Clear Sky Science · de
Ein fein granuliertes Fundusbild-Datensatz zur Beurteilung und Diagnose des Kataraktschweregrads
Warum klarere Augenuntersuchungen wichtig sind
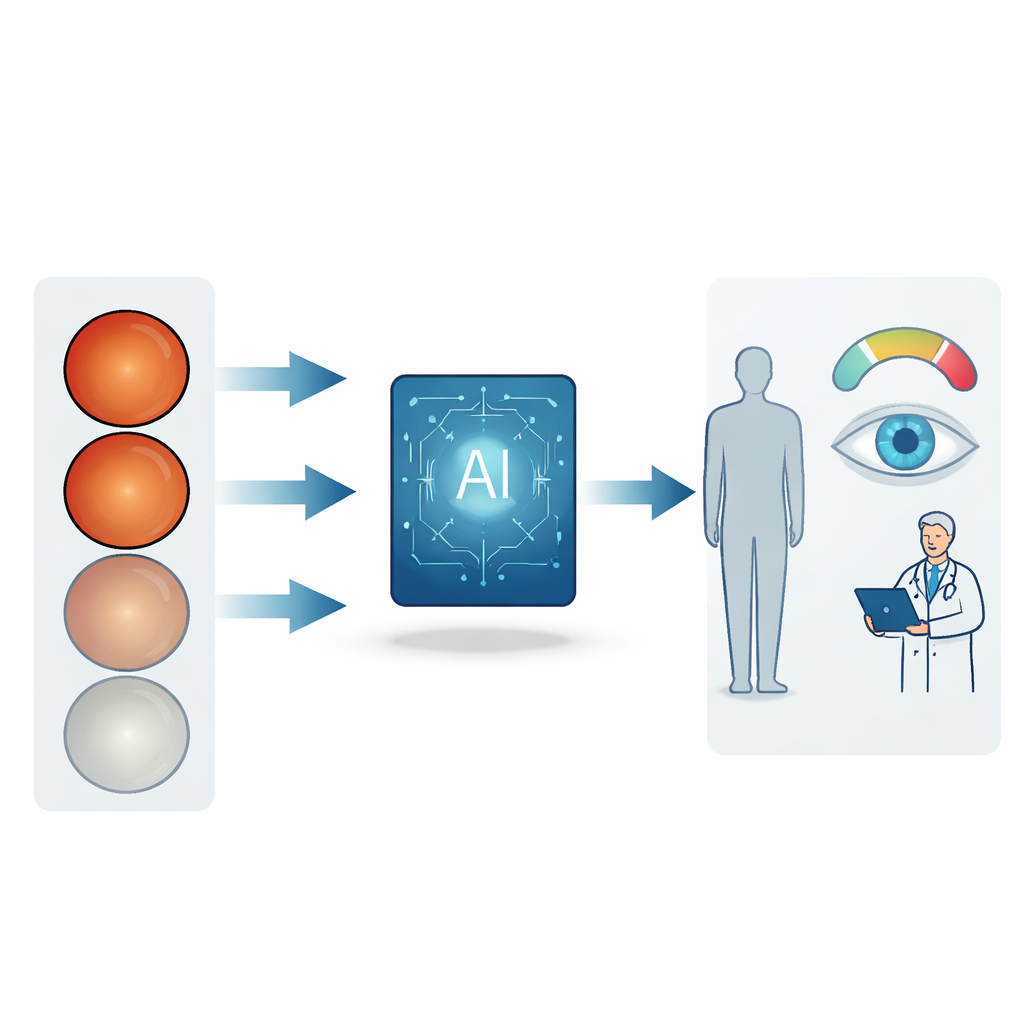
Katarakte sind weltweit die häufigste Ursache für Erblindung, insbesondere bei älteren Menschen. Viele Betroffene erfahren jedoch erst von einem ernsthaften Problem, wenn ihr Sehvermögen bereits so stark nachgelassen hat, dass der Alltag beeinträchtigt ist. Dieser Artikel stellt eine neue, sorgfältig annotierte Sammlung von Augenfotografien sowie ein KI-Framework vor, das den Schweregrad einer Katarakt beurteilt und diese Einschätzung in verständlicher Sprache erklärt. Indem ein einzelnes Augenbild in ein detailliertes „Reportcard“ zur Linsentrübung und Sehqualität verwandelt wird, zielt die Arbeit darauf ab, eine frühe und genaue Kataraktbeurteilung weit über spezialisierte Augenkliniken hinaus verfügbar zu machen.
