Clear Sky Science · de
Überlebensvorhersage bei verschiedenen Krebsarten mit maschinellen Lernmodellen
Warum neue Wege der Überlebensvorhersage bei Krebs wichtig sind
Krebspatienten und ihre Angehörigen stellen oft eine einfache, aber quälende Frage: „Wie lange habe ich noch?“ Ärztinnen und Ärzte versuchen, mit ihrer Erfahrung und früheren Daten zu antworten, doch bei vielen seltenen Krebsarten fehlen ausreichend ähnliche Fälle für präzise Prognosen. Diese Studie untersucht, ob moderne Computerprogramme sicher „Erfahrung ausleihen“ können — also von häufigeren Krebsarten lernen, um das Überleben bei selteneren Tumoren vorherzusagen. Das könnte mehr Patientinnen und Patienten klarere Erwartungen und besser abgestimmte Versorgung ermöglichen. 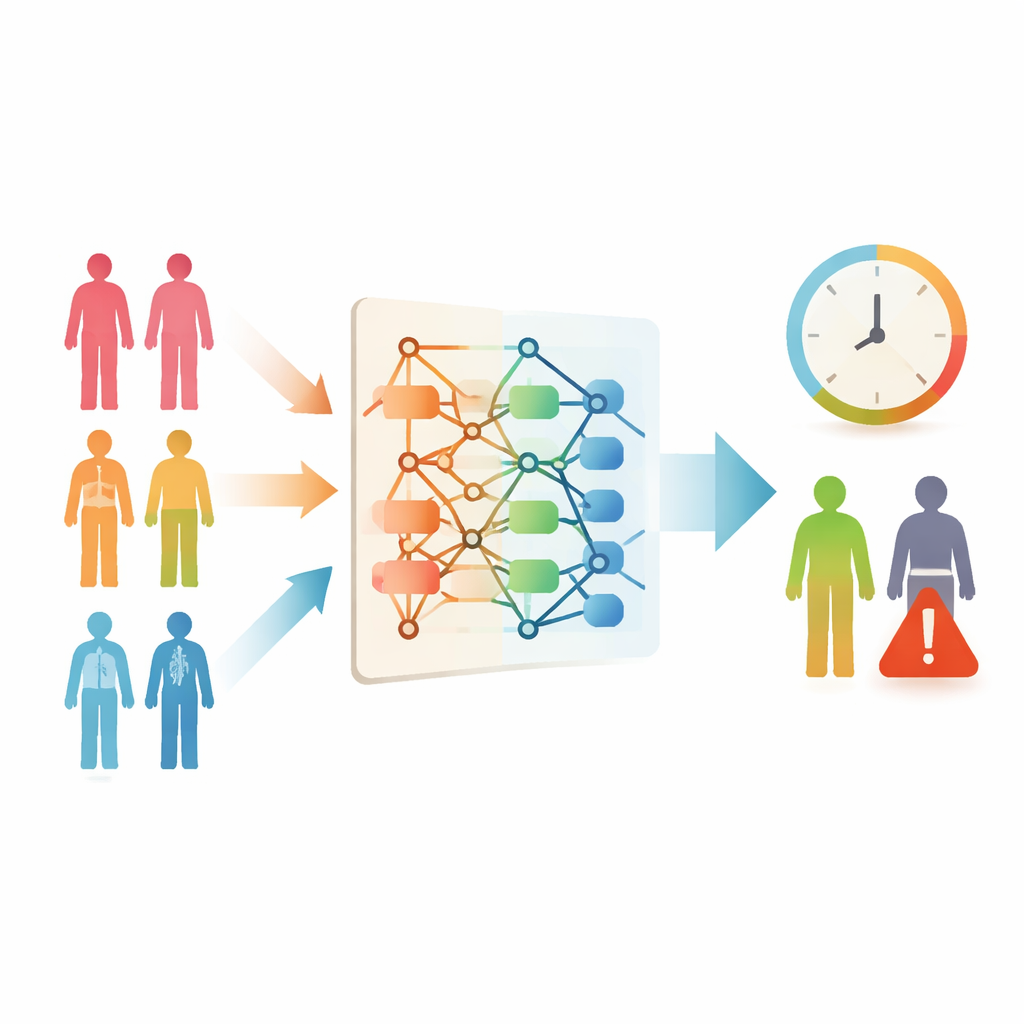
Vergangene Patientendaten als Wegweiser für künftige Versorgung
Die Forschenden arbeiteten mit einem großen Bestand realer Daten aus onkologischen Krankenhausregistern in São Paulo, Brasilien. Diese Datensätze umfassen mehr als eine Million Patientinnen und Patienten, die zwischen 2000 und 2019 behandelt wurden, und enthalten Informationen wie Alter, Tumorstadium, eingesetzte Therapien und ob die Person drei Jahre nach der Diagnose noch lebte. Der Fokus auf den Drei-Jahres-Zeitraum ermöglichte es dem Team, Krebsarten mit sehr unterschiedlichen typischen Lebensdauern zu vergleichen und zugleich extrem unausgeglichene Daten zu vermeiden, in denen nahezu alle Patientinnen und Patienten entweder überleben oder versterben.
