Clear Sky Science · de
Verbesserung der geochemisch zensierten Au‑Vorhersage durch bayessche räumliche Modelle und Random Forest mit fraktalbasierter Hintergrundtrennung
Warum winzige Goldspuren wichtig sind
Wenn Geologen nach neuen Goldlagerstätten suchen, arbeiten sie häufig mit Bodenproben, die nur wenige Teile pro Milliarde des Edelmetalls enthalten. Diese extrem niedrigen Werte liegen so dicht an den Nachweisgrenzen der Laborinstrumente, dass viele Messungen schlicht als „unter Nachweisgrenze“ zurückgemeldet werden. Werden diese nahezu unsichtbaren Spuren schlecht behandelt, können vielversprechende Mineralzonen übersehen oder falsch kartiert werden. Diese Studie stellt eine intelligentere Methode vor, um Informationen aus solchen zensierten Werten zurückzugewinnen und Entdeckern zu helfen, aus begrenzten und verrauschten Daten klarere Muster im Untergrund zu erkennen.
Verborgene Signale in unvollkommenen Messungen
Boden‑ und Gesteinschemie ist ein wichtiges Werkzeug der Mineraliensuche, weil kleine chemische Veränderungen auf begrabene Erzkörper hinweisen können. Instrumente können jedoch nicht beliebig kleine Mengen messen. Für Gold in dieser Studie wurde jede Probe unterhalb von einigen Teilen pro Milliarde als zensiert betrachtet: Das Labor konnte dann nur angeben, dass der wahre Wert irgendwo unterhalb dieser Grenze liegt. Übliche Schnelllösungen ersetzen solche Ergebnisse einfach durch eine Konstante, etwa die Hälfte der Nachweisgrenze. Solch eine Praxis ebnet zwar den Umgang, glättet aber natürliche Variationen, verwässert subtile Anomalien und verzerrt Beziehungen zwischen Gold und anderen Elementen wie Kupfer. Die Autoren argumentieren, dass man, um die chemischen Fingerabdrücke der Erde wirklich zu lesen, die Unsicherheit in diesen niedrigen Werten bewahren muss, statt sie zu überschreiben.
Von der Geologiekarte zu saubererem Hintergrund
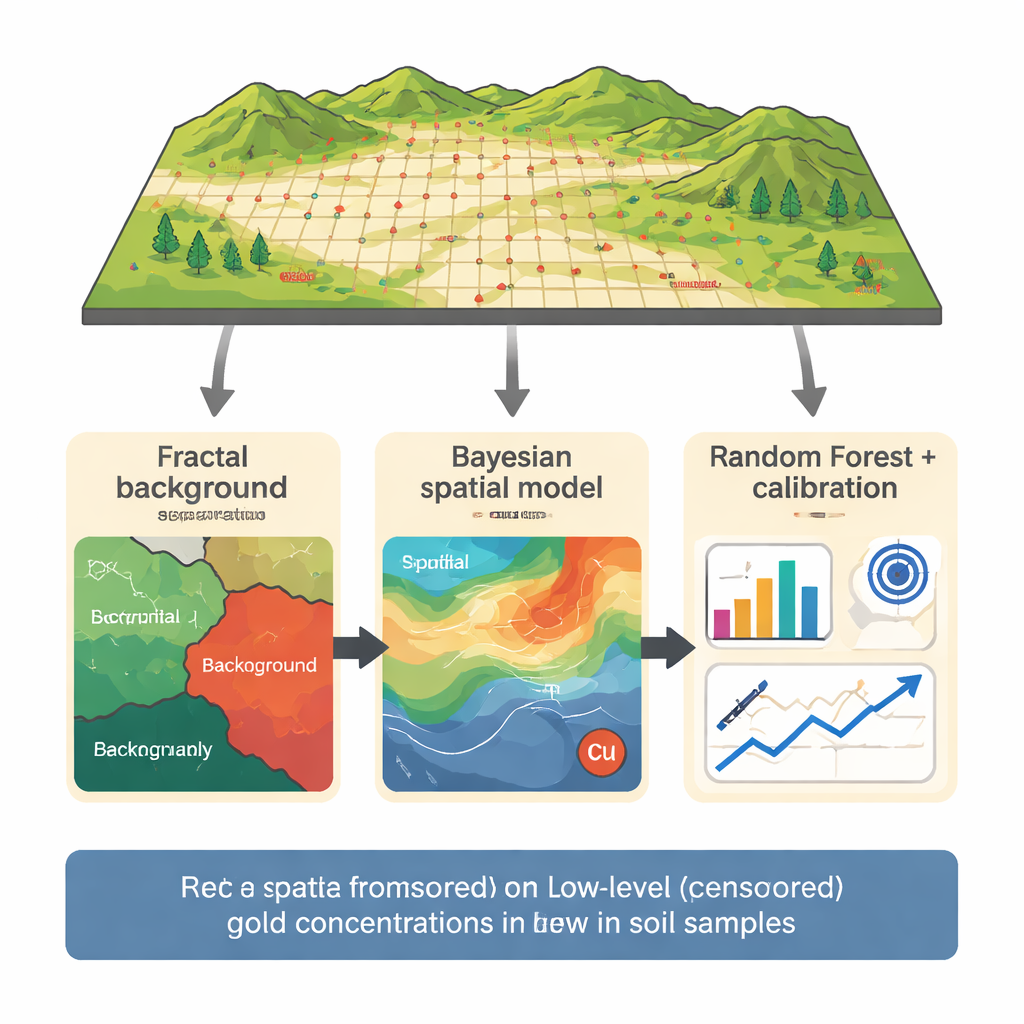
Die Untersuchung konzentriert sich auf ein Kupfer‑Gold‑Vorkommen im nördlichen Dalli‑Gebiet in Zentraliran, wo 165 Bodenproben in einem dichten Raster über einem bekannten Porphyrsystem genommen wurden. Gold wurde zusammen mit 29 weiteren Elementen gemessen; 14 Proben lagen unter einer angenommenen Nachweisgrenze von 5 Teilen pro Milliarde. Anstatt alle Daten unverarbeitet in ein Modell zu geben, verwendete das Team zunächst eine fraktale Konzentrations‑Anzahl‑Methode, um Hintergrundwerte von stärkeren