Clear Sky Science · de
Ein chinesisches Named‑Entity‑Recognition‑Datensatz für immaterielles Kulturerbe
Warum der Schutz lebendiger Traditionen kluges Lesen braucht
Weltweit drohen lebendige Traditionen wie Volksmusik, Handwerk und lokale Feste aus dem Alltag zu verschwinden. In China beschreiben bereits große Mengen an Texten diese Praktiken, doch die meisten stehen in langen Webseiten, die für Menschen — oder Computer — schwer zu durchsuchen oder zu analysieren sind. Diese Studie stellt einen sorgfältig erstellten chinesischsprachigen Datensatz und ein fortschrittliches KI‑Modell vor, das automatisch wichtige Informationen in solchen Texten erkennen kann, etwa Namen von Handwerksgattungen, Meisterinnen und Meistern, Materialien und Orten. Zusammen bieten sie neue Werkzeuge, um immaterielles Kulturerbe im digitalen Maßstab besser zu bewahren und zu erforschen.
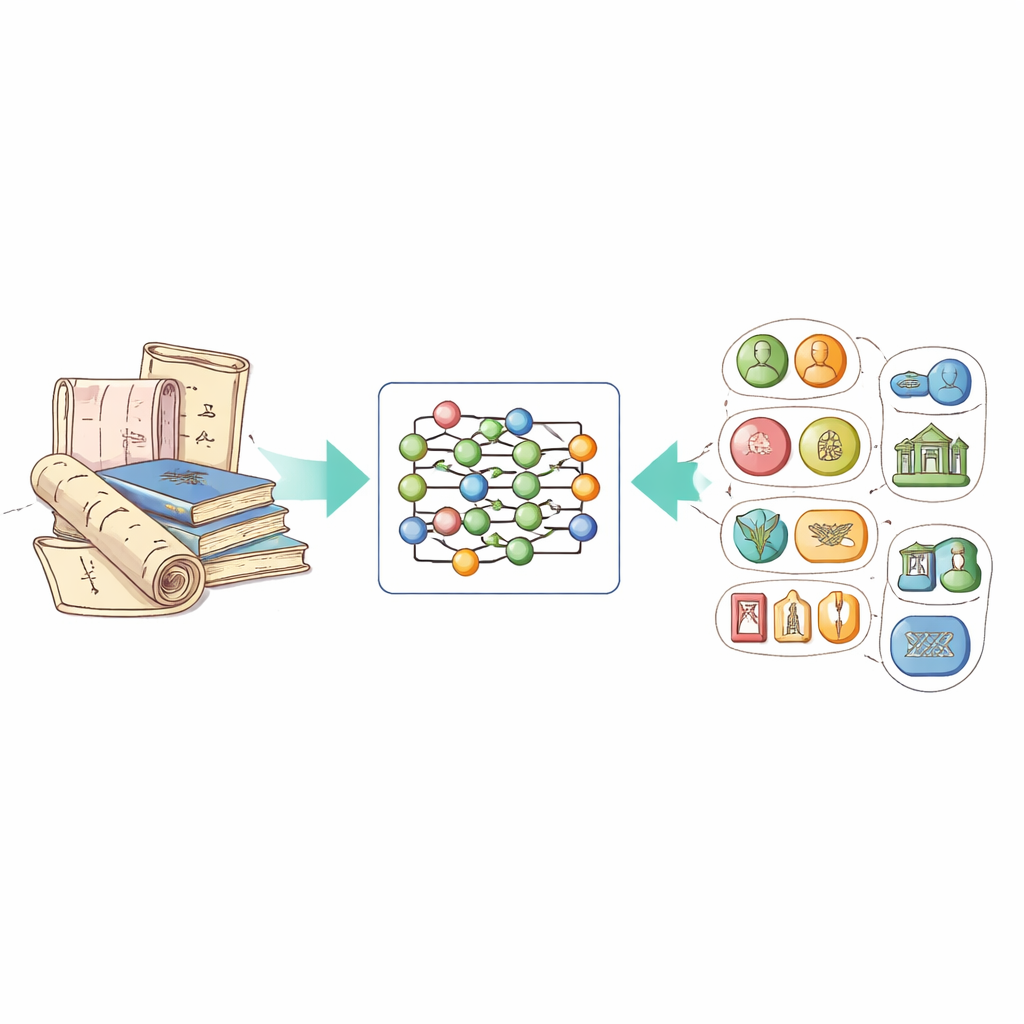
Aus unordentlichem Text organisiertes Wissen machen
Die Kernidee der Arbeit ist eine Technik namens Named‑Entity‑Recognition, die Computern beibringt, wichtige Elemente im Text hervorzuheben: Personen, Orte, Zeitangaben, Organisationen und Ähnliches. Für das immaterielle Kulturerbe bedeutet das außerdem, besondere Entitätentypen zu erkennen, etwa die Namen von Schutzprojekten, spezifische Handwerkstechniken und die verwendeten Materialien. Das Problem war bisher, dass es keinen öffentlichen, domänenspezifischen Datensatz für Chinesisch gab und allgemein einsetzbare Systeme mit lebendigen Beschreibungen, poetischer Sprache und regionalen Ausdrücken in Heritage‑Texten überfordert waren.
