Clear Sky Science · de
PreprintToPaper-Datensatz: Verknüpfung von bioRxiv-Preprints mit Zeitschriftenpublikationen
Warum frühe Forschung für uns alle wichtig ist
Lange bevor eine wissenschaftliche Entdeckung in einer glänzenden Fachzeitschrift erscheint, liegt sie oft als „Preprint“ vor – eine frühe, frei geteilte Version der Arbeit. Während der COVID‑19-Pandemie prägten diese Preprints Schlagzeilen, öffentliche Debatten und sogar Gesundheitspolitik. Dennoch war es überraschend schwierig nachzuverfolgen, welche frühen Studien später zu formalen Zeitschriftenartikeln wurden und welche es nicht taten. Dieses Papier stellt den PreprintToPaper-Datensatz vor, eine große, sorgfältig geprüfte Karte, die Life‑Science-Preprints auf dem Server bioRxiv mit ihren späteren Zeitschriftenpublikationen verbindet und damit Öffentlichkeit, Journalistinnen und Journalisten sowie Forschenden einen klareren Blick darauf gibt, wie frühe Befunde durch das wissenschaftliche System wandern.
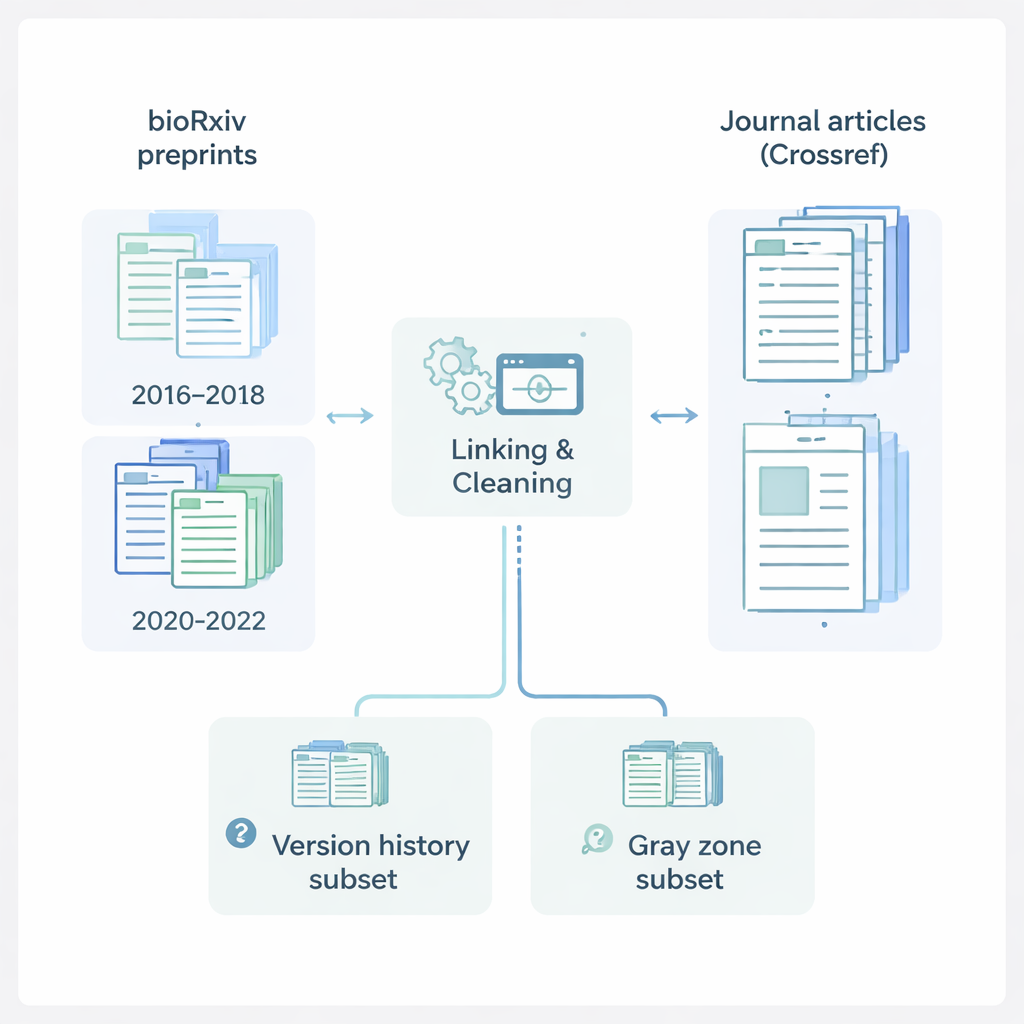
Der Weg vom Entwurf zum Artikel
Die Autorinnen und Autoren konzentrierten sich auf bioRxiv, einen großen Online-Server, auf dem Life‑Science-Forschende Preprints veröffentlichen. Sie sammelten Informationen zu 145.517 Preprints aus zwei wichtigen Zeitfenstern: 2016–2018, vor der COVID‑19-Pandemie, und 2020–2022, während der intensiven Publikationswelle der Pandemie. Für jeden Preprint protokollierten sie Angaben wie Titel, Abstract, Autorinnen und Autoren, Institutionen, Fachgebiet, Lizenz und Einreichungsdaten. Anschließend griffen sie auf Crossref zurück, ein zentrales Register für Zeitschriftenartikel, um übereinstimmende Informationen zu veröffentlichten Papern zu beziehen: Zeitschriftennamen, Publikationsdaten und vollständige Autorenlisten. Durch die Kombination dieser Quellen erstellten sie einen reichhaltigen, vereinheitlichten Datensatz, der eine Studie von ihrem ersten öffentlichen Auftreten als Preprint bis zu ihrer endgültigen Form in einer wissenschaftlichen Zeitschrift nachzeichnet.
