Clear Sky Science · de
Ein einheitlicher Datensatz für Antikörper- und Nanobody-Design einschließlich Sequenz-, Struktur- und Bindungsaffinitätsdaten
Warum winzige Immunwerkzeuge und große Datenmengen wichtig sind
Antikörper und ihre kleineren Verwandten, Nanobodies, sind die präzisionsgelenkten Geschosse des Körpers gegen Infektionen und Krebs. Arzneimittelentwickler versuchen inzwischen, diese Moleküle am Computer zu entwerfen, ähnlich wie Ingenieure Flugzeuge konstruieren. Bis vor Kurzem jedoch waren die Rohdaten für ein solches KI-gestütztes Design – verlässliche Informationen über Antikörperbausteine, ihre Formen und wie fest sie an ihre Ziele binden – über viele inkompatible Datenbanken verstreut. Dieser Artikel stellt den Antibody and Nanobody Design Dataset (ANDD) vor, eine einheitliche, öffentliche Ressource, die Forschern saubere, umfassende Daten liefert, die sie benötigen, um die nächste Generation zielgerichteter Therapien zu entwickeln.
Vom biologischen Schloss-und-Schlüssel zum digitalen Bauplan
Antikörper sind große Y‑förmige Proteine, während Nanobodies viel kleinere, einteilige Varianten sind, die in Tieren wie Lamas und Alpakas vorkommen. Beide erkennen spezifische „Schlösser“ auf Viren, Krebszellen oder anderen krankheitsrelevanten Proteinen. Damit Computermodelle lernen können, wie diese Erkennung funktioniert, benötigen sie für viele Beispiele vier Informationsarten: die Aminosäuresequenz (die Teileliste), die 3D‑Struktur (die Form), das Antigen (das Ziel) und die Bindungsstärke (wie fest die beiden aneinander haften). Bislang erfassten die meisten Ressourcen nur ein oder zwei dieser Teile gleichzeitig, was Wissenschaftler zwang, zwischen Datenbanken zu wechseln und manuell zusammenzufügen – ein Prozess, der Fortschritt verlangsamte und Fehler einführte.
Verstreute Teile in einer organisierten Bibliothek zusammenführen
Das ANDD-Team sammelte Daten aus 15 bedeutenden Quellen, darunter spezialisierte Antikörper- und Nanobody-Datenbanken, allgemeine Proteindepots und sogar Patentschriften. Diese Rohdaten wurden anschließend durch eine sorgfältig skriptgesteuerte Pipeline verarbeitet: Herunterladen, in ein gemeinsames Schema umformatieren, Bezeichner abgleichen, Duplikate entfernen und Benennungsregeln harmonisieren. Wenn unterschiedliche Datenbanken widersprachen, wurden kuratierte Quellen und direkte Experimente priorisiert. Das Endergebnis ist eine einzelne Tabelle plus ein Satz Strukturdateien, die Sequenz-, Struktur-, Ziel- und Bindungsinformationen konsistent verknüpfen, wobei jeder Datensatz gekennzeichnet ist, sodass Nutzer genau zurückverfolgen können, woher er stammt und wie er verarbeitet wurde.
Gestufte Details für unterschiedliche Forschungsbedürfnisse
Nicht jeder Eintrag im ANDD ist gleich reichhaltig, deshalb organisierten die Autor:innen die Sammlung in Schichten zunehmender Detailtiefe. Auf der breitesten Ebene gibt es 48.683 Antikörper- und Nanobody-Einträge mit Sequenzinformationen. Eine große Teilmenge ergänzt 3D‑Strukturen, und eine kleinere Teilmenge enthält zusätzlich die Sequenz der Zielproteine. Die detaillierteste Schicht – Tausende von Einträgen – fügt gemessene oder prognostizierte Bindungsstärken hinzu. Bei Antikörpern zum Beispiel haben 18.464 Einträge Sequenzen, dieselbe Anzahl kombiniert Sequenz und Struktur, über 8.000 enthalten auch Antigensequenzen, und 7.737 besitzen vollständige Informationen zu Sequenz, Struktur, Antigen und Affinität. Eine parallele Hierarchie existiert für Nanobodies, was sowohl Experimentalisten als auch Modellbauer:innen Flexibilität gibt: Sie können große, einfache Datensätze oder kleinere, informationsreichere Teilmengen wählen.
Die Lücken bei der Bindungsstärke füllen
Die Bindungsstärke ist für das Arzneimitteldesign entscheidend, aber experimentelle Werte sind selten und uneinheitlich berichtet. Um diese Lücke zu schließen, ohne die Grenze zwischen Daten und Vorhersage zu verwischen, nutzten die Autor:innen ein spezialisiertes Deep‑Learning‑Tool, ANTIPASTI, um Bindungsstärken nur für Einträge zu schätzen, die Strukturen hatten, aber keine Messwerte. Diese 2.271 prognostizierten Werte sind deutlich gekennzeichnet und von den rund 7.000 experimentell gemessenen getrennt gehalten. Das Team überprüfte anschließend die Gesamtstimmigkeit mit einem weiteren Modell, AlphaBind, und durch den Vergleich mathematisch verwandter Bindungsmaße. Starke Korrelationen und geringe Fehler deuteten darauf hin, dass die kuratierten experimentellen Werte verlässlich sind und dass die prognostizierten Werte sinnvolle Trends zeigen, ohne als gesicherte Wahrheiten behandelt zu werden.
