Clear Sky Science · de
Globale Emissionsfaktoren‑Datensatz für Scope‑3‑Maschinenlern‑Anwendungen
Warum es wichtig ist, verstecktes CO2 zu verfolgen
Der größte Teil des Klimaeinflusses moderner Unternehmen stammt nicht aus ihren eigenen Schornsteinen, sondern aus langen, verzweigten Lieferketten – all dem, was sie kaufen, verkaufen, verschicken und auslagern. Diese sogenannten „Scope‑3“‑Emissionen sind berüchtigt schwer zu erfassen. Die Studie stellt ExioML vor, einen offenen globalen Datensatz und ein Toolkit, das Jahrzehnte komplexer Wirtschafts‑ und Umweltdaten in maschinenlern‑fertige Form bringt. Das erleichtert Forschern, politischen Entscheidungsträgern und Unternehmen die Abschätzung, wo Emissionen tatsächlich entstehen, einen fairen Methodenvergleich und die Entwicklung intelligenterer Klimaschutzmaßnahmen.
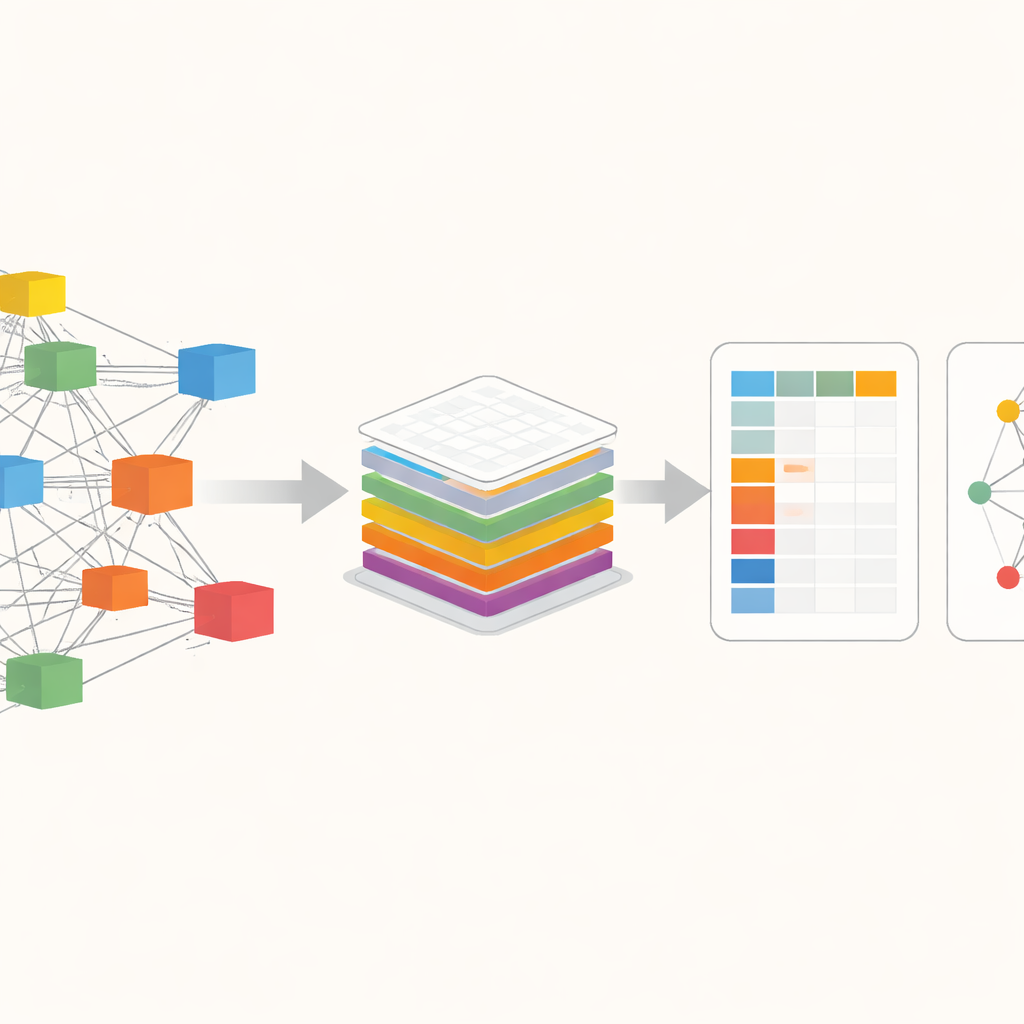
Die Weltwirtschaft als Vernetzung sehen
Kern von ExioML ist eine Sichtweise, die die Weltwirtschaft als riesiges Netz von Branchen begreift, die über Grenzen hinweg miteinander handeln. Statt nur zu zählen, wie viel CO2 innerhalb eines Landes freigesetzt wird, folgt dieser Ansatz der Spur der Emissionen entlang der Lieferketten: von Rohstoffen über Fabriken und Geschäfte bis hin zu Verbraucherinnen und Verbrauchern. Bestehende Datenbanken, die das leisten, sind zwar leistungsfähig, aber oft hinter Bezahlschranken verborgen, schwer zu nutzen oder veraltet. Die Autorinnen und Autoren bauen auf einer der detailliertesten offenen Quellen, EXIOBASE, auf und reorganisieren sie so, dass jede:r leicht Fragen stellen kann wie: Wie viel Treibhausgas ist an der Stahlproduktion in einem bestimmten Land und Jahr gebunden, oder wie sind Emissionen einer Region in Produkten eingebettet, die anderswo konsumiert werden?