Preprints in klare Gruppen einordnen
Um diese große Sammlung verständlich zu machen, ordnete das Team jeden Preprint einer von drei Gruppen zu. „Published“-Preprints wiesen eine klare digitale Verknüpfung von bioRxiv zu einem Zeitschriftenartikel auf. „Preprint Only“-Einträge wurden auf dem Server veröffentlicht, zeigten jedoch keine Hinweise darauf, dass sie anderswo publiziert wurden. Die interessanteste Gruppe, die „Grauzone“, enthält Fälle, die den Anschein erwecken, in einer Zeitschrift erschienen zu sein, denen auf bioRxiv jedoch ein offizieller Link fehlt. Um nachzuvollziehen, wie sich Preprints im Zeitverlauf verändern, erstellten die Forschenden außerdem eine separate Versionshistorie-Datei, die jede verfügbare Version für Preprints auflistet, die eine Originalversion und mindestens ein späteres Update hatten. So können andere untersuchen, wie sich Titel, Autorenlisten und andere Details zwischen dem ersten Entwurf und der letzten Preprint-Version entwickeln.
Versteckte Übereinstimmungen erkennen und manuell prüfen
Viele Preprints, die tatsächlich veröffentlicht wurden, erhalten nie einen entsprechenden Rücklink auf bioRxiv, was für alle, die wissenschaftliche Leistungen nachverfolgen wollen, blinde Flecken schafft. Um diese fehlenden Verbindungen aufzudecken, verglichen die Autorinnen und Autoren Preprint-Titel und Autorenlisten mit den Crossref-Zeitschriftenaufzeichnungen. Sie verwendeten einen Ähnlichkeitswert zwischen 0 und 1, um zu messen, wie eng zwei Titel übereinstimmen; potenzielle Grauzonen-Links benötigten einen Wert von mindestens 0,75. Diese Kandidaten verfeinerten sie anschließend mit autorenbasierten Kriterien: wie stark sich die Autorenzahlen unterschieden und wie ähnlich die Namen erschienen. Um zu prüfen, ob diese automatisierten Regeln verlässlich sind, untersuchten zwei menschliche Annotatorinnen beziehungsweise Annotatoren manuell 299 Grenzfälle. Ihre Bewertungen stimmten stark überein, und ein statistisches Modell zeigte, dass eine angenommene Verknüpfung sehr wahrscheinlich echt ist, wenn die Autorenlisten gut übereinstimmen.
