Clear Sky Science · de
Ein Datensatz wissenschaftlicher Zitationen in Office Actions des US-Patentamts
Warum Patentzitationen für alltägliche Innovationen wichtig sind
Wenn Sie von einem neuen Gerät, einem Medikament oder einer sauberen Energietechnologie hören, steht in der Regel eine Spur von Ideen dahinter. Ein großer Teil dieser Spur ist in Patenten und den Dokumenten, auf die sie verweisen, dokumentiert. Dieser Beitrag stellt einen großen neuen Datensatz vor, der ungewöhnlich detailliert offenlegt, auf welche wissenschaftlichen Arbeiten Patentprüfer sich stützen, wenn sie entscheiden, ob eine Erfindung Schutz verdient. Indem die Autorinnen und Autoren dieses verborgene Fenster in den Prüfungsprozess öffnen, geben sie Forschern, politischen Entscheidungsträgern und auch interessierten Bürgerinnen und Bürgern eine neue Möglichkeit, zu untersuchen, wie wissenschaftliches Wissen reale Innovationen antreibt.
Eine verborgene Ebene im Patentverfahren
Die meisten Patentstudien betrachten nur die auf der Titelseite erteilten Patente angegebenen Zitationen. Diese Listen wirken auf den ersten Blick einfach, sind aber das Endergebnis eines komplexen Hin und Her zwischen Anmeldern und staatlichen Prüfern. Dabei senden Prüfer formelle Schreiben, sogenannte Office Actions, in denen sie erläutern, warum ein Patent angenommen oder abgelehnt werden sollte, und frühere Arbeiten zitieren, die sie für wichtig halten. Viele dieser zitierten Quellen, insbesondere wissenschaftliche Aufsätze, erscheinen nie im endgültigen Patent. Bislang waren sie in großen Mengen schwer zugänglich, weshalb die Forschung dieses reiche Protokoll tatsächlicher Entscheidungsprozesse weitgehend ignoriert hat.
Eine neue Karte aus Office Actions erstellen
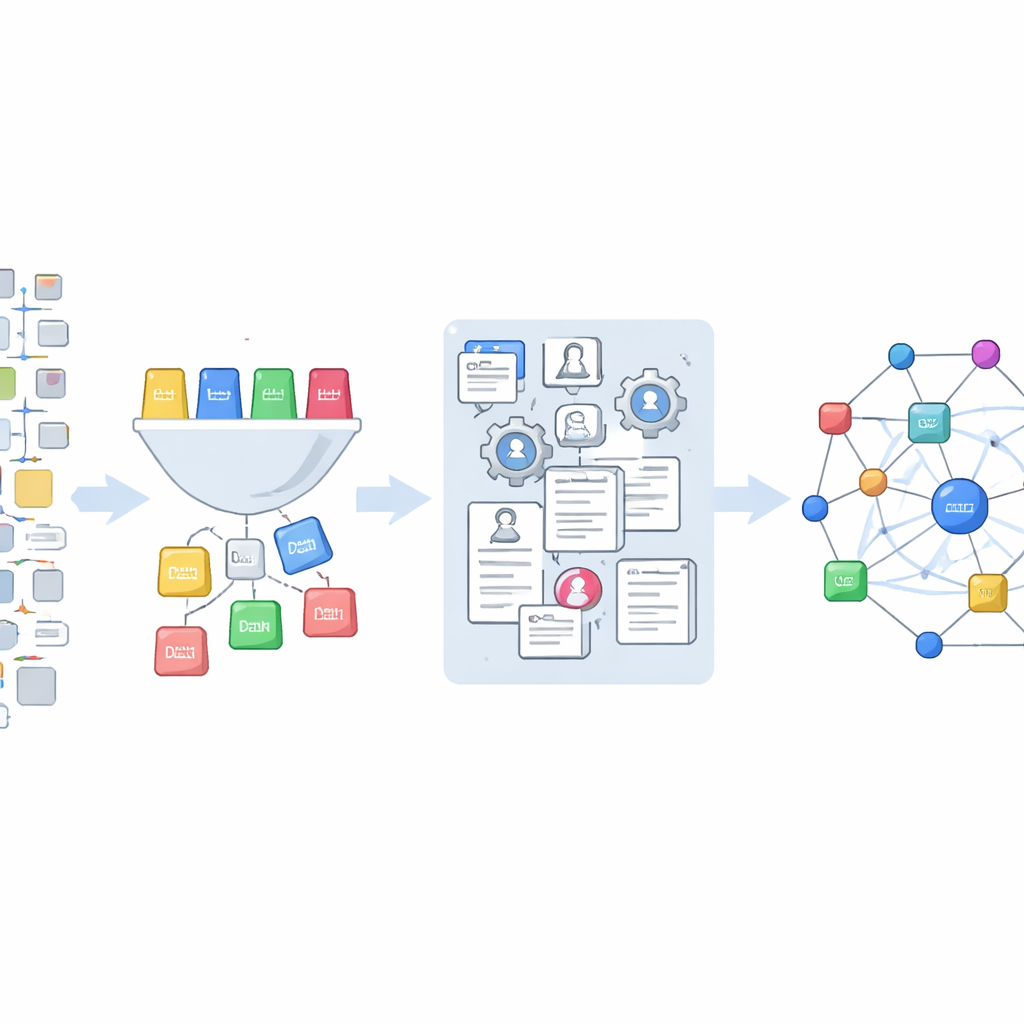
Die Autorinnen und Autoren nutzen einen Fundus von Office-Action-Daten, den das US-Patent- und Markenamt veröffentlicht und der auf Google Cloud gehostet wird. Aus Millionen von Verweisen isolieren sie etwa 850.000, die nicht auf andere Patente verweisen, sondern auf externe Quellen wie Fachaufsätze, Bücher, Webseiten und Produktanleitungen. Sie entwickeln ein Schema mit 14 alltäglichen Kategorien – von Büchern und Tagungsbänden bis zu Webseiten und Produktdokumentationen – und trainieren dann ein Machine-Learning-Modell, das jede Zitation einer dieser Typen zuordnet. Dieses Modell, verfeinert mit Beispielen, die mithilfe eines fortgeschrittenen Sprachsystems gelabelt wurden, klassifiziert fast 847.000 einzigartige Zitierstrings.
