Clear Sky Science · de
Biomedical Data Manifest: Eine leichtgewichtige Daten-Dokumentationszuordnung zur Erhöhung der Transparenz für KI/ML
Warum intelligentere Datennotizen für Ihre Gesundheit wichtig sind
Während Krankenhäuser und Forschungsteams sich beeilen, künstliche Intelligenz zur Vorhersage von Krankheiten und Unterstützung von Behandlungen einzusetzen, bestimmt die Qualität der Daten, die diese Werkzeuge speisen, stillschweigend, wer profitiert — und wer womöglich zurückbleibt. Dieses Papier stellt eine praktische Methode vor, biomedizinische Datensätze „auf der Schachtel zu etikettieren“, sodass jeder, der KI-Systeme entwickelt, schnell erkennen kann, woher die Daten stammen, wen sie repräsentieren und wie sie genutzt — und nicht genutzt — werden sollten. Indem solche Dokumentation vereinfacht wird, verfolgen die Autorinnen und Autoren das Ziel, medizinische KI fairer, sicherer und vertrauenswürdiger zu machen.
Die verborgenen Geschichten in medizinischen Daten
Die meisten großen biomedizinischen Datensätze — Sammlungen von Laborwerten, Bildaufnahmen oder Behandlungsergebnissen — wurden nie mit Blick auf KI erstellt. Häufig fehlen klare Aufzeichnungen darüber, wie die Daten erhoben wurden, welche Patienten einbezogen wurden oder was im Laufe der Zeit verändert wurde. Diese fehlenden Details können Verzerrungen verbergen, etwa dass bestimmte Gruppen unterrepräsentiert sind oder wichtige Informationen inkonsistent erfasst wurden. Werden solche Daten zum Training von maschinellen Lernsystemen verwendet, funktionieren die resultierenden Werkzeuge möglicherweise für einige Patientinnen und Patienten gut, für andere jedoch schlecht und verstärken so vorhandene Versorgungslücken. Die Autorinnen und Autoren argumentieren, dass eine bessere, standardisierte Dokumentation notwendig ist, um diese Risiken zu entdecken und zu steuern, bevor Algorithmen eingesetzt werden.
Die besten Ideen in einem einfachen Leitfaden zusammenführen
In der KI‑Gemeinschaft existieren bereits mehrere Ansätze für „Daten‑Fact‑Sheets“, etwa Datasheets for Datasets, Data Cards und HealthSheets. Jeder bietet strukturierte Fragen zu Zweck, Inhalt, Erhebungsmethoden und Grenzen eines Datensatzes. Sie wurden jedoch überwiegend von Informatikerinnen und Informatikern für KI‑spezifische Datensätze entwickelt und können umfangreich und schwer zu bearbeiten für beschäftigte biomedizinische Forschende sein. Um das Rad nicht neu zu erfinden, kartierte und harmonisierte das Team zunächst Felder aus vier weithin zitierten Vorlagen und erstellte eine konsolidierte Liste von 136 Fragen, die die wichtigsten Konzepte erfasste und Überschneidungen entfernte. Diese Liste wurde dann auf 100 Felder verfeinert, die in sieben leicht verständliche Kategorien gruppiert sind — von Grundinformationen und der Nutzung der Daten bis hin zu Fragen wie Ethik, rechtliche Beschränkungen und wie Labels erstellt wurden.
Den Menschen zuhören, die Daten nutzen und erstellen
Anschließend baten die Forschenden reale biomedizinische Interessengruppen — darunter Klinikpersonal, Laborwissenschaftlerinnen und -wissenschaftler, Datenmanager sowie Rechenexpertinnen und -experten — zu bewerten, wie wesentlich jedes Dokumentationsfeld für ihre Arbeit ist. 23 Teilnehmende aus einem multizentrischen Krebsforschungsnetzwerk füllten die Umfrage aus. Das Team gruppierte die Befragten in zwei breite „Personas“: diejenigen, die näher an der Datenerhebung am Laborbank oder am Krankenbett stehen, und diejenigen, die hauptsächlich Daten verwalten, kuratieren oder analysieren. Das ergab klare Unterschiede in den Prioritäten. Zum Beispiel schätzten beide Gruppen stark, zu wissen, wann ein Datensatz zuletzt aktualisiert wurde und wann er sich wieder ändern könnte. Doch nur die Datenmanager und Rechenexpertinnen und -experten priorisierten stark Details dazu, wie Labels zugewiesen wurden oder wie zukünftige Aktualisierungen aussehen würden, während Klinikerinnen, Kliniker und Laborwissenschaftler mehr Wert auf beabsichtigte sowie ungeeignete Verwendungszwecke der Daten legten.
