Clear Sky Science · de
Berechnung des Satzähnlichkeitswerts durch hybrides Deep Learning mit besonderem Fokus auf Verneinungssätze
Warum Wortbedeutung für faire Bewertung wichtig ist
Wenn Studierende Fragen mit eigenen Worten beantworten, müssen Computer, die Lehrkräfte beim Bewerten unterstützen, mehr verstehen als nur übereinstimmende Schlüsselwörter. Ein kleines Wort wie „nicht“ kann die Bedeutung eines Satzes umkehren, und wenn automatisierte Systeme diese Umkehr übersehen, kann das zu ungerechten Noten führen. Dieser Artikel geht dieses Problem an, indem er eine neue Methode entwickelt, mit der Computer Satzbedeutungen vergleichen, wobei besondere Aufmerksamkeit darauf gelegt wird, wie Verneinungswörter die Aussage verändern.
Die Herausforderung winziger Wörter mit großer Wirkung
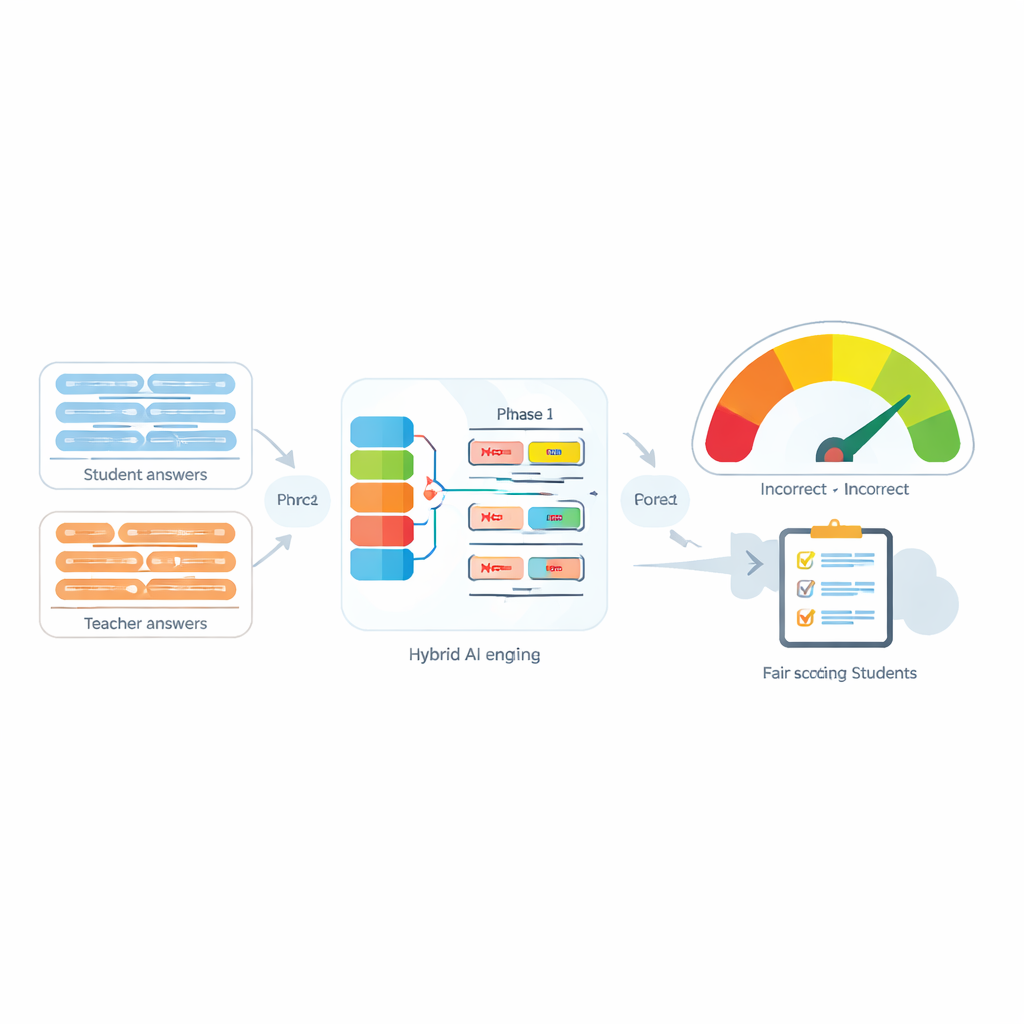
Automatische Bewertungssysteme werden zunehmend eingesetzt, um die Arbeitslast von Lehrkräften zu verringern, indem sie die Antwort eines Studierenden mit einer Musterlösung vergleichen. Viele moderne Werkzeuge tun dies, indem sie jeden Satz in einen numerischen „Fingerabdruck“ umwandeln und dann messen, wie nahe diese Fingerabdrücke beieinanderliegen. Diese Werkzeuge funktionieren recht gut, wenn keine Verneinung vorliegt, schlagen jedoch oft fehl, wenn Wörter wie „nicht“, „niemals“ oder „kein/keine“ erscheinen. Zum Beispiel können „Die Methode ist genau“ und „Die Methode ist nicht genau“ für den Computer überraschend ähnlich erscheinen, obwohl sie gegensätzliche Bedeutungen haben. Die Autoren zeigen, dass nicht nur das Vorhandensein von Verneinung, sondern auch wie viele Verneinungswörter auftreten und wo sie im Satz stehen, die beabsichtigte Bedeutung vollständig verändern können.