Computern das Erkennen von Überlebensmustern beibringen
Um das Register in ein Vorhersagewerkzeug zu verwandeln, nutzten die Autorinnen und Autoren zwei verbreitete Methoden des maschinellen Lernens: XGBoost und LightGBM. Diese Verfahren versuchen nicht, die Biologie direkt zu verstehen; stattdessen durchforsten sie Tausende von Krankengeschichten, um Muster zu finden, die Merkmale wie Tumorstadium und Zeitpunkt der Behandlung mit dem späteren Überleben verknüpfen. Zunächst baute das Team „Spezialisten“-Modelle, die jeweils nur mit Daten einer Krebsart trainiert wurden, etwa Brust-, Lungen- oder Magenkrebs. Anschließend prüften sie, wie gut diese Modelle das Drei-Jahres-Überleben neuer Patienten derselben Krebsart vorhersagen, unter Nutzung gängiger Kennzahlen, die das ausgewogene Erkennen von Überlebenden und Nicht-Überlebenden bewerten.
Kann eine Krebsart die Vorhersage einer anderen unterstützen?
Kernfrage der Studie ist kühn: Kann ein auf einer Krebsart trainiertes Modell erfolgreich das Überleben bei einer anderen Krebsart vorhersagen? Zur Prüfung gruppierten die Forschenden Krebsarten auf zwei Arten: die häufigsten Krebsarten (Haut, Brust, Prostata, Kolorektal, Lunge und Gebärmutterhals) und Krebsarten des Verdauungssystems (Mundhöhle, Oropharynx, Speiseröhre, Magen, Dünndarm, Kolorektal und After). In einer ersten Phase trainierten sie für jede Krebsart separate Modelle und testeten diese an den anderen, wobei sie nur Paarungen auswählten, bei denen Überleben und Nicht-Überleben einigermaßen ausgewogen vorhergesagt wurden. In späteren Phasen verschmolzen sie Daten aus ausgewählten Krebsarten zu gemeinsamen Trainingssätzen und schufen so allgemeinere Modelle, die Muster über verwandte Tumoren hinweg nutzten. 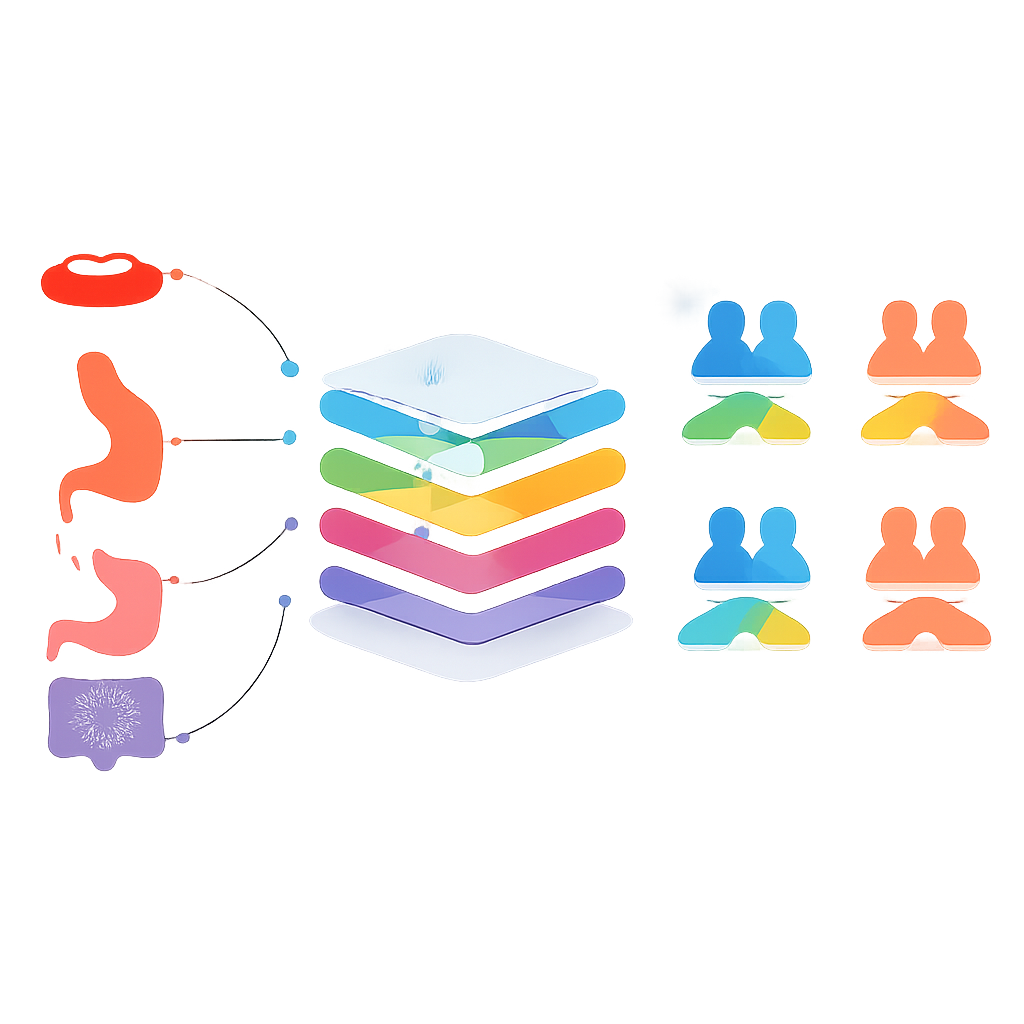
Wo modellübergreifendes Lernen nützt — und wo nicht