Aufbau einer fokussierten Sammlung von Heritage‑Texten
Um diese Lücke zu schließen, stellten die Autorinnen und Autoren einen neuen Datensatz namens ICH‑NER aus dem offiziellen chinesischen Netzwerk für immaterielles Kulturerbe zusammen. Sie konzentrierten sich auf einträge zu Handwerkskünsten — etwa traditionelle Textilien, Keramik, Metallarbeit und Schnitzerei —, weil diese Beschreibungen reich an Details zu Prozessen und Materialien sind. Nach dem Entfernen von Bekanntmachungen und Duplikaten definierten sie acht zentrale Entitätskategorien: Bezeichnungen von Kulturgütern, Orte, Personen, Organisationen, Zeiträume, Ethnien, Materialien und Handwerkstechniken. Jedes chinesische Schriftzeichen in den Texten wurde mit einem einfachen Code versehen, der angibt, ob es zu einer Entität gehört und wenn ja, welcher Art. Insgesamt enthält der Datensatz 7.779 Proben und mehr als 21.000 annotierte Entitäten und bildet damit einen soliden Benchmark für zukünftige Forschung.
Sorgfältige Regeln für konsistente Annotation
Da für diese Art von Heritage‑Texten kein standardisiertes Klassifikationssystem existierte, entwickelten die Forschenden zunächst detaillierte Richtlinien auf Basis nationaler Listen und offizieller Beschreibungen. Sie führten eine Pilotphase durch, um knifflige Fälle zu klären, etwa Orte, die zugleich Teil von Projektnamen sind, oder verschachtelte Phrasen, in denen eine Entität in einer anderen liegt. Ein einzelner geschulter Annotator kennzeichnete anschließend den gesamten Datensatz mithilfe quelloffener Software und überprüfte wiederholt frühere Labels, um Inkonsistenzen zu korrigieren. Die finalen Daten sind in Trainings‑ und Entwicklungssets aufgeteilt, wobei auf ähnliche Anteile der Entitätentypen und eine ausgewogene Verteilung regionaler Begriffe und Schreibstile in beiden Teilen geachtet wurde.
Entwurf eines KI‑Modells, das auf Heritage‑Sprache abgestimmt ist
Parallel zum Datensatz schlägt die Studie ein spezialisiertes Erkennungsmodell vor, das mehrere moderne KI‑Komponenten kombiniert. Zuerst wandelt ein leistungsfähiger Sprachencoder (RoBERTa) die chinesischen Schriftzeichen in kontextabhängige numerische Repräsentationen um, die widerspiegeln, wie Wörter im umgebenden Text verwendet werden. Dann lernt ein Kolmogorov–Arnold‑Netzwerk‑Modul subtile, nichtlineare Muster — beispielsweise wie bestimmte Materialien typischerweise mit bestimmten Techniken oder Regionen zusammen auftreten. Eine Multi‑Head‑Attention‑Schicht untersucht anschließend Beziehungen über den gesamten Satz aus verschiedenen Blickwinkeln, und schließlich wählt eine Decoderschicht die wahrscheinlichste Sequenz von Entitätslabels. Diese Architektur ist darauf ausgelegt, lange, komplexe Sätze mit Metaphern und vielschichtigen kulturellen Bezügen zu verarbeiten.