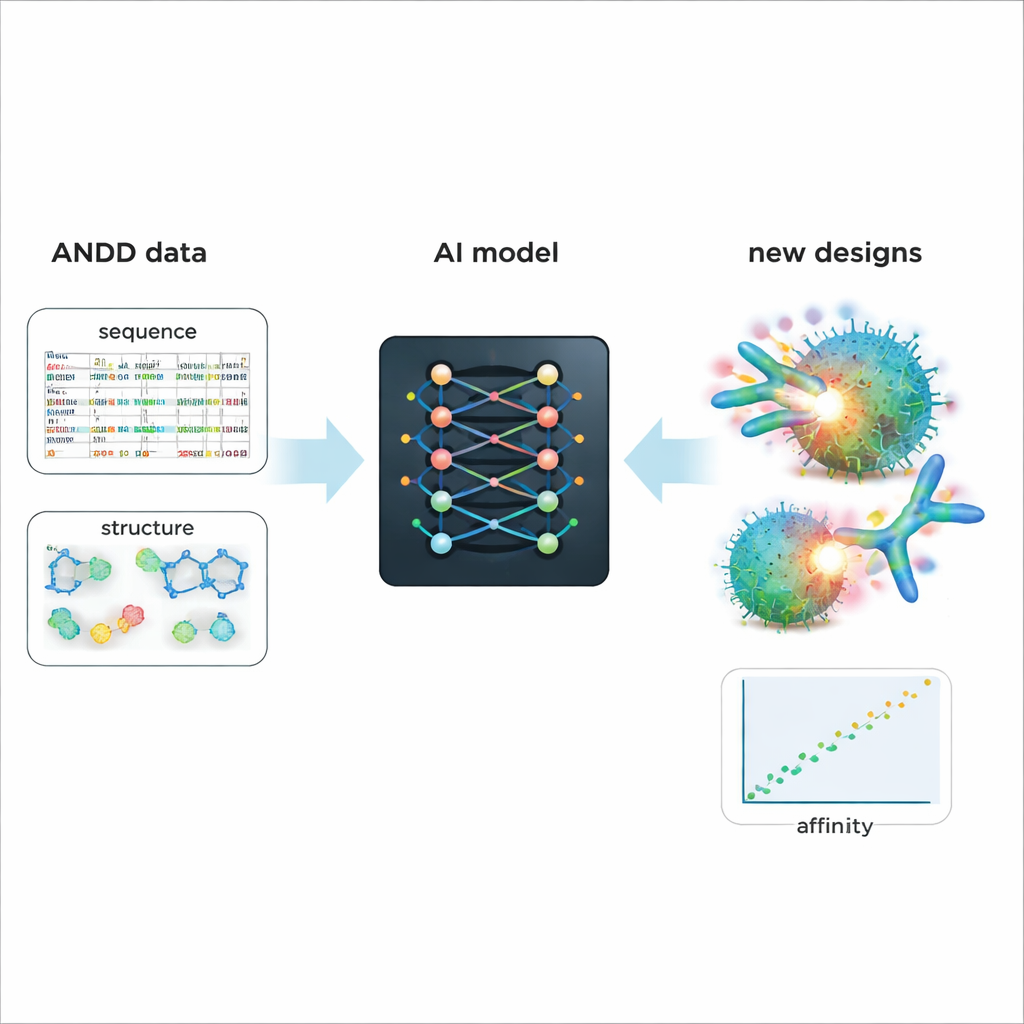
Intelligenteres Design künftiger Medikamente ermöglichen
Um den praktischen Nutzen von ANDD zu demonstrieren, verfeinerten die Autor:innen ein bestehendes generatives KI‑Modell, das Antikörper und Nanobodies entwirft. Das Training mit ANDDs kombinierter Sequenz-, Struktur-, Ziel‑ und Affinitätsinformation führte zu generierten Molekülen mit besser vorhergesagter Bindung und realistischeren Formen als bei einem Basismodell, das auf älteren, einfacheren Daten trainiert wurde. Über diese Fallstudie hinaus ist ANDD offen unter einer permissiven Lizenz verfügbar, wird mit vollständiger Dokumentation und einer reproduzierbaren Build‑Pipeline geliefert und ist so konzipiert, dass es regelmäßig aktualisiert wird. Für Nicht‑Spezialisten lautet die Kernbotschaft: ANDD verwandelt ein unordentliches Flickwerk von Antikörperdaten in eine kohärente, vertrauenswürdige Bibliothek – und bietet KI‑Tools eine deutlich bessere Ausgangsbasis für das Design präziserer, wirksamerer biologischer Wirkstoffe.
Zitation: Wu, Y., Liu, X., Hrovatin, K. et al. A Unified Dataset for Antibody and Nanobody Design Including Sequence, Structure, and Binding Affinity Data. Sci Data 13, 295 (2026). https://doi.org/10.1038/s41597-026-06878-0
Schlüsselwörter: Antikörper-Design, Nanobodies, Bindungsaffinität, biologische Therapeutika, KI-Arzneimittelforschung