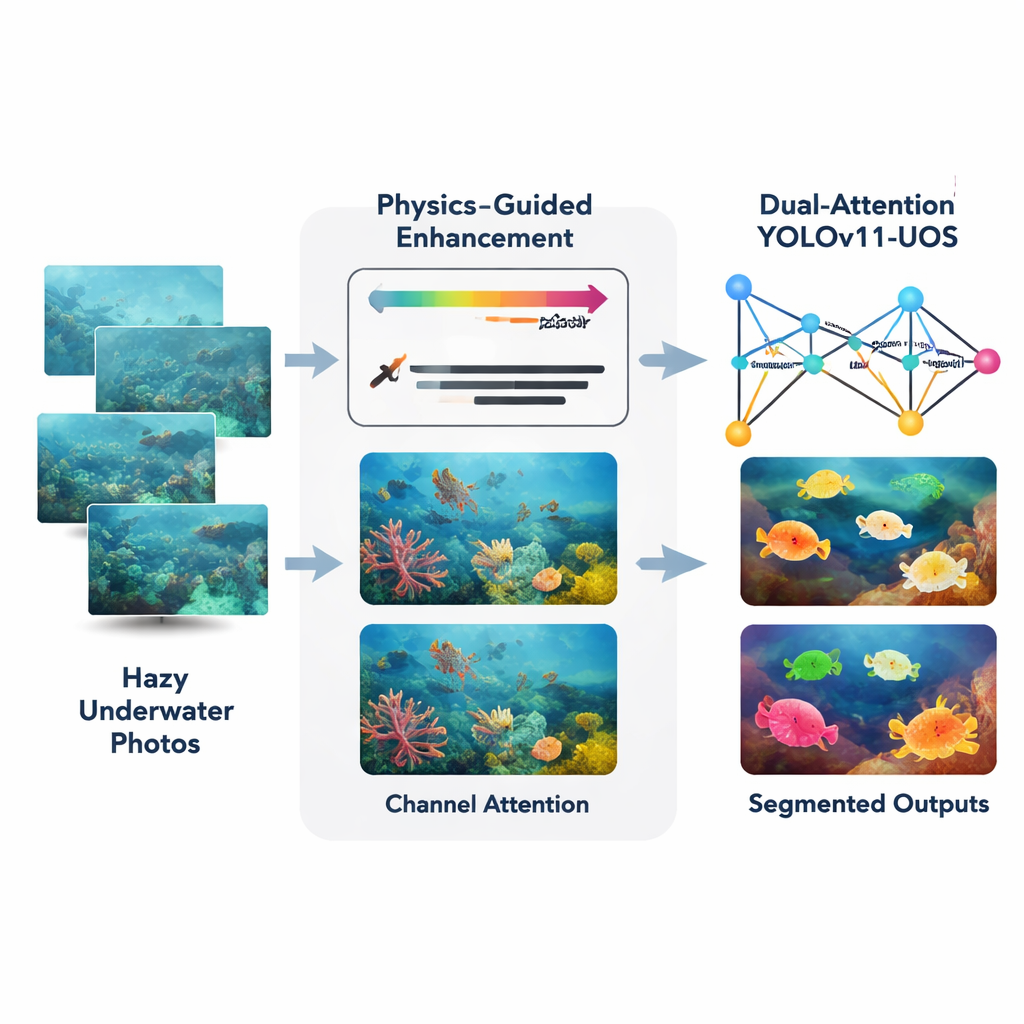
Die Autoren schlagen einen kombinierten Ansatz vor, der um einen aktuellen Echtzeit‑Detektor namens YOLOv11 herum aufgebaut ist und hier für Unterwasserszenen und Instanzsegmentierung (präzise Umrisse für jedes Objekt) angepasst wurde. Zuerst nimmt ein Frontend‑Modul namens Adaptive Physics‑Guided Enhancement rohe Unterwasserfotos auf und korrigiert sie mithilfe eines vereinfachten physikalischen Modells der Lichtabsorption und -streuung im Wasser. Es schätzt die Entfernung jedes Bildbereichs zur Kamera und kompensiert dann den stärkeren Verlust von Rot im Vergleich zu Grün und Blau. Dadurch werden natürlichere Farben wiederhergestellt und der lokale Kontrast erhöht, während ein sorgfältiger histogrammbasierter Schritt Kanten schärft, ohne Rauschen zu verstärken — auch in dunklen oder trüben Bereichen.
