Clear Sky Science · de
Schätzung des bildungsbezogenen Perzentilrangs auf Gemeindeebene in China mit Multi-Quellen-Big-Data und maschinellem Lernen
Warum das Bildungsniveau Ihrer Nachbarschaft wichtig ist
Unser Wohnort prägt die Schulen, in die unsere Kinder gehen, die Sicherheit unserer Straßen und sogar den Wert unseres Hauses. Dennoch waren grundlegende Informationen darüber, wie gebildet verschiedene Nachbarschaften in China sind, lange nur schwer zugänglich. Diese Studie ändert das, indem sie Satellitenbilder, Straßenfotos und fortschrittliche Computeralgorithmen verwendet, um den relativen Bildungsstand von mehr als 120.000 Gemeinden im ganzen Land zu schätzen und damit eine neue Perspektive auf soziale Ungleichheit und urbanes Leben bietet.
Weiter denken als nur in Schuljahren
Die meisten Statistiken vergleichen Bildung, indem sie zählen, wie viele Jahre Menschen in die Schule gegangen sind. Das kann aber über Generationen hinweg irreführend sein. Ein Schulabschluss konnte früher jemanden an die Spitze seiner Altersgruppe bringen; heute haben viele ihrer Kinder Universitätsabschlüsse. Die Autorinnen und Autoren verwenden stattdessen einen „Perzentilrang der Bildung“, der angibt, wo eine Person innerhalb ihrer eigenen Jahrgangskohorte steht, von 0 (am wenigsten gebildet) bis 100 (am meisten gebildet). So kann eine ältere Person mit nur Hauptschulabschluss und eine jüngere Person mit Bachelorabschluss als ähnlich sozial positioniert gelten, wenn beide beispielsweise um den 70. Perzentil ihrer Generation liegen.
Städtische Landschaften als soziale Hinweise
Um Bildungs-Perzentilränge auf Gemeindeebene zu kartieren, griff das Team auf sechs Erhebungswellen einer großen nationalen Umfrage sowie auf eine breite Palette von „Big Data“ zurück, die die gebaute Umwelt beschreiben. Sie betrachteten, welche Art von Einrichtungen jede Nachbarschaft umgeben – Geschäfte, Schulen, Krankenhäuser, Parks und Büros – wie dicht Gebäude und Straßen sind, wie hell das Gebiet nachts auf Satellitenaufnahmen erscheint und wie viele Menschen sich typischerweise dort aufhalten. Aus Millionen von Street-View-Fotos nutzten sie Computer-Vision, um Grünflächen, Bürgersteige, Verkehr, Anzeichen von Verwahrlosung wie Müll oder Graffiti und sogar wie wohlhabend oder sicher eine Straße auf menschliche Beobachter wirkt, zu messen. Zudem flossen Geländemerkmale wie Höhe und Hangneigung ein, da steile oder abgelegene Gebiete oft in der Entwicklung zurückliegen. 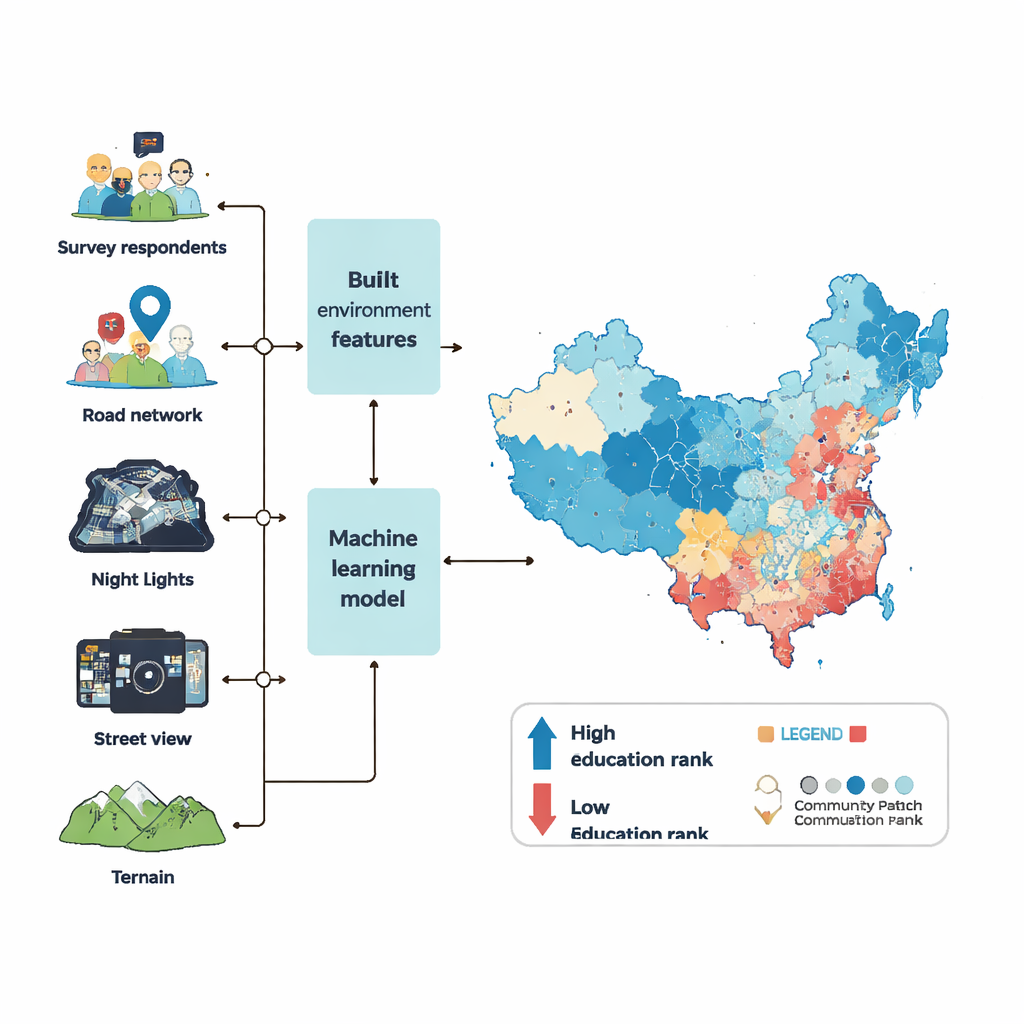
Maschinen das Lesen der Stadt beibringen