Rohdaten in gebrauchsfertige Daten verwandeln
Die rohen EXIOBASE‑Dateien sind riesig – über 40 Gigabyte an Tabellen, die Transaktionen zwischen Hunderten von Sektoren in Dutzenden Regionen beschreiben, plus parallele Aufzeichnungen zu Emissionen, Ressourcen und Energieverbrauch. Die Autor:innen entwerfen ExioML, um diese Komplexität in zwei Hauptbestandteile zu destillieren. Der erste ist eine „Faktoren‑Tabelle“: eine sauber strukturierte Tabelle, in der jede Zeile einen konkreten Sektor in einer bestimmten Region und einem bestimmten Jahr darstellt, mit Spalten für Wertschöpfung, Beschäftigung, Energieverbrauch und Treibhausgasausstoß. Der zweite ist ein „Footprint‑Netzwerk“: eine gestraffte Karte der stärksten Handelsverbindungen zwischen Sektoren, die zeigt, wie Geld, Energie und Emissionen durch die Weltwirtschaft fließen. Zur Erstellung dieser Daten setzen sie auf leistungsstarke Grafikprozessoren (GPUs), um die rechenintensiven Matrixberechnungen nachzuverfolgen, die Emissionen entlang der Lieferketten zurückverfolgen, und sie standardisieren Einheiten, Sektorcodes und Bezeichnungen, sodass alle 49 Regionen und 28 Jahre direkt vergleichbar sind.
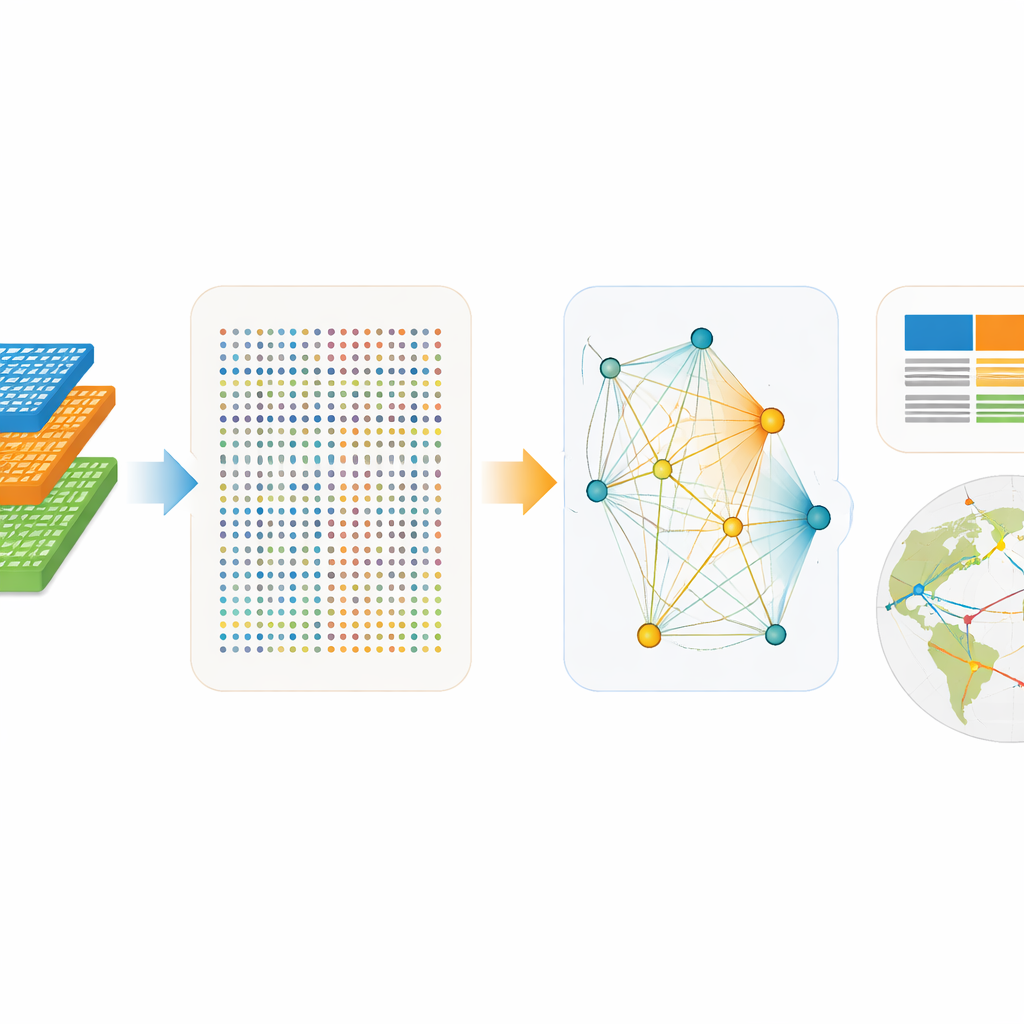
Für modernes maschinelles Lernen gebaut
ExioML ist von Grund auf mit Blick auf maschinelles Lernen konzipiert. Der Datensatz umfasst 49 Regionen von 1995 bis 2022 und bietet zwei kompatible Sichten: eine mit 200 Produktarten und eine mit 163 Industrien. Diese Struktur erlaubt es Forschenden, jeden Sektor–Region–Jahr‑Eintrag als Datenpunkt zu behandeln und einfache numerische Merkmale – wie Bevölkerung, Einkommen pro Kopf, Energie pro Produktionseinheit oder Emissionen pro Energieeinheit – mit kategorialen Informationen über Ort und Art des Sektors zu kombinieren. Die Autor:innen veröffentlichen zudem ein Open‑Source‑Softwarepaket, das die Daten laden, Netzwerksummen erzeugen und sogar einsatzbereite Trainings‑, Validierungs‑ und Testaufteilungen liefern kann. Das senkt die Hürde für Klima‑ und Datenwissenschaftler:innen, die Modelle bauen möchten, ohne erst Experten in spezialisierter wirtschaftlicher Buchführung werden zu müssen.
Testen, wie gut Modelle Emissionen vorhersagen können
