Clear Sky Science · de
Hochleistungs‑IP‑Lookup durch GPU‑Beschleunigung zur Unterstützung skalierbarer und effizienter Routing in datengetriebenen Kommunikationsnetzen
Warum schnellere Internet‑Autobahnen wichtig sind
Jedes Foto, das Sie teilen, jedes Video, das Sie streamen, und jede Nachricht, die Sie senden, muss durch ein Labyrinth digitaler Kreuzungen — Router genannt — geleitet werden. Jeder Router muss sehr schnell entscheiden, wohin er jedes Datenpaket als Nächstes schickt. Da die weltweite Internetnutzung explodiert, treffen diese Entscheidungen Milliarden von Malen pro Sekunde, und selbst winzige Verzögerungen können sich in langsamerem Surfen oder überlasteten Netzen bemerkbar machen. Dieses Paper untersucht einen neuen Weg, einen der zeitaufwendigsten Schritte in diesem Entscheidungsprozess zu beschleunigen, indem die massive parallele Rechenkraft von Grafikprozessoren genutzt wird — den gleichen Chips, die Videospiele und KI antreiben — um künftige Netze schnell und skalierbar zu halten.
Das versteckte Adressbuch des Internets
Im Kern jedes Routers liegt ein riesiges Adressbuch, die sogenannte Forwarding‑Tabelle, die IP‑Adressbereiche dem nächsten Hop auf der Reise zuordnet. Wenn ein Paket eintrifft, muss der Router nachschlagen, welcher Eintrag am besten zur Zieladresse des Pakets passt, wobei die Regel des „längsten Präfixes“ gilt: Unter allen teilweisen Adressübereinstimmungen wird die spezifischste gewählt. Traditionelle Softwaremethoden speichern diese Präfixe in baumartigen Strukturen und durchlaufen sie schrittweise. Das funktioniert, aber sobald die Tabellen auf Zehntausende oder Hunderttausende von Einträgen anwachsen, wird der Prozess langsamer und speicherintensiver — besonders auf normalen Zentralprozessoren, die nur eine begrenzte Anzahl von Aufgaben gleichzeitig bearbeiten.
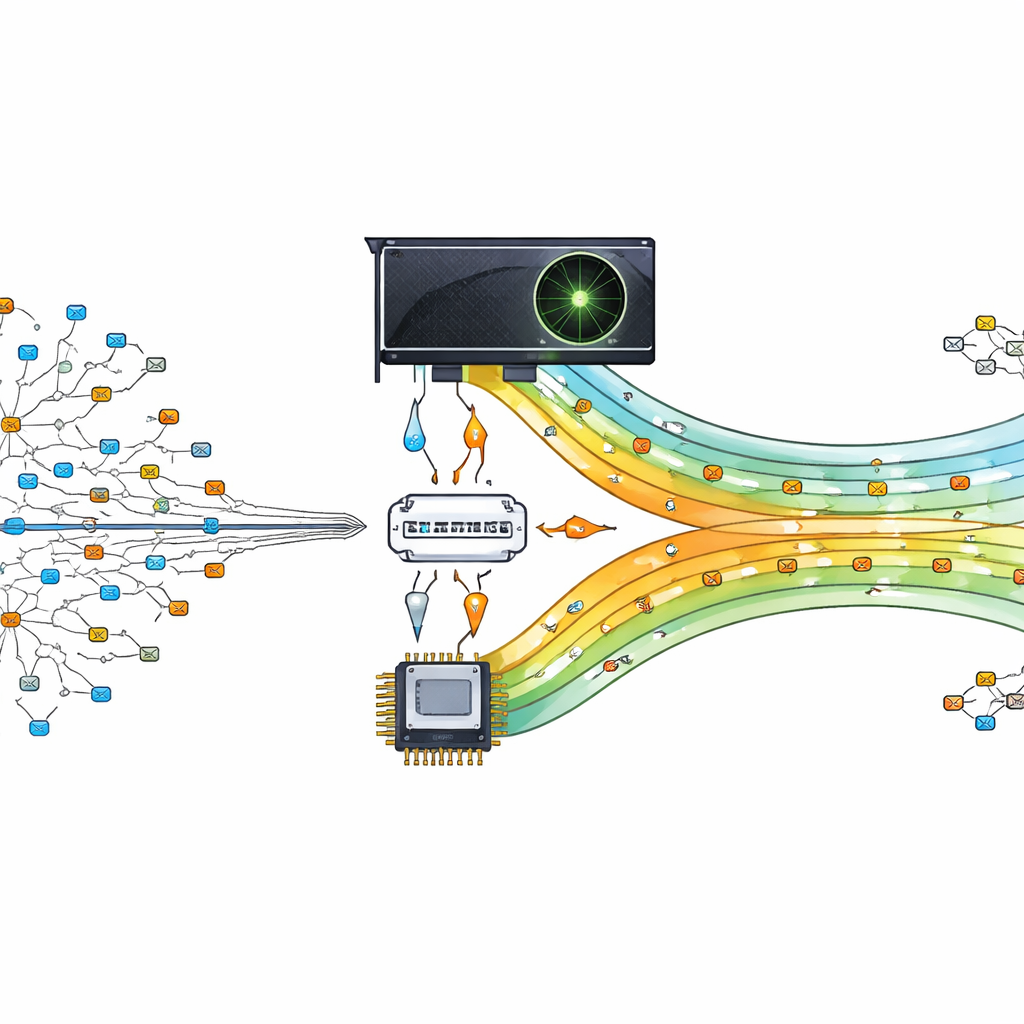
Den Grafikchip zum Verkehrspolizisten machen