Anomalien zu trennen. Durch Analyse, wie sich die Anzahl der Proben mit zunehmender Goldkonzentration in einem Log‑Log‑Diagramm ändert, identifizierten sie Schwellen, die Hintergrund, schwache Anomalien und starke Anomalien trennen. Nur die Hintergrund population — einschließlich der zensierten Werte — wurde zum Aufbau der Vorhersagemodelle verwendet, um das Risiko zu verringern, dass wenige hochgradige Proben das Lernen dominieren.
Eine probabilistische Karte, von Kupfer geleitet
Um den wahren Goldgehalt der zensierten Proben zu schätzen, wandten die Autoren anschließend ein bayessches Gaussian Random Field‑Modell an, einen probabilistischen räumlichen Ansatz. Dieses Modell behandelt die Goldkonzentration als ein über die Karte hinweg glatt variierendes Feld, beeinflusst sowohl durch den Ort als auch durch den Kupfergehalt, der in diesem Porphyrkontext stark mit Gold verknüpft ist. Anstatt für jeden zensierten Punkt eine Einzelwertschätzung zu raten, liefert das Modell eine vollständige Wahrscheinlichkeitsverteilung, die berücksichtigt, dass der wahre Wert unterhalb der Nachweisgrenze liegen muss. Das Ergebnis sind Bestschätzungen und Unsicherheitsbereiche für die 14 zensierten Proben, die konsistent mit benachbarten Messungen und mit der in den Gesteinen beobachteten Gold‑Kupfer‑Beziehung sind.
Maschinelles Lernen, dort kalibriert, wo es am wichtigsten ist
Diese probabilistischen Schätzungen flossen dann in ein Random Forest‑Modell, eine Methode des maschinellen Lernens, die viele Entscheidungsbäume kombiniert. Das Modell nutzt Gold, Kupfer, Eisen, Nickel, Titan und Bor aus der Hintergrundpopulation, um Muster zu erlernen, mit sorgfältiger Kreuzvalidierung, sodass jede Probe nur gegen Modelle getestet wird, die sie vorher nicht gesehen haben. Anfangs neigten die Vorhersagen dazu, in der Nähe der Nachweisgrenze etwas zu hoch zu liegen — ein häufiges Problem, wenn nur wenige sehr niedrige Werte vorliegen. Zur Korrektur führten die Autoren eine gezielte Kalibrierung speziell für den Bereich von 5–8 Teilen pro Milliarde durch und wandten anschließend einen einfachen Skalierungsschritt an, um sicherzustellen, dass die angepassten Vorhersagen innerhalb physikalisch sinnvollen Grenzen bleiben. Diese dreistufige Kette — fraktale Trennung, bayessche räumliche Schätzung und kalibrierter Random Forest — lieferte Vorhersagen, die die tatsächlichen niedrigen Goldwerte deutlich besser trafen als Standardansätze.