Bei den häufigen Krebsarten übertraf das Kombinieren von Daten aus verschiedenen Typen nicht die besten Spezialisten-Modelle. Ein einzelnes Modell, das auf allen sechs häufigen Krebsarten trainiert wurde, sagte etwa weniger genau voraus als individuell angepasste Modelle für jede Krebsart. Anders sah es bei einigen Krebsarten des Verdauungstrakts aus. Als Daten aus Mundhöhle, Speiseröhre und Magen zusammengelegt wurden, sagte das resultierende Modell das Drei-Jahres-Überleben für Magenkrebs geringfügig besser voraus als das nur mit Magen-Daten trainierte Modell, mit einer ausgewogenen Genauigkeit knapp über 80 Prozent. Statistische Tests zeigten jedoch, dass diese Verbesserung nicht klar über Zufall hinausging — das gemeinsame Modell und das Spezialisten-Modell waren im Grunde gleichwertig. Ähnliche „beinahe, aber nicht eindeutig bessere“ Ergebnisse traten bei Mundhöhle, Dünndarm und Kolorektalkarzinomen auf, häufig mit Kompromissen zwischen korrekter Identifikation von Überlebenden und Nicht-Überlebenden.
Was das für Patientinnen und Patienten mit seltenen Krebsarten bedeutet
Obwohl modellübergreifende Ansätze selten die besten krankheitsspezifischen Modelle übertrafen, kamen sie oft nahe — allein durch Nutzung von Informationen, die aus anderen Krebsarten entliehen wurden. Für seltene Krebsarten, denen große, hochwertige Datensätze fehlen, ist das ein ermutigendes Zeichen: Künftig könnten Ärztinnen und Ärzte auf Modelle zurückgreifen, die mit häufigeren Krebsarten trainiert wurden, um sinnvolle Überlebensschätzungen zu liefern, wenn spezialisierte Werkzeuge nicht verfügbar sind. Die Autorinnen und Autoren mahnen jedoch zur Vorsicht: Diese Methoden sind noch nicht einsatzreif für die klinische Routine, sie müssen in anderen Regionen getestet und mit tiefergehenden biologischen Daten kombiniert werden. Dennoch weist die Arbeit in eine Zukunft, in der kein Patient allein deshalb ohne Orientierung bleibt, weil seine Krebsart selten ist.
Zitation: Cardoso, L.B., Egydio, J.E., Toporcov, T.N. et al. Cross-cancer survival prediction using machine learning models. Sci Rep 16, 9623 (2026). https://doi.org/10.1038/s41598-025-34133-w
Schlüsselwörter: Vorhersage des Überlebens bei Krebs, maschinelles Lernen in der Onkologie, modellübergreifende Krebsanalyse, seltene Krebserkrankungen, klinische Register