Clear Sky Science · de
Ein groß angelegtes Peripher-Blut-Zell-Datensatz für automatisierte hämatologische Analysen
Warum Bilder von Blutzellen wichtig sind
Jeder routinemäßige Bluttest verbirgt eine mikroskopische Welt von Zellen, die Infektionen, Anämie oder sogar Blutkrebserkrankungen lange bevor Symptome sichtbar werden, aufdecken kann. Ärztinnen und Ärzte betrachten diese Zellen traditionell mit bloßem Auge unter dem Mikroskop – ein sorgfältiges, aber zeitaufwändiges Handwerk. Diese Studie stellt eine sehr große, sorgfältig annotierte Sammlung von Blutzellbildern vor, die darauf abzielt, Computern das automatische Erkennen dieser Zellen beizubringen. Ziel ist es, künftige Bluttests schneller, konsistenter und breiter zugänglich zu machen, indem künstlicher Intelligenz die visuelle Erfahrung vermittelt wird, die sie benötigt, um Blutausstriche präzise zu lesen.
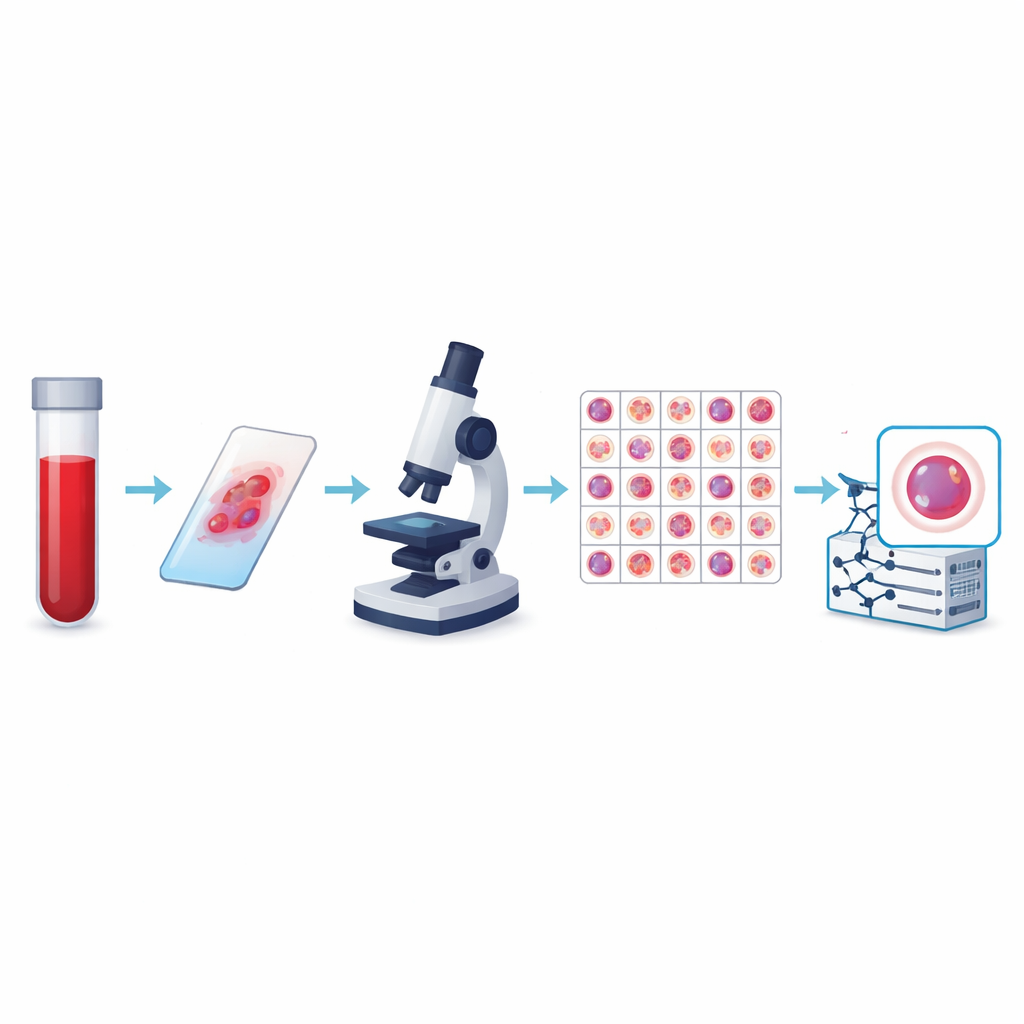
Von einfachen Zählungen zu intelligenter Bildgebung
Weiße Blutkörperchen sind zentrale Verteidiger unseres Immunsystems, und ihr Anteil und Erscheinungsbild liefern entscheidende Hinweise auf den Gesundheitszustand. Ein Anstieg bestimmter Zelltypen kann auf eine Infektion oder Allergie hinweisen, während das plötzliche Auftreten unreifer „Blasten“ vor einer Leukämie warnen kann. Labore verwenden bereits automatisierte Geräte zur Zellzählung, doch subtile Formveränderungen erfordern oft noch das Auge eines Experten. Gutachter können in ihren Beurteilungen auseinandergehen, und das Prüfen von Objektträgern einzeln ist zeitaufwändig. Da die Medizin verstärkt auf digitale Bildgebung und künstliche Intelligenz setzt, wächst der Bedarf an großen, vertrauenswürdigen Bildsammlungen, die Computer darin schulen können, diese charakteristischen Zellmuster so zuverlässig zu erkennen wie ein erfahrener Hämatologe.