Aufbau eines Datensatzes, der Nuancen lehrt
Um ein System zu trainieren, das Verneinung wirklich versteht, benötigten die Autoren zunächst Daten, die diese kniffligen Fälle hervorheben. Sie erstellten das Negation-Sentence-Similarity Dataset mit 8.575 Satzpaaren aus vier Informatikdomänen: Betriebssysteme, Datenbanken, Rechnernetze und Maschinelles Lernen. Für jedes Paar vergaben Menschen einen Ähnlichkeitswert, der bereits Verneinung berücksichtigt. Der Datensatz erfasst außerdem, wie viele Verneinungswörter jeder Satz verwendet und welches Verneinungsmuster vorliegt, etwa ein einfaches „nicht“, eine gerade oder ungerade Anzahl von Verneinungen oder komplexere Fälle, in denen Verneinung mit verbindenden Wörtern wie „weil“ oder „aber“ interagiert. Diese detaillierte Kennzeichnung gibt dem Modell explizite Hinweise darauf, wie Verneinung die Bedeutung formt.
Eine hybride Engine, die viele Blickwinkel verbindet
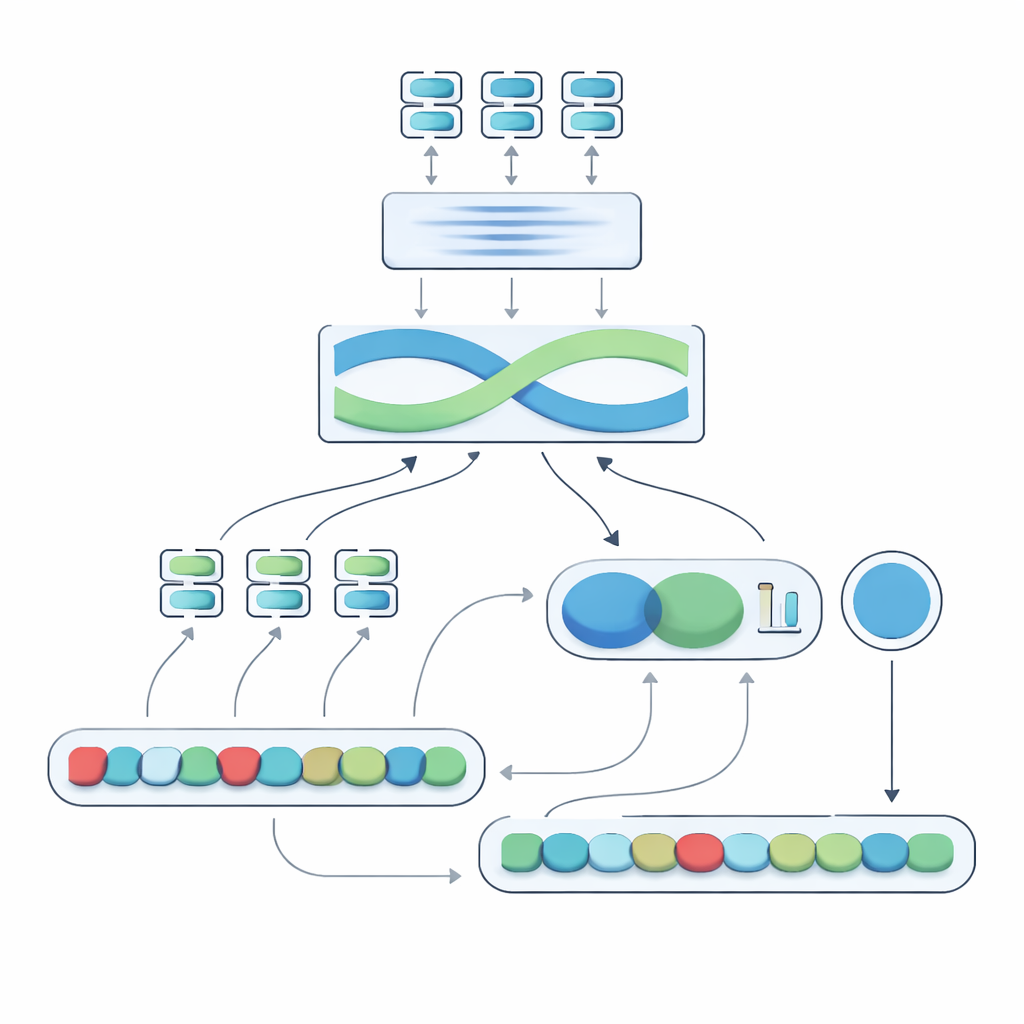
Das Herz des vorgeschlagenen Systems, genannt Negation-Aligned Similarity Scorer, ist eine zweiphasige Engine. In der ersten Phase werden die Sätze durch mehrere verschiedene Sprachmodelle geleitet, von denen jedes leicht unterschiedliche Bedeutungsaspekte erfasst. Ihre Ausgaben werden zusammengesetzt und anschließend durch ein bidirektionales rekurrentes Netzwerk geführt, das den Satz als Ganzes betrachtet und dabei Wortreihenfolge und lokalen Kontext berücksichtigt. Dadurch entsteht eine kompakte Zusammenfassung jedes Satzes, die besser auf subtile Formulierungen abgestimmt ist, einschließlich der Position von Verneinungswörtern im Verhältnis zu anderen Wörtern.
