Clear Sky Science · de
StatLLM: Ein Datensatz zur Bewertung der Leistungsfähigkeit großer Sprachmodelle in der statistischen Analyse
Warum das für alltägliche Datenanwender wichtig ist
Da KI‑Werkzeuge wie chatbasierte Assistenten zunehmend Teil des Berufsalltags werden, wenden sich immer mehr Menschen an sie, um Zahlen zu rechnen, Experimente durchzuführen und Daten zu analysieren. Wenn eine KI jedoch den Code für eine statistische Studie schreibt – etwa um zu prüfen, ob eine neue medizinische Behandlung wirkt, oder um Schulleistungsdaten zu untersuchen – wie können wir sicher sein, dass sie die Aufgabe korrekt ausgeführt hat? Dieses Paper stellt StatLLM vor, einen öffentlichen Datensatz, der dazu dient, zu testen, wie gut große Sprachmodelle reale statistische Analyseaufgaben bewältigen. Er bietet Forschenden und Praktikern ein klareres Bild davon, wann man KI‑generierten Code vertrauen kann und wann Vorsicht geboten ist.
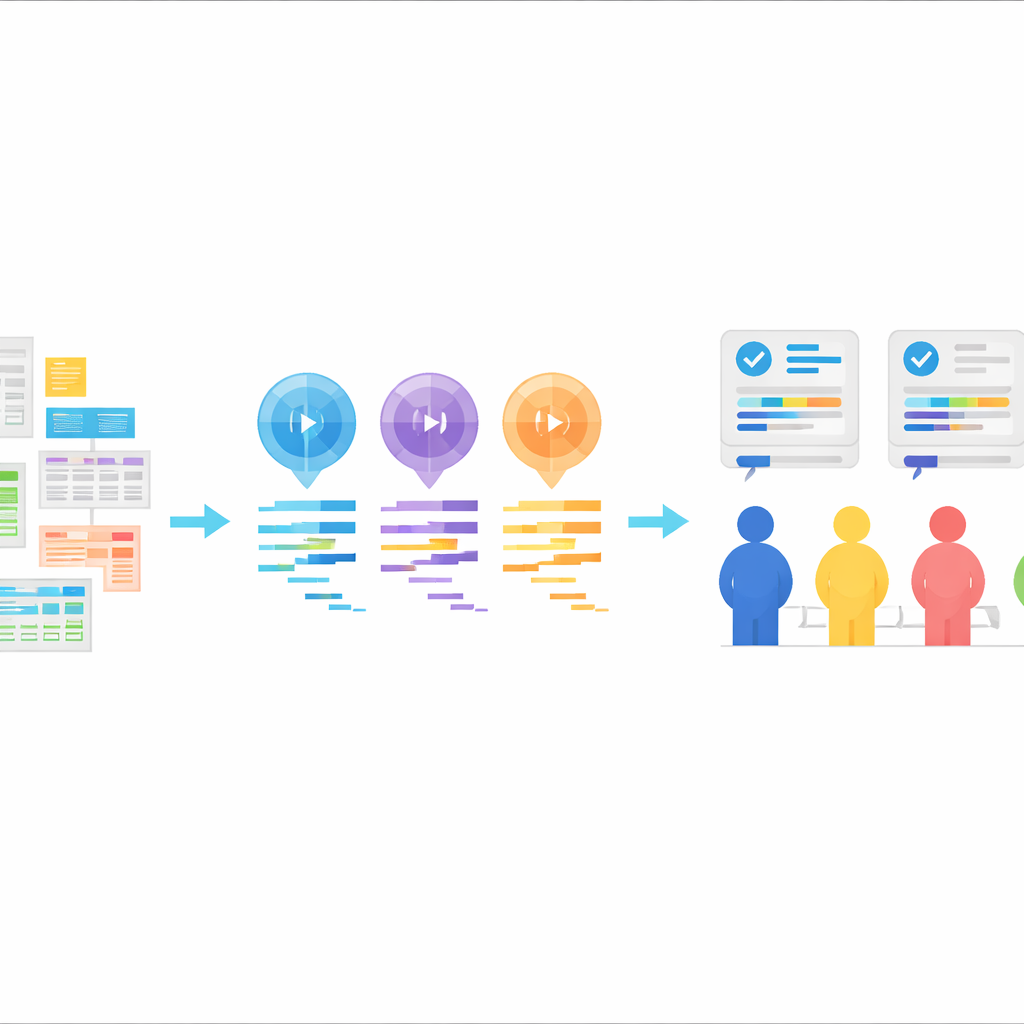
Ein neues Testfeld für KI‑generierten Statistik‑Code
Kern von StatLLM ist eine sorgfältig zusammengestellte Sammlung von 207 statistischen Analyseaufgaben, die aus 65 realen Datensätzen aus Bereichen wie Bildung, Medizin, Wirtschaft, Finanzen, Ingenieurwesen und Sport stammen. Jede Aufgabe enthält eine problemorientierte Beschreibung in Alltagssprache, eine ausführliche Erklärung des Datensatzes und seiner Variablen sowie ein kurzes SAS‑Programm, das von menschlichen Expertinnen und Experten geschrieben und geprüft wurde. Die Aufgaben decken Inhalte ab, die ein gute*r Bachelor- oder Master‑Studierende*r der Statistik lernen würde: von einfachen Datenzusammenfassungen und Grafiken bis hin zu Regression, Überlebenszeitanalysen und fortgeschritteneren Methoden. Das ergibt einen realistischen Test im Stil von Hochschule und Praxis, um zu prüfen, ob KI‑Tools praktische Fragestellungen verstehen und in solide Analyseschritte übersetzen können.
