Clear Sky Science · de
Multi-TPC: Ein multimodales Datenset für Drei-Personen-Gespräche mit Sprache, Bewegung und Blick
Warum es wichtig ist, wie wir uns bewegen und wohin wir schauen, wenn wir sprechen
Wenn Menschen von Angesicht zu Angesicht miteinander sprechen, tauschen sie weit mehr als nur Worte aus. Wir lehnen uns vor, nicken, werfen einander Blicke und machen an genau den richtigen Stellen Pausen. Diese subtilen Bewegungen werden noch wichtiger, wenn drei Personen zusammen sprechen, weil Aufmerksamkeit und Redebeiträge ständig wechseln. Bislang fehlten Wissenschaftlern und Ingenieurinnen jedoch hochwertige Daten, die zeigen, wie Sprache, Körperbewegung und Blick zusammenwirken in Gesprächen in kleinen Gruppen. Dieses Paper stellt ein neues Datenset vor, das diese Lücke schließen und helfen soll, natürlichere virtuelle Assistenten, soziale Roboter und Werkzeuge zur Untersuchung alltäglicher menschlicher Interaktion zu entwickeln.
Ein neues Fenster in Drei-Personen-Gespräche
Die Autorinnen und Autoren präsentieren Multi-TPC, eine öffentlich verfügbare Sammlung von Drei‑Personen‑Gesprächen, die im Labor mit Motion-Capture, Eye-Tracking und individuellen Mikrofonen aufgezeichnet wurden. Anders als viele frühere Ressourcen, die sich auf einen einzelnen Sprecher oder auf Gespräche zwischen nur zwei Personen konzentrieren, erfasst Multi-TPC spontane Diskussionen unter drei Fremden, die in einem Dreieck stehen und über beliebige Themen sprechen. Enthalten sind über 5,3 Stunden Aufnahmen von 21 jungen Erwachsenen, verteilt auf 24 Sessions. Für jeden Moment in diesen Gesprächen liefert das Datenset detaillierte Informationen darüber, wie jede Person spricht, ihren Körper bewegt und wohin sie ihren Blick richtet.
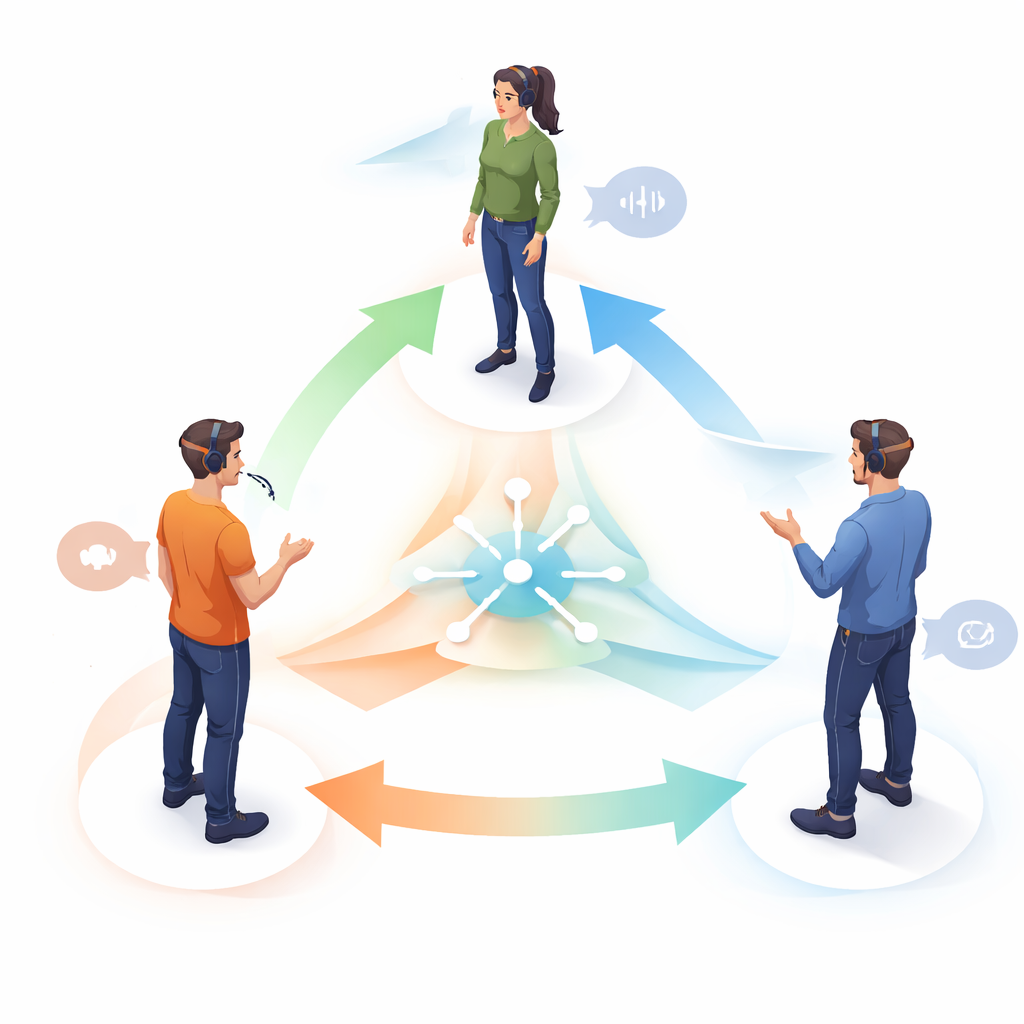
Wie die Gespräche aufgezeichnet wurden