Von unordentlichen Verweisen zu sauberen Forschungsaufzeichnungen
Zu identifizieren, welche Zitationen wissenschaftlich sind, ist nur der erste Schritt. Referenzen aus der Praxis sind unordentlich: Titel können unvollständig sein, Jahreszahlen falsch eingegeben und Seitenangaben durcheinandergeraten. Um dieses Geflecht in nutzbare Daten zu verwandeln, speist das Team die Rohstrings in ein spezialisiertes Tool, das sie in Komponenten wie Autor, Jahr, Zeitschrift und Seitenbereich zerlegt und dabei sorgfältige Bereinigungsregeln anwendet. Anschließend stimmen sie diese bereinigten Datensätze mit OpenAlex, einer großen offenen Datenbank für Forschungsarbeiten, ab – mit zwei Strategien. Wenn ein Titel vorhanden ist, suchen sie per Titel und behalten nur hochvertrauenswürdige Übereinstimmungen; ist kein Titel verfügbar, verlassen sie sich auf Kombinationen aus Autorennamen, Zeitschrift, Jahr und Seitenangaben. Findet OpenAlex keine Übereinstimmung, greifen sie auf Crossref zurück, eine weitere wichtige Quelle für Publikationsidentifier, und führen gefundene Digital Object Identifiers zurück in OpenAlex.
Wie zuverlässig ist der neue Datensatz?
Da diese Ressource zukünftige Studien untermauern soll, widmen die Autorinnen und Autoren umfangreiche Arbeit der Prüfung ihrer Genauigkeit. Ihr Klassifikator weist Referenzen insgesamt in etwa 92 Prozent der Fälle dem richtigen Typ zu und liefert besonders gute Ergebnisse bei den häufigsten Klassen wie Fachaufsätzen und Patenten. Für den Abgleich zeigen manuelle Überprüfungen, dass titelbasierte Suchen mit steigender Übereinstimmungsbewertung genauer werden und in der besten Gruppe Prozentwerte im mittleren bis hohen 90er-Bereich erreichen, während Suchen auf Basis detaillierter Metadaten in einer Stichprobe zu 99 Prozent korrekt sind. Quervergleiche von über Crossref wiedergewonnenen Datensätzen zeigen ebenfalls nahezu perfekte Übereinstimmung. Die Autorinnen und Autoren sind offen bezüglich schwächerer Bereiche – etwa seltener Kategorien wie Dissertationen oder technische Berichte – und ermutigen Nutzerinnen und Nutzer, diese bei Bedarf zu verfeinern.
Neue Wege, zu untersuchen, wie Wissenschaft Technologie antreibt
Der fertige Datensatz verknüpft rund 265.000 wissenschaftliche Referenzen aus Office Actions mit einzelnen US-Patentanmeldungen und mit umfangreichen Publikationsdatensätzen in OpenAlex. Das ermöglicht Forschenden, neue Fragestellungen zu stellen: Wie stark stützen sich verschiedene Prüfergruppen oder Technologiebereiche auf wissenschaftliche Arbeiten? Welche Studien gelten während der Prüfung als wichtig, fallen aber im endgültigen Patent weg? Greifen aufgegebene Patente auf einen anderen Ausschnitt des wissenschaftlichen Bestands zurück als erfolgreiche? Da sämtlicher Code und alle Daten offen freigegeben sind, können andere die Werkzeuge anpassen, die Abdeckung erweitern und die Klassifikationen verfeinern. Kurz gesagt verwandelt diese Arbeit eine obskure und verstreute Sammlung juristischer Dokumente in eine klare, wiederverwendbare Karte davon, wie Wissenschaft und Technologie im Patentsystem aufeinandertreffen.
Zitation: Higham, K., Kotula, H., Scharfmann, E. et al. A dataset of scientific citations in U.S. patent Office Actions. Sci Data 13, 325 (2026). https://doi.org/10.1038/s41597-026-06720-7
Schlüsselwörter: Patentzitationen, Office Actions, wissenschaftliche Literatur, Innovationsdaten, OpenAlex