KI Code schreiben lassen und die Arbeit bewerten
Mit diesen Aufgaben baten die Autorinnen und Autoren drei große Sprachmodelle — GPT‑3.5, GPT‑4 und Llama‑3.1 70B —, SAS‑Code zu generieren. Jedes Modell erhielt die gleichen Bestandteile: eine Aufgabenbeschreibung, eine Beschreibung des Datensatzes, die eigentliche Datendatei und eine explizite Anweisung, SAS‑Code zu liefern. Die Modelle wurden im „Zero‑Shot“-Modus eingesetzt, das heißt, sie sahen zuvor keine Beispiele für korrekten SAS‑Code. Die Antworten wurden bereinigt, sodass nur der Code übrig blieb, ohne erläuternden Text. Dieses Setup spiegelt ein gängiges reales Muster wider: Ein Nutzer beschreibt, was er möchte, die KI liefert Code, und dieser Code wird anschließend in einer Statistiksoftware ausgeführt.
Menschliche Expertinnen und Experten als Goldstandard
Um zu beurteilen, wie gut der KI‑generierte Code tatsächlich war, organisierte das Team eine rigorose menschliche Begutachtung. Neun erfahrene SAS‑Anwenderinnen und ‑Anwender bildeten drei Gruppen, die sich jeweils auf einen Leistungsaspekt konzentrierten: ob der Code logisch korrekt und lesbar ist, ob er tatsächlich fehlerfrei ausführbar ist, und ob die resultierenden Ausgaben die Ausgangsfrage klar und korrekt beantworten. Für jede Aufgabe wurden die SAS‑Programme der drei Modelle vermischt, sodass die Bewertenden nicht wussten, welches Modell welchen Code erzeugt hatte. Die Bewertungen erfolgten auf einer Fünf‑Punkte‑Skala und wurden zu einer Gesamtpunktzahl kombiniert, was einen nuancierten Blick auf Stärken und Schwächen über Hunderte von Modell‑Aufgaben‑Paaren ermöglichte. Diese Expertenbewertungen liegen nun zusammen mit dem gesamten Code und den Aufgaben im StatLLM‑Datensatz vor.
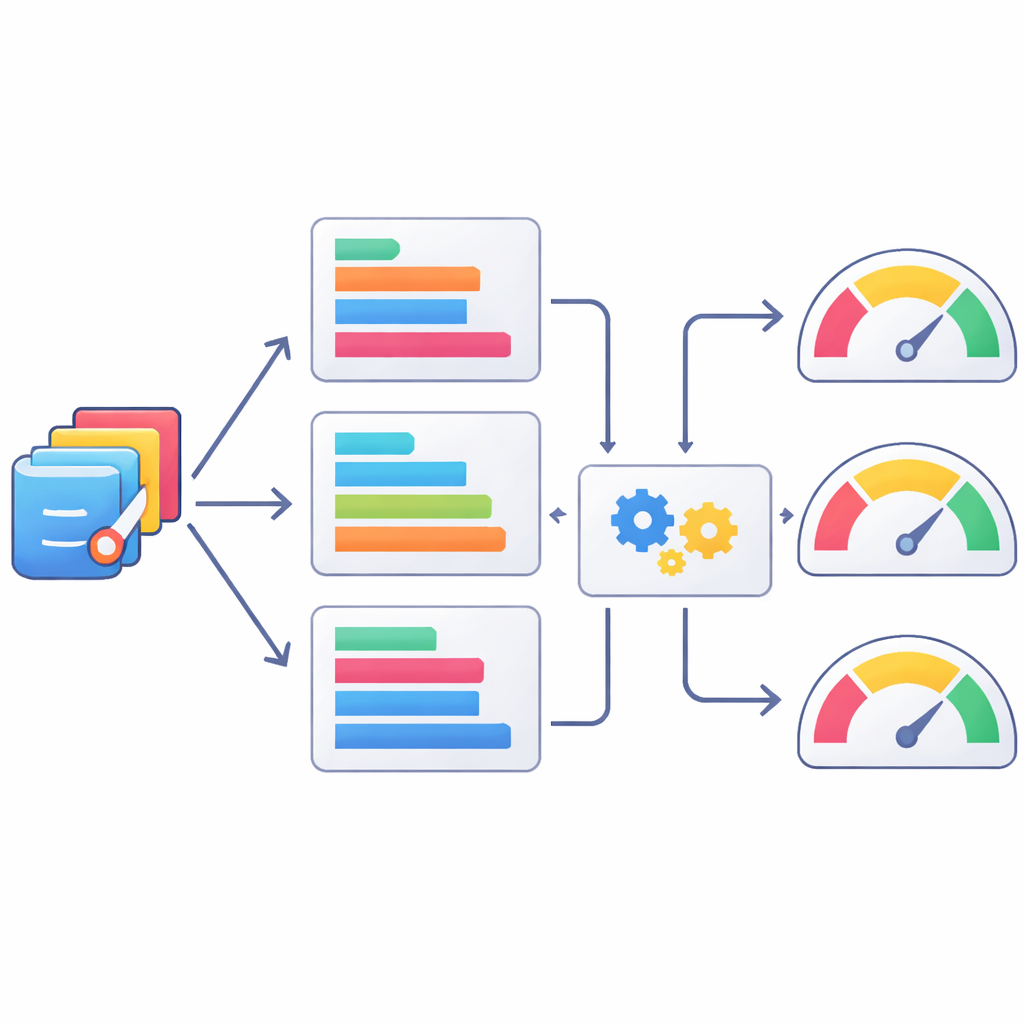
Maschinen beibringen, Code wie Menschen zu beurteilen
Da menschliche Begutachtung langsam und teuer ist, untersuchten die Autorinnen und Autoren außerdem, wie gut automatische, textbasierte Metriken als grobe Richter für die Qualität statistischen Codes dienen können. Sie verglichen die KI‑generierten SAS‑Programme mit den menschlich verifizierten Versionen mithilfe einer Reihe bekannter NLP‑Metriken und prüften, wie gut diese Werte mit den menschlichen Bewertungen übereinstimmen. Einige Metriken, etwa Varianten des ROUGE‑Scores, die Überschneidungen in kurzen Token‑Sequenzen messen, korrelierten besser mit menschlichen Urteilen als andere, aber alle