Aufbau einer umfassenden Bibliothek von Blutzellen
Die Autorinnen und Autoren haben die derzeit größte öffentliche Sammlung peripherer Blutzellbilder erstellt, den KU-Optofil PBC-Datensatz. Er enthält 31.489 hochaufgelöste Einzelzellbilder, verteilt auf 13 Gruppen, darunter übliche Verteidiger wie Lymphozyten und segmentkernige Neutrophile sowie seltener, aber medizinisch wichtige Typen wie Blasten, Myelocyten und reaktive Lymphozyten. Alle Bilder stammen aus gefärbten Blutausstrichen, die unter standardisierten Bedingungen in einem einzigen Krankenhaus mit demselben Bildgebungssystem hergestellt wurden. Diese Konsistenz sorgt dafür, dass Computer, die mit den Daten lernen, für jeden Zelltyp eine stabile, kontrollierte Darstellung erhalten, anstatt ein Flickwerk inkompatibler Aufnahmen.
Expertise und sorgfältige Kuration
Um den Datensatz vertrauenswürdig zu machen, wurde jedes Bild unabhängig von zwei erfahrenen Labortechnikerinnen bzw. -technikern annotiert; bei Meinungsverschiedenheiten entschied eine dritte Expertin bzw. ein dritter Experte. Statistische Prüfungen zeigten eine sehr starke Übereinstimmung zwischen den Gutachtern für jeden wichtigen Zelltyp, teils sogar perfekte Übereinstimmung. Das Team wandte zudem strenge Regeln an, um zu entscheiden, welche Bilder behalten werden: unscharfe, überlappende oder schlecht gefärbte Zellen wurden verworfen. Die Endbilder haben alle dieselbe Größe und Farbformatierung und sind in Trainings-, Validierungs- und Testordnern organisiert, sodass andere Forschende Algorithmen fair vergleichen können. Zusätzliche Dateien verknüpfen jedes Bild mit einem anonymisierten Patienten, was Studien erlaubt, die untersuchen, ob ein Modell wirklich von einer Person zur nächsten generalisiert.
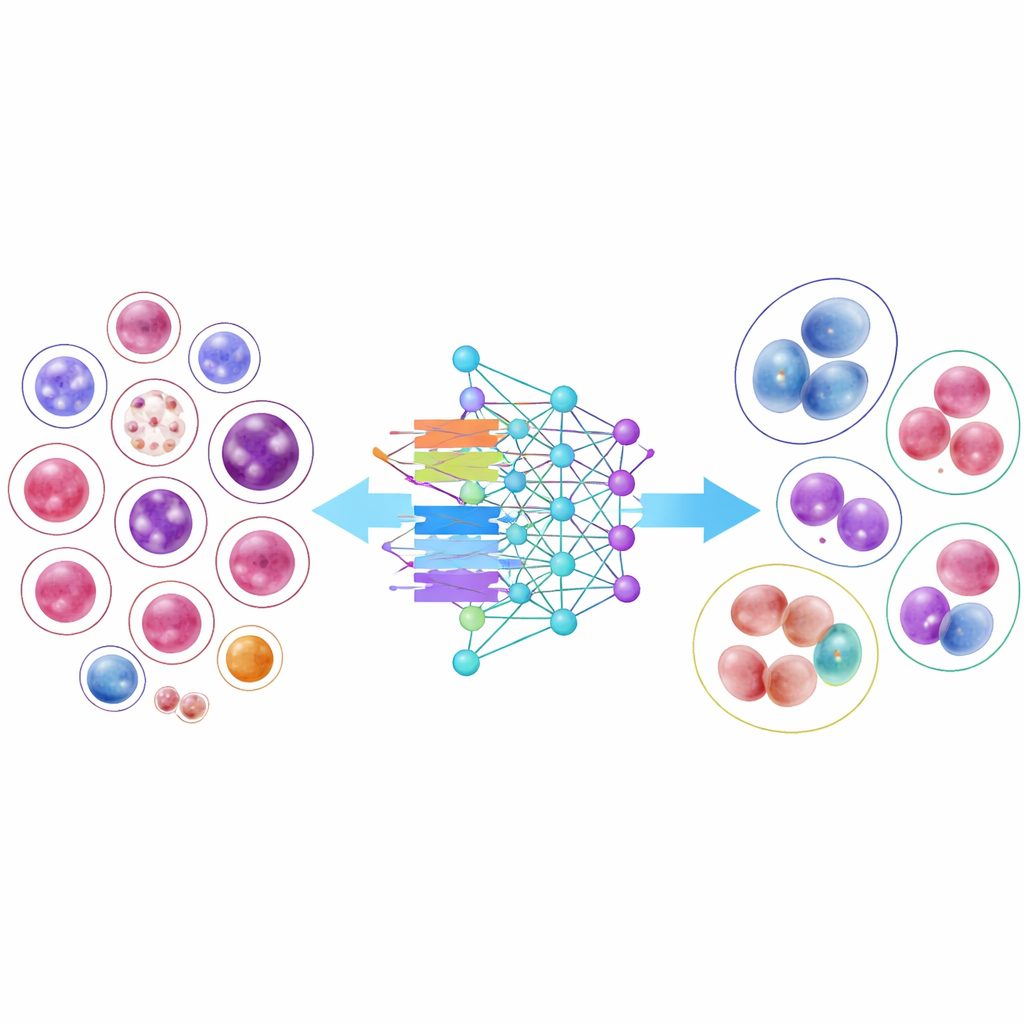
KI-Modelle im Praxischeck