Die alten Abkürzungen schlagen
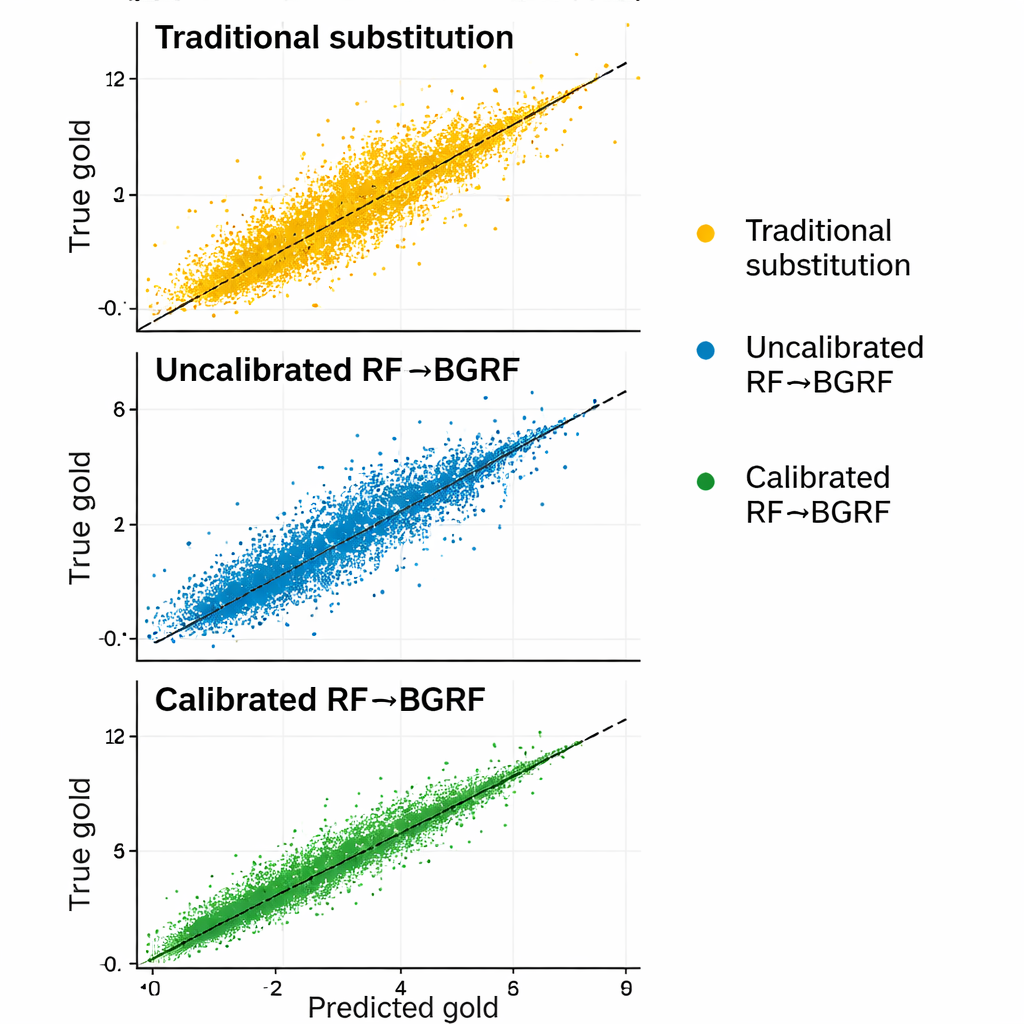
Die Studie verglich den neuen Rahmen sowohl mit einem einfachen Random Forest als auch mit zwei klassischen Substitutionsregeln, die zensierte Ergebnisse durch feste Bruchteile der Nachweisgrenze ersetzen. Über mehrere Fehlermaße hinweg war das kalibrierte und skalierte Hybridmodell am genauesten und am wenigsten verzerrt, insbesondere bei Proben nahe der Nachweisgrenze, wo kleine Fehler am meisten ins Gewicht fallen. Es bewahrte zudem realistische Variationen und hielt vernünftige Beziehungen zwischen Gold und Kupfer aufrecht, während das Ersetzen aller zensierten Werte durch eine einzige Konstante diese Struktur zerstörte. Bei einigen höherwertigen zensierten Proben war der relative Fehler der neuen Methode hunderte Male kleiner als bei traditionellen Substitutionen.
Deutlichere chemische Bilder für die Exploration
Für Nicht‑Spezialisten lautet die Schlussfolgerung, dass die Art und Weise, wie wir „unter Nachweis“‑Werte in geochemischen Daten behandeln, über Erfolg oder Misserfolg bei der Suche nach neuen Lagerstätten entscheiden kann. Anstatt Unsicherheit durch grobe Ersetzungen zu tilgen, zeigt diese Arbeit, dass die Kombination aus probabilistischer räumlicher Modellierung, maschinellem Lernen und einfacher Kalibrierung einen Großteil der verborgenen Information in niedrigen Messwerten zurückgewinnen kann. Das Ergebnis sind sauberere Karten subtiler Goldmuster, vertrauenswürdigere Anomalieerkennung und letztlich bessere Chancen, Erzvorkommen mit weniger Bohrungen und ehrlicheren Daten zu finden.
Zitation: Mahdiyanfar, H. Advancing censored geochemical Au prediction through Bayesian spatial models and Random Forest with fractal-based background separation. Sci Rep 16, 4763 (2026). https://doi.org/10.1038/s41598-026-34999-4
Schlüsselwörter: geochemische Exploration, zensierte Daten, Goldanomalien, bayessche räumliche Modellierung, Maschinelles Lernen in der Geologie