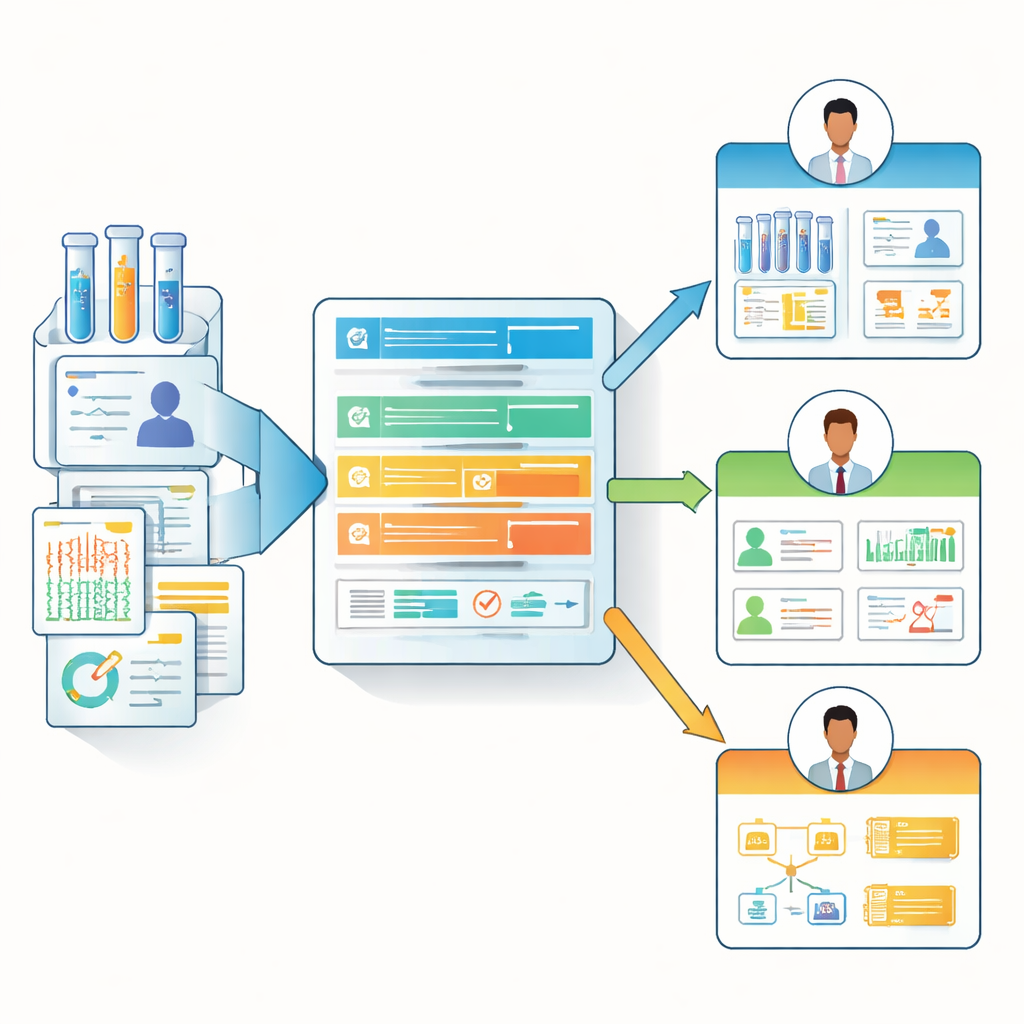
Von One‑Size‑Fits‑All zu rollenbewussten Datennotizen
Auf Basis dieser Umfrageerkenntnisse entwarfen die Autorinnen und Autoren das „Biomedical Data Manifest“, eine leichtgewichtige, webbasierte Dokumentationsvorlage, die sich an verschiedene Rollen anpasst. Anstatt jede Beitragende zu zwingen, eine umfangreiche Checkliste auszufüllen, verwendet das Manifest eine Hierarchie aus Kernfragen und optionalen, detaillierteren Fragen. Es kann die relevantesten Felder für jede Persona hervorheben — zum Beispiel die Datenherkunft und Aktualisierungsdetails für Analystinnen und Analytiker sichtbar machen, während für Forschende an vorderster Linie und Klinikerinnen/Kliniker der klinische Kontext und Einschränkungen betont werden. Das Team stellt ein gebrauchsfertiges Formular (z. B. in Microsoft Forms), eine HTML‑Darstellungsvorlage und ein Open‑Source‑R‑Paket namens BioDataManifest bereit. Diese Software kann Umfrageantworten automatisch in klare Manifestseiten umwandeln und sogar Informationen aus großen öffentlichen Repositorien wie dem Genomic Data Commons und dbGaP ziehen, um Teil‑Manifeste für bestehende Datensätze zu erstellen.
Was das für die zukünftige medizinische KI bedeutet
Das Biomedical Data Manifest ist letztlich ein praktisches Werkzeug, um das „Kleingedruckte“ biomedizinischer Datensätze leichter zu erstellen, zu teilen und zu verstehen. Indem die Dokumentation über Daten von der Dokumentation über spezifische KI‑Modelle getrennt und das Angezeigte an verschiedene Nutzerrollen angepasst wird, senkt das Framework die Belastung für Forschende und gibt nachgelagerten Nutzenden gleichzeitig den Kontext, den sie benötigen, um zu beurteilen, ob ein Datensatz für einen bestimmten Zweck geeignet ist. Anschaulich verwandelt es undurchsichtige medizinische Datensätze in klar etikettierte Pakete und hilft KI‑Entwickelnden, Einschränkungen und potenzielle Verzerrungen zu erkennen, bevor diese Patientinnen und Patienten betreffen. Bei breiter Adoption könnte diese rollenbewusste, wiederverwendbare Dokumentation die biomedizinische KI transparenter, reproduzierbarer und gerechter machen.
Zitation: Bottomly, D., Suciu, C.G., Cordier, B. et al. Biomedical Data Manifest: A lightweight data documentation mapping to increase transparency for AI/ML. Sci Data 13, 414 (2026). https://doi.org/10.1038/s41597-026-06670-0
Schlüsselwörter: biomedizinische Datendokumentation, verantwortliche KI in der Medizin, Datensatztransparenz, Bias bei maschinellem Lernen, Datenverwaltung