Die Autoren schlagen vor, diese schwere Lookup‑Arbeit an eine GPU (Graphics Processing Unit) auszulagern, einen Chip, der dafür ausgelegt ist, Tausende winziger Aufgaben parallel auszuführen. Ihr Entwurf behandelt die GPU als Hilfseinheit für den Hauptprozessor. Der Zentralprozessor bereitet die Routing‑Tabelle auf und organisiert sie, dann sendet er kompakte Versionen der Daten an die GPU. Wenn Pakete eintreffen, werden ihre Zieladressen aufgeteilt und zur GPU geschickt, wo viele Threads gleichzeitig nach der besten Übereinstimmung suchen. Indem Hunderte oder Tausende von Lookups parallel stattfinden, kann der Router mit den modernen, datengetriebenen Kommunikationsanforderungen Schritt halten.
Adressen verkleinern, um Entscheidungen zu beschleunigen
Eine zentrale Einsicht der Arbeit ist, dass kürzere Adressen schneller zu durchsuchen sind. Statt roher IP‑Adressen komprimieren die Autoren diese mit einer verlustfreien Methode namens Huffman‑Codierung, die häufigeren Adressmustern kürzere Codes zuweist. Das verringert die durchschnittliche Anzahl von Bits pro Eintrag, senkt sowohl den Speicherbedarf als auch die Höhe der zugrundeliegenden Suchstruktur. Anschließend speichern sie die Präfixe in einem „Multibit‑Baum“, der mehrere Bits auf einmal prüft statt nur eines, was die Anzahl der erforderlichen Schritte weiter reduziert. Um sich an die Stärken der GPU anzupassen, transformieren sie diesen Baum in einfache eindimensionale Arrays und ersetzen komplizierte Pointer‑Verfolgung durch regelmäßige Index‑Berechnungen, die Tausende Threads effizient ausführen können.
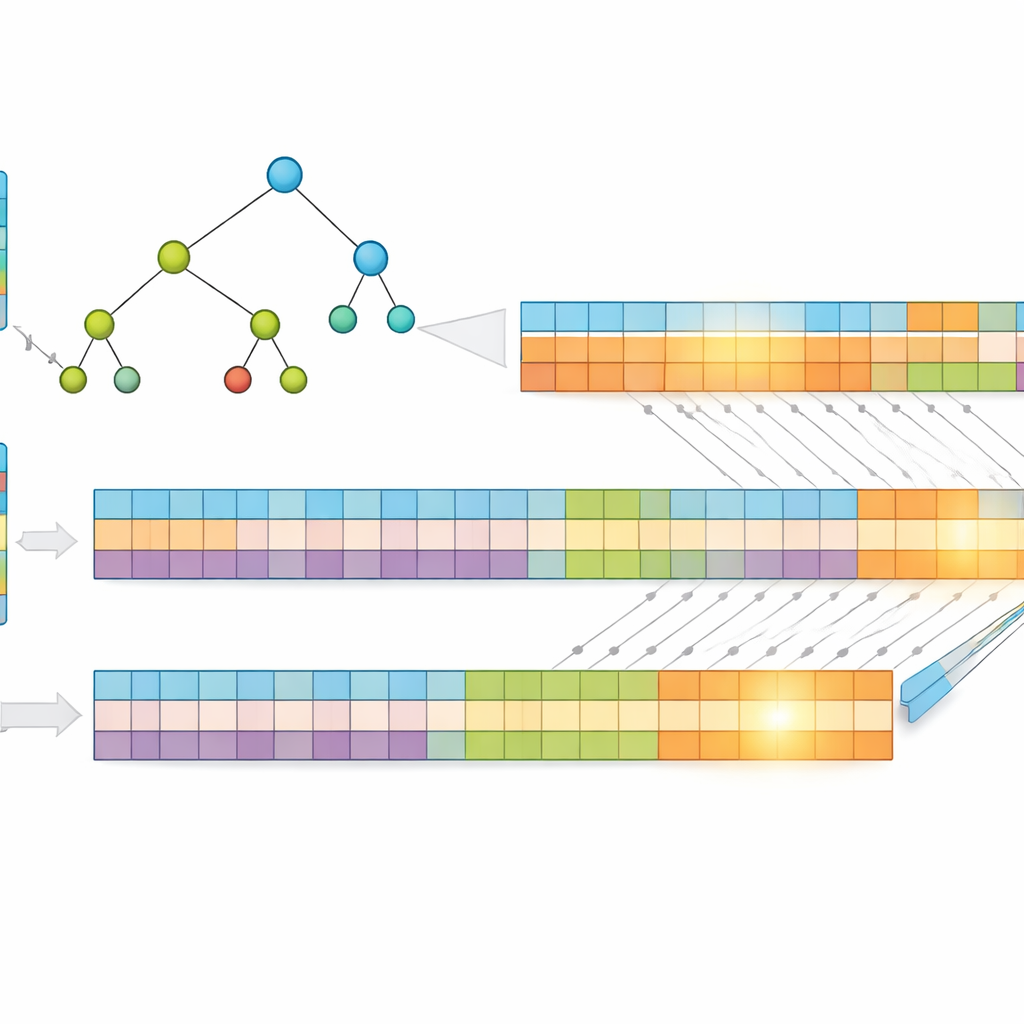
Das Problem teilen für massive Parallelität
Um die Leistung weiter zu steigern, teilen die Forscher jede komprimierte Adresse in zwei gleich große Hälften und bauen zwei separate Bäume auf — einen für die erste Hälfte, einen für die zweite. Wenn ein Paket ankommt, durchsucht die GPU beide Bäume parallel. Jede Suche liefert eine kleine Menge möglicher Treffer, und die endgültige Antwort ergibt sich aus der Schnittmenge dieser Mengen, um das gemeinsame, spezifischste Präfix zu finden. Da die Arbeit aufgeteilt und gleichzeitig verarbeitet wird, hängt die benötigte Zeit vor allem von der maximalen Präfixlänge und der Anzahl der pro Schritt betrachteten Bits ab, nicht von der Anzahl der Einträge in der Tabelle. Tests mit realen Internet‑Routingdaten zeigen, dass dieses Design eine nahezu konstante Lookup‑Zeit beibehält, selbst wenn die Tabelle wächst.