zeigten nur moderate Übereinstimmung. Das Team ging einen Schritt weiter und trainierte maschinelle Lernmodelle, um menschliche Bewertungen aus Kombinationen dieser Metriken vorherzusagen. Methoden wie XGBoost verbesserten die Übereinstimmung mit den menschlichen Bewertungen, blieben jedoch weit davon entfernt, Expertenurteile perfekt abzubilden, was verdeutlicht, dass automatische Scores bestenfalls partielle Stellvertreter sind.
Wege zu künftigen, KI‑gestützten Statistik‑Werkzeugen
Über das reine Benchmarking hinaus zeigen die Autorinnen und Autoren, wie StatLLM neue Werkzeuge und Forschungsrichtungen unterstützen kann. Da jede Aufgabe allgemein formuliert ist, lassen sich dieselben Probleme nutzen, um Codegenerierung in anderen Sprachen wie R oder Python zu testen oder sogar Code aus mehreren Sprachen zu kombinieren. Das Paper hebt Ensemble‑Ansätze hervor, die unterschiedliche KI‑generierte Lösungen mischen könnten, um die Zuverlässigkeit zu erhöhen, und demonstriert eine Prototyp‑R‑Shiny‑App, in der Nutzer einen Datensatz und eine Aufgabenbeschreibung hochladen können, woraufhin ein KI‑System automatisch R‑Code erzeugt und ausführt. StatLLM bietet außerdem eine Plattform, um die nächste Generation statistischer Software zu entwerfen und zu testen, die natürliche Sprachinstruktionen versteht und gleichzeitig an klar messbare Standards gebunden ist.
Was das für den Einsatz von KI in Datenanalysen bedeutet
Für Nicht‑Spezialistinnen und Nicht‑Spezialisten lautet die wichtigste Erkenntnis: KI kann bereits kurze Ausschnitte statistischen Codes schreiben – aber die Zuverlässigkeit ist bei weitem nicht garantiert, insbesondere bei Aufgaben, die über einfache Beispiele hinausgehen. StatLLM bietet einen transparenten, wiederverwendbaren Weg, um zu sehen, wie gut verschiedene Modelle abschneiden, automatische Prüfungen ihrer Arbeit zu verbessern und sicherere, robustere Datenanalysewerkzeuge zu entwickeln. Wenn neuere Sprachmodelle erscheinen, können sie in dieses lebende Benchmark integriert werden, sodass die Gemeinschaft realistisch eingeschätzt bleibt, was KI in ernsthafter statistischer Arbeit kann und was nicht.
Zitation: Song, X., Lee, L., Xie, K. et al. StatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis. Sci Data 13, 369 (2026). https://doi.org/10.1038/s41597-026-06731-4
Schlüsselwörter: große Sprachmodelle, statistische Analyse, Codebewertung, Benchmark-Datensatz, SAS-Programmierung