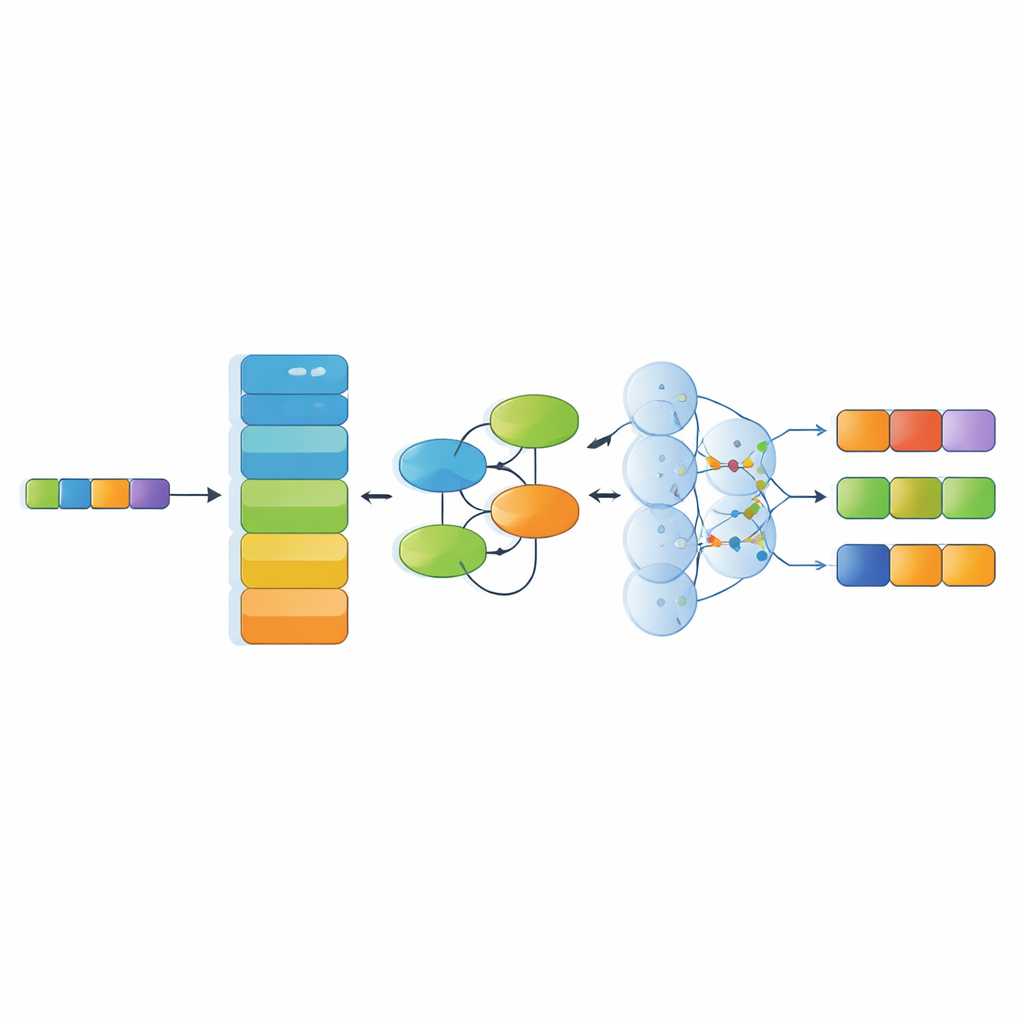
Wie gut das System Heritage‑Texte versteht
Die Autorinnen und Autoren verglichen ihr Modell mit mehreren starken Baselines, die in der Sprachforschung üblich sind, darunter Systeme auf Basis rekurrenter Netze, Gitterstrukturen für chinesischen Text und eine neuere Methode, die Entitäten als Segmente behandelt, die Schritt für Schritt verfeinert werden. Auf dem ICH‑NER‑Datensatz übertrafen Methoden, die auf modernen vortrainierten Sprachmodellen basieren, deutlich ältere Ansätze. Ihr kombiniertes RoBERTa–KAN–Attention–Decoder‑System erzielte die beste Gesamtausgewogenheit von Präzision und Recall, insbesondere für schwierige Kategorien wie Materialien, Organisationen und Handwerkstechniken, bei denen die Daten vergleichsweise spärlich sind und Beschreibungen oft komplex oder mehrdeutig ausfallen.
Was das für lebendige Kultur im digitalen Zeitalter bedeutet
Praktisch erleichtern der neue Datensatz und das Modell es Computern, wer, was, wo und wann aus reichen Beschreibungen traditioneller Handwerke herauszulesen. Diese strukturierten Informationen können in Wissensgraphen, interaktive Karten oder Suchwerkzeuge eingespeist werden, die Forschenden, Kuratorinnen und Kuratoren sowie der Öffentlichkeit helfen, nachzuvollziehen, wie Techniken sich verbreiten, wie bestimmte Familien oder Regionen ein Handwerk prägen und wie Praktiken sich im Laufe der Zeit entwickeln. Obwohl die Arbeit technisch ist, ist ihre Wirkung menschlich: Sie bietet einen Weg, verstreute, textgebundene Beschreibungen lebendiger Traditionen in organisiertes Wissen zu verwandeln, das die Bewahrung und das Verständnis immateriellen Kulturerbes besser unterstützt.
Zitation: Long, S., Li, W. A Chinese Named Entity Recognition Dataset for Intangible Cultural Heritage. Sci Data 13, 335 (2026). https://doi.org/10.1038/s41597-026-06700-x
Schlüsselwörter: immaterielles Kulturerbe, Named‑Entity‑Recognition, chinesische Sprachverarbeitung, kulturelle Datensätze, digitale Bewahrung