Um zu demonstrieren, wie nützlich diese Bibliothek sein kann, trainierten die Forschenden 14 moderne Bilderkennungsmodelle, von klassischen convolutionalen neuronalen Netzen bis zu neueren transformer-basierten Architekturen. Mehrere kompakte, effiziente Modelle lieferten überraschend gute Leistungen, und eine Architektur, DenseNet-121, klassifizierte Zellen im Mittel zu über 95 Prozent korrekt. Die Ergebnisse zeigten jedoch auch eine wichtige praktische Schwierigkeit: Häufige Zelltypen mit Tausenden von Beispielen wurden nahezu perfekt erkannt, während sehr seltene Zellen mit nur wenigen Dutzend Bildern deutlich schwerer zu klassifizieren blieben. Selbst wenn die Forschenden das Training so anpassten, dass diesen knappen Klassen „mehr Aufmerksamkeit“ geschenkt wurde, sank die Gesamtgenauigkeit, und die Verbesserungen für seltene Typen waren nur moderat — ein Hinweis auf die Herausforderung, aus begrenzten Beispielen zu lernen.
Was das für künftige Bluttests bedeutet
Für Nicht-Spezialistinnen und Nicht-Spezialisten ist die Kernbotschaft, dass diese Arbeit die rohe visuelle Grundlage liefert, die Computersysteme benötigen, um vertrauenswürdige Partner beim Lesen von Blutausstrichen zu werden. Indem eine große, vielfältige und sorgfältig geprüfte Sammlung von Blutzellbildern zusammengestellt und gezeigt wurde, dass viele verschiedene KI-Modelle daraus lernen können, legen die Autorinnen und Autoren den Grundstein für Werkzeuge, die Diagnosen beschleunigen, menschliche Fehler reduzieren und Expertiseniveaus in Kliniken mit weniger Spezialisten verfügbar machen könnten. Gleichzeitig erinnern die gemischten Ergebnisse bei seltenen Zelltypen daran, dass selbst große Datensätze blinde Flecken haben und die Versorgung von Patientinnen und Patienten mit ungewöhnlichen oder frühen Krankheitsstadien erfordert, diese Bildsammlungen weiter auszubauen und zu verfeinern.
Zitation: Yarıkan, A.E., Örer, C., Akyıldız, V. et al. A Large-Scale Peripheral Blood Cell Dataset for Automated Hematological Analysis. Sci Data 13, 417 (2026). https://doi.org/10.1038/s41597-026-06761-y
Schlüsselwörter: Blutzellbildgebung, medizinische KI, Hämatologie, Deep Learning, medizinische Datensätze