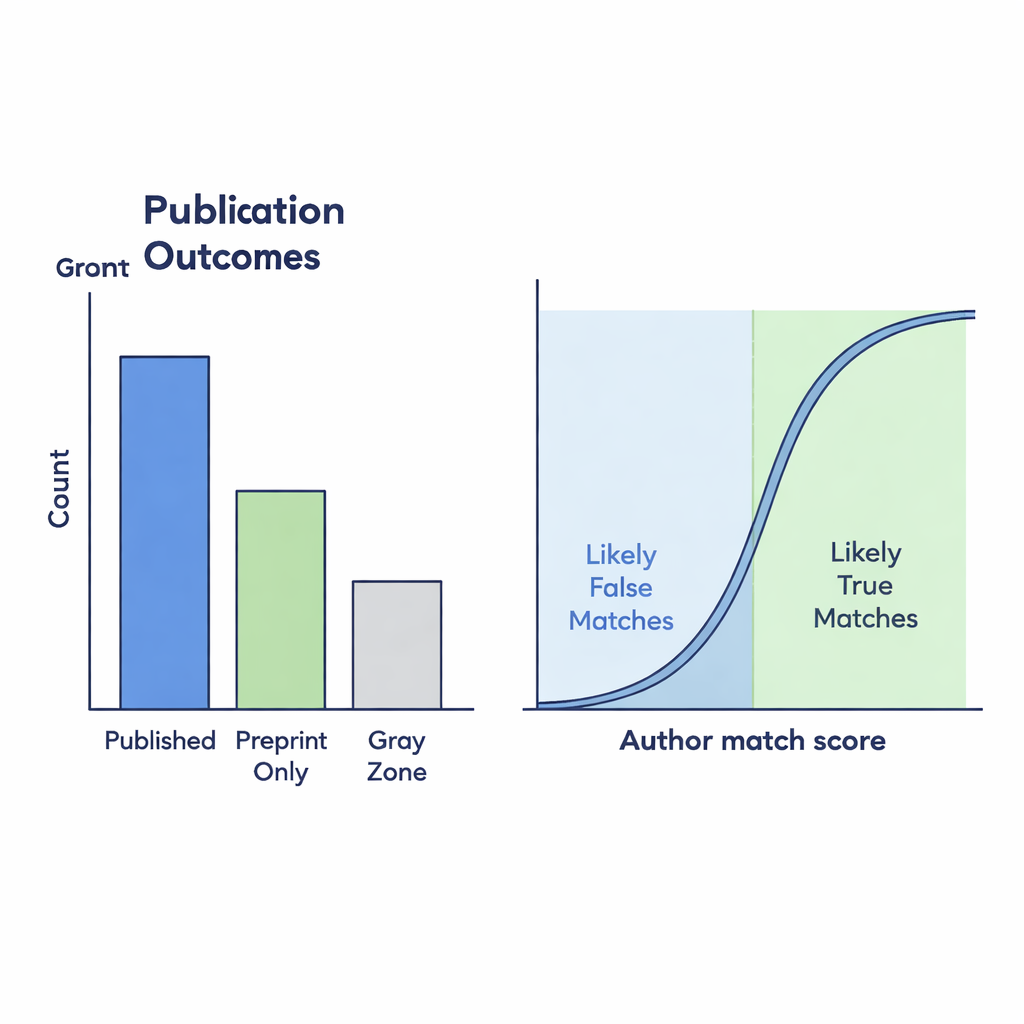
Was die Zahlen über wissenschaftliche Produktion verraten
Der fertige Datensatz zeigt, wie sich Preprint- und Publikationsmuster vor und während der Pandemie verschoben haben. Insgesamt enthält er über 90.000 klar veröffentlichte Preprints, mehr als 35.000, die offenbar nur auf dem Server verbleiben, und etwa 19.000 Grauzonen-Fälle, bei denen die Verbindung zu einem Zeitschriftenartikel detektivische Arbeit erforderte. Zählt man nur die offiziell verlinkte „Published“-Gruppe, scheint ein deutlich kleinerer Anteil der Preprints im Laufe der Zeit in Zeitschriftenartikel zu münden. Werden jedoch wahrscheinliche Grauzonen-Übereinstimmungen – jene mit starker Autorenähnlichkeit – einbezogen, fällt der Rückgang der Publikationsraten deutlich weniger dramatisch aus. Das legt nahe, dass fehlende Links in der zugrundeliegenden Infrastruktur uns hinsichtlich der Veränderungen in der wissenschaftlichen Landschaft in die Irre führen können.
Warum diese Ressource über Fachkreise hinaus nützlich ist
Für Nicht‑Spezialisten lautet die Kernbotschaft, dass frühe wissenschaftliche Ergebnisse nicht einfach in einer Blackbox verschwinden. Mit dem PreprintToPaper-Datensatz wird es möglich zu sehen, welche schnell veröffentlichten Befunde letztlich die Begutachtung überstehen, wie lange dieser Weg dauert und welche Arten von Studien die Preprint‑Phase nie verlassen. Entscheidungsträgerinnen und -träger können diese Informationen nutzen, um zu beurteilen, wie gut Open‑Science-Praktiken funktionieren; Journalistinnen und Journalisten können besser einschätzen, wie belastbar ein Ergebnis ist; und Forschende können Werkzeuge bauen, die den überwältigenden Strom an Artikeln filtern und zusammenfassen. Kurz: Dieser Datensatz verwandelt eine chaotische Flut früher Forschung in eine besser nachverfolgbare, verantwortungsfähigere Aufzeichnung darüber, wie Ideen vom ersten Posting zur ausgereiften Veröffentlichung gelangen.
Zitation: Badalova, F., Sienkiewicz, J. & Mayr, P. PreprintToPaper dataset: connecting bioRxiv preprints with journal publications. Sci Data 13, 301 (2026). https://doi.org/10.1038/s41597-026-06867-3
Schlüsselwörter: Preprints, wissenschaftliches Publizieren, Open Science, COVID-19-Forschung, Bibliometrie