Ein genauerer Blick auf den Augenhintergrund
Anstatt die getrübte Linse direkt zu fotografieren, konzentrieren sich die Forschenden auf Fundusaufnahmen – Farbbilder der Netzhaut, der lichtempfindlichen Schicht im hinteren Teil des Auges. Wenn die Linse trüb wird, wirken diese Bilder matt und unscharf, Blutgefäße verblassen und wichtige Bereiche werden schwer erkennbar. Ärztinnen und Ärzte nutzen diese Hinweise bereits informell, doch bislang gab es keinen öffentlichen Datensatz, der subtile Veränderungen in diesen Bildern mit fein abgestuften Katarakt-Schweregraden und fachlich formulierten Erklärungen verknüpft. Der neue Cataract Severity and Diagnostic Image-Datensatz (CSDI) schließt diese Lücke und liefert KI-Modellen die reichhaltige Anleitung, die nötig ist, um fachärztliche Urteile nachzuahmen.
Aufbau einer reich annotierten Sammlung von Augenbildern
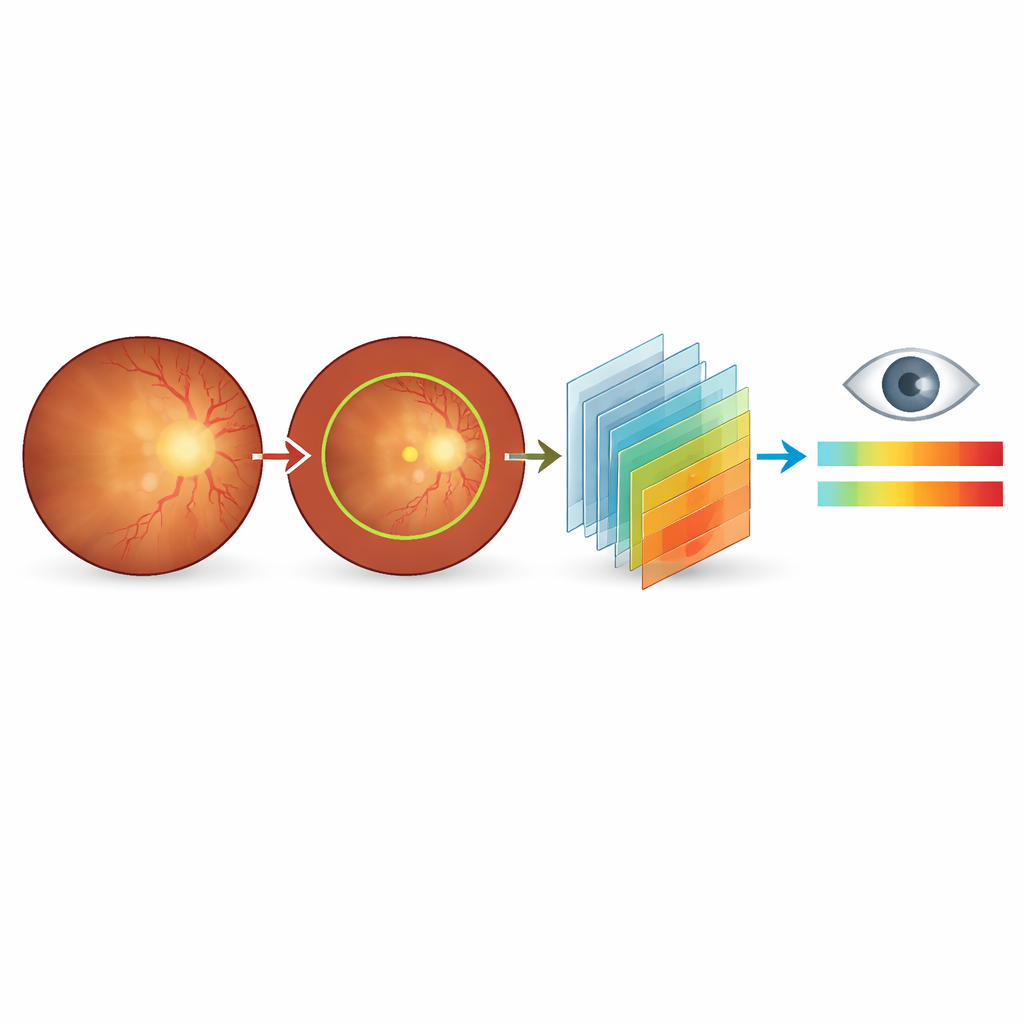
CSDI basiert auf 187 Fundusbildern von Patientinnen und Patienten, die zwischen 2023 und 2024 in einem großen Augenkrankenhaus in Peking untersucht wurden. Alle Bilder wurden mit derselben Kamera und denselben Einstellungen aufgenommen, um technische Unterschiede zu minimieren. Zwei erfahrene Augenärzte sichteten die Aufnahmen zunächst und schieden solche aus, die schlecht belichtet, teilweise verdeckt oder durch andere Augenerkrankungen beeinträchtigt waren. Für jedes verbleibende Bild beurteilten sie die allgemeine Farbe und Klarheit, wie scharf der Sehnervkopf und seine oberflächlichen Gefäße erschienen, wie leicht sich die zentrale Makularegion lokalisieren ließ und wie viele Verzweigungen der Netzhautgefäße noch sichtbar waren. Diese Beobachtungen wurden sowohl in eine numerische Bewertung als auch in eine strukturierte schriftliche Diagnose überführt.