Um die Nutzung von ExioML zu demonstrieren, richten die Autor:innen eine Benchmark‑Aufgabe ein: die Vorhersage der Treibhausgasemissionen eines Sektors aus einer kleinen Menge wirtschafts‑ und energiebezogener Indikatoren. Sie vergleichen klassische Machine‑Learning‑Modelle, wie k‑nächste Nachbarn und baumbasierte Ensembles, mit modernen Deep‑Learning‑Ansätzen, die automatisch Merkmalskombinationen erlernen können. Nach sorgfältiger Datenbereinigung, Skalierung und Aufteilung zeigen sich einfache lineare Modelle überfordert, was bestätigt, dass die Beziehung zwischen Produktion, Beschäftigung, Energieverbrauch und Emissionen stark nichtlinear ist. Baumbasierte Methoden und neuronale Netze erzielen beide gute Ergebnisse; ein gatedes Neuronales Netzwerk erreicht die beste Genauigkeit. Der Zugewinn gegenüber gut abgestimmten Gradient‑Boosted‑Trees ist jedoch moderat, während die tiefen Modelle deutlich länger zum Trainieren brauchen und schwieriger zu optimieren sind.
Was das für Klima‑ und Datenarbeit bedeutet
Für Nicht‑Spezialistinnen und Nicht‑Spezialisten ist die Kernbotschaft: ExioML verwandelt ein undurchsichtiges Geflecht globaler Wirtschafts‑ und Umweltdaten in eine gemeinsame, offene Grundlage, auf der jede:r aufbauen kann. Unternehmen, die den Klimaeinfluss ihrer Einkäufe verstehen wollen, Forschende, die Algorithmen zur Identifikation von Emissions‑Hotspots entwickeln, und Analyst:innen, die untersuchen, wie Politik oder Technologien zukünftige Emissionen verändern könnten, können alle aus derselben transparenten Ressource arbeiten. Die Studie zeigt, dass mit der richtigen Struktur selbst relativ einfache Machine‑Learning‑Werkzeuge einen Großteil der verborgenen Muster in Emissionen über Sektoren und Regionen erfassen können. Durch die Kombination von Offenheit, technischer Sorgfalt und praktischer Software trägt ExioML dazu bei, die CO2‑Buchführung von einem Flickwerk privater Schätzungen hin zu einer reproduzierbaren, datengetriebenen Wissenschaft zu bewegen.
Zitation: Guo, Y., Guan, C. & Ma, J. Global emission factor dataset for Scope 3 machine learning applications. Sci Data 13, 348 (2026). https://doi.org/10.1038/s41597-026-06699-1
Schlüsselwörter: Scope‑3‑Emissionen, CO2‑Buchführung, Input‑Output‑Analyse, maschinelles Lernen, Lieferketten‑Emissionen