Was die Experimente zeigen
Das Team verglich ihre GPU‑basierte Methode mit verschiedenen bekannten Ansätzen, darunter klassische binäre Bäume, komprimierte Bäume und andere GPU‑beschleunigte Schemata wie Hashing und binäre Suchbäume. Bei realen Routing‑Datensätzen lieferte ihr System deutliche Verbesserungen: rund 83–91 Prozent schneller als populäre CPU‑basierte Baumverfahren und 89–97 Prozent schneller als frühere GPU‑Methoden. Die Kompression reduzierte zudem den Speicherbedarf im Mittel um etwa ein Drittel, wodurch der Druck auf den begrenzten On‑Chip‑Speicher verringert und die Suchstrukturen der GPU flacher und effizienter gehalten wurden. Wichtig ist, dass die Leistung der Methode über verschiedene Routing‑Tabellengrößen hinweg stabil blieb, was ihre Eignung für wachsende Netze unterstreicht.
Was das für Alltagsnutzer bedeutet
Für Nicht‑Spezialisten lautet die Quintessenz: Die Autoren zeigen, wie sich ein Grafikchip in einen hocheffizienten Verkehrspolizisten für Internetdaten verwandeln lässt, indem Adressinformationen intelligent verkleinert und aufgeteilt werden. Durch die Kombination von Kompression, schlaueren Baum‑Layouts und massiver paralleler Suche findet ihr Ansatz den besten Weg für jedes Paket deutlich schneller als viele vorhandene Techniken, ohne bei wachsender Größe der Internet‑Adressbücher langsamer zu werden. Zwar wird die Arbeit hauptsächlich für das heutige Adresssystem demonstriert, doch dieselben Ideen ließen sich auf künftige, größere Adressräume ausdehnen und dazu beitragen, dass zukünftige Online‑Dienste reaktionsfähig bleiben, während unser Datenbedarf weiter wächst.
Zitation: Sonai, V., Bharathi, I., Alshathri, S. et al. High performance IP lookup through GPU acceleration to support scalable and efficient routing in data driven communication networks. Sci Rep 16, 9612 (2026). https://doi.org/10.1038/s41598-025-33233-x
Schlüsselwörter: GPU‑Routing, IP‑Lookup, Netzwerkskalierbarkeit, Packet‑Forwarding, Paralleles Rechnen