Dem Netzwerk beibringen, wo es hinsehen soll
Nachdem das Bild bereinigt wurde, wird es an einen erweiterten YOLOv11‑Backbone übergeben, der mit Aufmerksamkeitsmechanismen ausgestattet ist. Diese hinzugefügten Module wirken ein wenig wie ein Scheinwerfer und ein Farbfilter. Räumliche Attention veranlasst das Netzwerk, wichtigen Bereichen mehr Beachtung zu schenken — etwa der Kontur eines Fisches oder der Kante eines versunkenen Artefakts — und ablenkende Hintergründe wie Sand oder schwingende Pflanzen zu ignorieren. Kanal‑Attention passt an, wie stark das System unterschiedliche Farb‑ und Texturmuster gewichtet, sodass nützliche visuelle Hinweise hervorgehoben und irrelevante gedämpft werden. Zusammen helfen diese dualen Attention‑Stufen dem Netzwerk, schärfere interne Repräsentationen aufzubauen, bevor es entscheidet, wo sich Objekte befinden und was sie sind.
Testen in echten Ozeanen und unter harten Bedingungen
Um die praktische Leistungsfähigkeit zu prüfen, trainierten und testeten die Forscher das System an mehreren öffentlichen Unterwasser‑Bildsammlungen sowie an einem neuen, kundenspezifischen Datensatz mit über 7.000 sorgfältig beschrifteten Fotos aus Küstengewässern mit variierenden Tiefen und Trübungen. Sie maßen Standardmetriken für Erkennung und Segmentierung und verglichen ihre Methode mit weitverbreiteten Modellen wie U‑Net, DeepLab, transformerbasierten Segmentern und einem Basis‑YOLOv11‑System ohne die neuen Module. Das kombinierte Design aus Bildverbesserung und Attention steigerte die mittlere Erkennungsgenauigkeit um etwa 6,5 Prozentpunkte gegenüber dem Basis‑YOLOv11, mit deutlich saubereren Objektumrissen und weniger verpassten oder fälschlicherweise erkannten Objekten. Wichtig ist, dass das System auf einer modernen Grafikkarte immer noch mit rund 38 Bildern pro Sekunde läuft — schnell genug für nahezu echtzeitfähige Anwendungen auf robotischen Plattformen.
Was das für Meeresroboter und Forschung bedeutet
Einfach ausgedrückt zeigt die Studie, dass intelligente Vorverarbeitung und gezielte Aufmerksamkeit Computern ermöglichen, unter Wasser deutlich besser zu „sehen“. Indem zuerst ein Teil der physikalischen Effekte rückgängig gemacht wird, die Unterwasserfotos verderben, und anschließend das Erkennungsnetzwerk dazu geführt wird, sich auf die informativsten Regionen und Farben zu konzentrieren, liefert die Methode schärfere, verlässlichere Umrisse von Fischen, Korallen und künstlichen Strukturen. Das kann autonomen Unterwasserfahrzeugen helfen, sicher zu navigieren, empfindliche Meeresökosysteme zu überwachen und kritische Unterwasserinfrastruktur ohne menschliche Aufsicht zu inspizieren. Herausforderungen bestehen weiterhin in extrem schlammigem Wasser oder sehr tiefen, rotlichtarmen Szenen, aber das Framework bietet einen praktischen Schritt hin zu robuster, echtzeitfähiger Unterwassersicht, die zukünftige 3D‑Kartierung und multisensorische Erkundung des Ozeans unterstützen kann.
Zitation: Deluxni, N., Sudhakaran, P., Alroobaea, R. et al. An accurate realtime underwater object segmentation using improved dual-domain YOLOv11-UOS with physics guided adaptive enhancement and attention-boosting. Sci Rep 16, 4804 (2026). https://doi.org/10.1038/s41598-026-35001-x
Schlüsselwörter: Unterwassersicht, Meeresrobotik, Bildverbesserung, Objektsegmentierung, Computer Vision