Von einfachen Labels zu einer detaillierten Katarakt-„Anzeigetafel“
Statt bei einer Ja-/Nein-Antwort zu bleiben, entwickelte das Team eine Schweregradskala von 0–10 mit einer Dezimalstelle. Werte nahe Null deuten darauf hin, dass die Katarakt das Fundusbild nicht beeinflusst; mittlere Werte entsprechen leichten bis mäßigen Unschärfen, die eine engere Nachverfolgung rechtfertigen könnten; hohe Werte signalisieren eine starke Bildverschlechterung, die mit erheblichen Sehproblemen und wahrscheinlich einem Operationsbedarf einhergeht. Zur Unterstützung eines konsistenten KI-Trainings stellten die Forschenden außerdem automatische Umrisse der Hauptfundusregion sowie manuelle Konturen und Sichtbarkeitsmarkierungen für den Sehnervkopf bereit. Jedes Bild ist von passenden englischen und chinesischen Diagnosesätzen begleitet, die Farbveränderungen, Unschärfen und verlorene Details in einer festen Reihenfolge beschreiben und den Modellen eine Vorlage dafür geben, wie Fachleute ihre Beobachtungen begründen.
Sprach‑und‑Bild‑KI beibringen, wie ein Augenfacharzt zu handeln
Aufbauend auf diesem Datensatz testeten die Autorinnen und Autoren ein neues Diagnose-Framework, das auf multimodalen großen Sprachmodellen basiert – Systeme, die sowohl Bilder als auch Text verarbeiten. Diese Modelle erhalten ein Fundusfoto und eine kurze Anweisung, „als Augenarzt zu handeln“, und antworten dann mit einer Schweregradeinschätzung und einer narrativen Erklärung. Das Team bewertete sowohl kommerzielle als auch Open-Source-Modelle in zwei Aufgaben: die Einordnung jedes Falls in einen von fünf Schweregraden (von normal bis schwer) und das Erzeugen einer Diagnosebeschreibung, die mit der Formulierung von Expertinnen und Experten übereinstimmt. Anschließend wurden mehrere Open-Source-Modelle mit effizienten Techniken feinabgestimmt, sodass sie innerhalb von Krankenhausnetzwerken laufen können und Patientendaten vor Ort bleiben, während sie dennoch die Leistung größerer kommerzieller Systeme erreichen oder sogar übertreffen.
Was das für Patientinnen, Patienten und Ärztinnen und Ärzte bedeutet
Für breite Leserkreise ist die Kernbotschaft, dass ein einzelnes Augenfoto nun in ein nuanciertes Bild der Kataraktwirkung verwandelt werden kann und nicht nur in ein grobes „Sie haben sie oder nicht“. Der CSDI-Datensatz, frei verfügbar zusammen mit dem Code, ermöglicht es Forschenden und Klinikerinnen und Klinikern weltweit, KI-Systeme zu entwickeln und zu vergleichen, die dieselbe Sprache wie Augenfachleute sprechen. Langfristig könnten solche Werkzeuge das Screening in Regionen mit wenigen Augenärzten unterstützen, die Uneinigkeit zwischen Behandlern verringern und Patientinnen und Patienten helfen zu verstehen, warum eine Operation empfohlen wird oder nicht – und damit klarere Einsichten in eine Erkrankung bieten, deren Kennzeichen paradoxerweise der Verlust von Klarheit ist.
Zitation: Xie, Z., Ao, M., Tang, H. et al. A fine-grained fundus image dataset for cataract severity assessment and diagnosis. Sci Data 13, 418 (2026). https://doi.org/10.1038/s41597-026-06684-8
Schlüsselwörter: Katarakt, Fundusbildgebung, medizinische KI, Vision-Language-Modelle, Ophthalmologie-Datensatz