Für den Aufbau dieses Datensets entwickelte das Team eine hybride Aufnahmearrangement. Jede Teilnehmerin und jeder Teilnehmer trug einen Ganzkörper‑Motion‑Capture‑Anzug mit reflektierenden Markern, sodass ein Array aus acht Kameras Haltung, Kopfbewegung und Gestik in drei Dimensionen verfolgen konnte. Leichte Eye‑Tracking‑Brillen, ähnlich im Tragegefühl wie normale Brillen, maßen, wohin jede Person im Sichtfeld schaute. Drahtlose Mikrofone, am Hals befestigt, zeichneten die Stimme jeder Person auf einer separaten Audiospur auf. Vor der Aufnahme wurden die Teilnehmenden im System kalibriert und angewiesen, an festen Positionen zu bleiben, die ein gleichseitiges Dreieck mit etwa einem Meter Kantenlänge bildeten. Eine Klappe, sichtbar für Kameras, Eye‑Tracker und Mikrofone, lieferte ein präzises Signal zur zeitlichen Ausrichtung aller Geräte, sodass Bewegung, Blick und Sprache Bild für Bild synchronisiert werden konnten.
Bereinigung, Organisation und Anreicherung der Daten
Das Sammeln roher Signale war nur der erste Schritt. Die Forschenden bearbeiteten die Bewegungsdaten sorgfältig, markierten alle Marker und füllten kleine Lücken mittels mathematischer Interpolation, wobei sie benachbarte Markerpositionen überkreuz überprüften. Die Audioaufnahmen wurden mit Rauschreduktionsverfahren bereinigt und dann in Spracherkennungssoftware eingespeist, um Wort‑für‑Wort‑Transkripte zu erzeugen, die anschließend manuell korrigiert wurden. In Kamerapixeln gemessene Blickpunkte wurden in 3D‑Winkel umgerechnet, die zeigen, wohin jede Person im Raum blickte. Alle Signale wurden auf 60 Bilder pro Sekunde heruntergesampelt und synchronisiert und dann in einfachen, offenen Formaten gespeichert. Das fertige Datenset ist nach Modalitäten organisiert — Bewegung, Blick, Audio, Wörter und prosodische Merkmale wie Lautstärke und Tonhöhe — mit klaren Dateibenennungsregeln, so dass Forschende jeden Zeitpunkt leicht über alle drei Teilnehmenden hinweg nachvollziehen können.
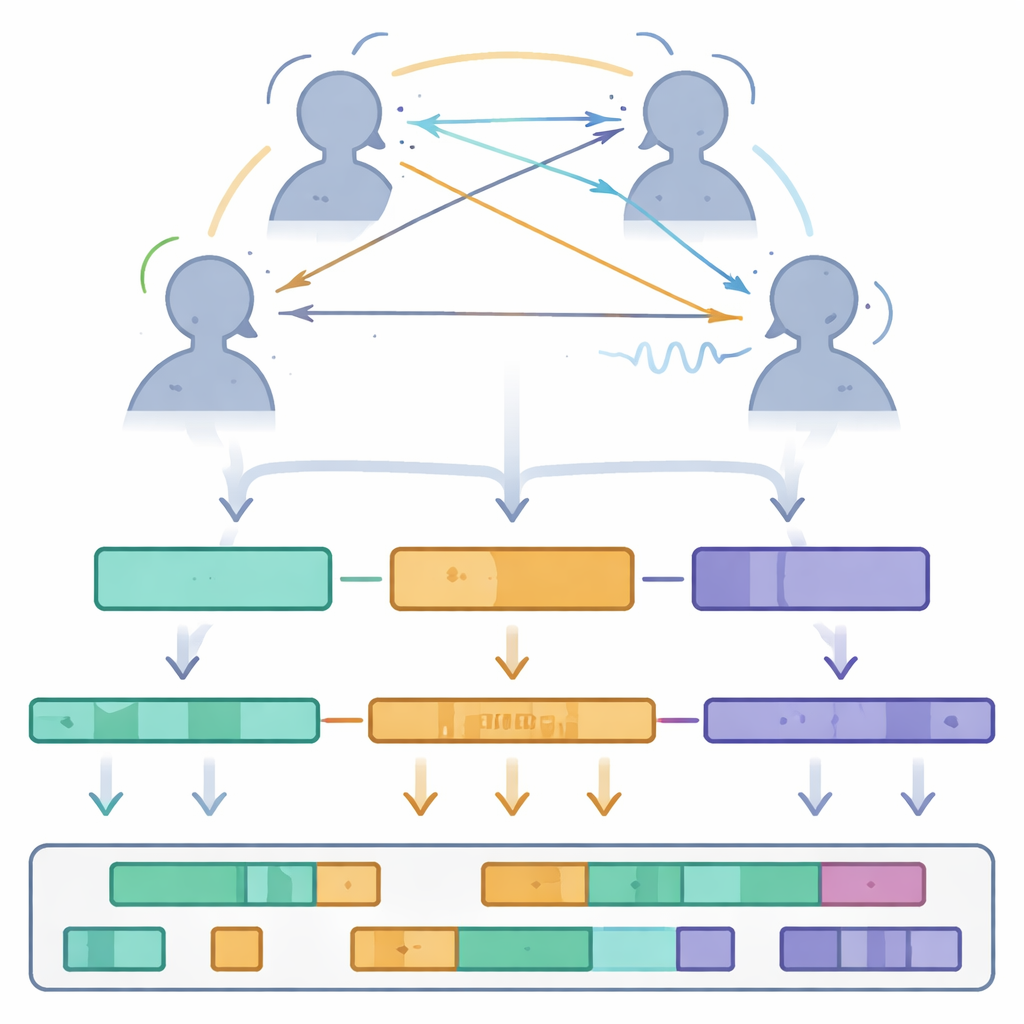
Was das Datenset über Gruppengespräche verrät