Dem Modell beibringen, die Umkehrung durch Verneinung zu spüren
In der zweiten Phase vergleicht das System die beiden Satzzusammenfassungen und fügt explizite Informationen zur Verneinung hinzu. Es betrachtet, wie stark sich die Zusammenfassungen unterscheiden, wie stark sie überlappen, und kombiniert diese Signale mit drei einfachen Merkmalen: der Differenz in der Anzahl der Verneinungswörter, ob die Sätze eine ungerade oder gerade Anzahl an Verneinungen haben (was die negative Bedeutung umkehren oder aufheben kann), und ob Verneinung ungefähr an entsprechenden Positionen erscheint. All diese Hinweise werden in einem kleinen Vorhersagenetz zusammengeführt, das einen Ähnlichkeitswert von 0 bis 100 ausgibt. End-to-End auf dem kuratierten Datensatz trainiert, wird dieser Wert empfindlich gegenüber der Art, wie Verneinung die Bedeutung umformt, statt „nicht“ nur als ein weiteres Wort zu behandeln.
Wie gut der neue Scorer in der Praxis abschneidet
Um ihren Ansatz zu testen, evaluieren die Autoren ihn sowohl auf ihrem eigenen Datensatz als auch auf einem weit verbreiteten Benchmark zur Satzähnlichkeit. Im Vergleich zu starken, auf Transformern basierenden Baselines mit Standardmethoden erreicht der neue Scorer geringere Vorhersagefehler und deutlich bessere Klassifikationsqualität, mit einem F1-Wert nahe 0,97. In sorgfältig ausgewählten Beispielen liefert er niedrige Ähnlichkeitswerte, wenn Verneinung die Bedeutung klar umkehrt, und hohe Werte, wenn doppelte Verneinung effektiv aufhebt, während konkurrierende Modelle tendenziell die Ähnlichkeit überschätzen. Eine Ablationsstudie bestätigt, dass beide Schlüsselelemente—die sequenzbewusste rekurrente Schicht und die expliziten Verneinungsmerkmale—wichtig für diesen Leistungszuwachs sind.
Was das für Studierende und künftige Werkzeuge bedeutet
Für eine interessierte Leserschaft ist die Kernaussage einfach: Die Art, wie wir „nicht“ sagen, ist entscheidend, und Maschinen können darauf trainiert werden, darauf zu achten. Durch die Kombination mehrerer Sprachmodelle, kontextueller Verarbeitung und einfacher Zählungen sowie Positionsangaben von Verneinungswörtern bietet der vorgeschlagene Scorer eine gerechtere und zuverlässigere Möglichkeit zu beurteilen, wann zwei Sätze tatsächlich dieselbe Bedeutung haben. Das kann automatisierten Bewertungssystemen helfen, gravierende Fehler zu vermeiden, etwa „ist nicht erlaubt“ als „ist erlaubt“ zu behandeln. Obwohl die Methode rechenintensiver ist und weiterhin auf technische Domänen fokussiert bleibt, weist sie den Weg zu zukünftigen Werkzeugen, die die feingliedrige Logik der Alltagssprache besser erfassen und automatisierte Sprachtechnologien klüger und vertrauenswürdiger machen.
Zitation: M, R., L, J., Ummity, S.R. et al. Computation of sentence similarity score through hybrid deep learning with a special focus on negation sentence. Sci Rep 16, 8904 (2026). https://doi.org/10.1038/s41598-025-34084-2
Schlüsselwörter: Satzähnlichkeit, Verneinung in der Sprache, automatisierte Bewertung, Verarbeitung natürlicher Sprache, Deep-Learning-Modelle