Mithilfe von Multi‑TPC führten die Autorinnen und Autoren eine erste statistische Bestandsaufnahme darüber durch, wie Drei‑Personen‑Gespräche ablaufen. Sie maßen Redebeiträge und Stillephasen und fanden heraus, dass ein typischer Redebeitrag etwa 2,7 Sekunden dauert, getrennt durch Pausen von knapp über einer Sekunde. Sie untersuchten auch Kopfnicken und -schütteln als Form des Zuhörerfeedbacks und detektierten im Schnitt ungefähr ein Viertel Nicken oder Schütteln pro Sekunde — ein Hinweis darauf, dass Zuhörende kontinuierlich Aufmerksamkeit und Haltung signalisieren, ohne ein Wort zu sagen. Die Blickanalyse zeigte, dass Menschen selten über längere Zeit direkt auf das Gesicht eines anderen fixieren. Stattdessen schauen sie oft leicht abgewandt, und ihre Blickmuster verändern sich je nachdem, wer spricht, ob es eine Pause gibt oder ob mehr als eine Person gleichzeitig spricht. Während überlappender Sprache wird der Blick der Teilnehmenden gleichmäßiger verteilt oder driftet von beiden Partnern weg, was auf Unsicherheit darüber hindeutet, wer gerade das Gesprächsrecht hat.
Warum diese Ressource für zukünftige Technologie wichtig ist
Indem all diese Informationsschichten in ein gut dokumentiertes, teilbares Datenset verpackt werden, bietet Multi‑TPC eine neue Grundlage, um zu untersuchen, wie kleine Gruppen Sprechwechsel, Aufmerksamkeit und Feedback sowohl durch Worte als auch durch Bewegung steuern. Für allgemein Interessierte lautet die Erkenntnis: Der Tanz der Konversation — wer wann spricht, wer wohin schaut und wie subtile Nicken den Gesprächsfluss formen — ist nun in feinen Details erfasst. Für Wissenschaftlerinnen, Wissenschaftler und Entwicklerinnen öffnet dies die Tür, virtuelle Figuren und soziale Roboter zu bauen, die in Gruppensituationen menschlicher reagieren, sowie zu vertieften Studien darüber, wie wir uns über Stimme, Körper und Blick koordinieren.
Zitation: Lee, MC., Deng, Z. Multi-TPC: A Multimodal Dataset for Three-Party Conversations with Speech, Motion, and Gaze. Sci Data 13, 429 (2026). https://doi.org/10.1038/s41597-026-06819-x
Schlüsselwörter: multimodale Konversation, Gestik und Blick, Datensatz zu sozialer Interaktion, Sprechwechsel, virtuelle Agenten