Mit diesen Merkmalen trainierten die Forschenden ein leistungsfähiges Modell des maschinellen Lernens (XGBoost genannt), um die Verbindung zwischen physischen Eigenschaften einer Gemeinde und dem durchschnittlichen Bildungs-Perzentilrang ihrer Bewohner zu lernen. Zunächst füllten sie Lücken in den Umweltdaten mittels eines sorgfältigen statistischen „Imputations“-Verfahrens, damit fehlende Werte die Ergebnisse nicht verzerren. Anschließend optimierten sie die internen Einstellungen des Modells durch Hunderte von Läufen und bewerteten die Leistung daran, wie gut das Modell Bildungsränge für Umfrage-Gemeinden vorhersagen konnte, die es zuvor nicht gesehen hatte. Das finale Modell konnte mehr als 90 Prozent der Unterschiede zwischen Gemeinden in den Testdaten erklären, mit nur geringen Fehlern – eine stärkere Leistung als vergleichbare Bemühungen in anderen Ländern.
Was die neue nationale Karte offenbart
Mit dem trainierten Modell sagten die Autorinnen und Autoren mittlere Bildungs-Perzentilränge für 122.126 Gemeinden im chinesischen Festland für das Jahr 2020 voraus, was den Großteil des städtischen Landes und etwa 85 Prozent der Bevölkerung abdeckt. Stadtzentren weisen im Allgemeinen die höchsten Bildungswerte auf, gefolgt von sekundären Knotenpunkten und dann entfernteren Vororten, obwohl jede Metropole ihr eigenes Muster hat. Pekings historischer Kern etwa beherbergt nicht die allerhöchsten Ränge, während sich Shenzhens hochgebildete Zonen über mehrere Zentren verteilen. Zur Überprüfung der Zuverlässigkeit verglich das Team seine Schätzungen mit offiziellen Volkszählungsdaten und, wo verfügbar, mit proprietären standortbasierten Dienstleistungsdaten. Auf Präfektur- und Kreisebene zeigen Gebiete mit höheren vorhergesagten Perzentilrängen auch höhere Schuljahresdurchschnitte in der Volkszählung. Auf Nachbarschaftsebene in Peking und Guangzhou stimmt ihre Karte eng mit sowohl Unternehmens- als auch Volkszählungsbenchmarks überein. 
Warum das im Alltag wichtig ist
Für politische Entscheidungsträger, Planerinnen und Planer sowie Forschende bietet dieser neue offene Datensatz ein detailliertes, aktuelles Bild von Bildungs- Vor- und Nachteilen in chinesischen Städten. Er kann genutzt werden, um zu untersuchen, wo sich bürgerliche Enklaven bilden, wie weit Gentrifizierung fortgeschritten ist oder welche Bezirke möglicherweise bessere Schulen, soziale Dienste oder öffentlichen Verkehr benötigen. Für allgemeine Leser ist die Kernbotschaft einfach: Indem man Straßen, Beleuchtung und Gebäude einer Nachbarschaft „liest“, können moderne Dateninstrumente deren soziale Stellung mit überraschender Genauigkeit annähern. Diese Arbeit ersetzt keine traditionellen Volkszählungen, liefert aber eine schnelle, kostengünstige Möglichkeit, die Lücken zwischen ihnen zu füllen und besser zu verstehen, wie die von uns gebauten Orte unsere sozialen Spaltungen widerspiegeln und verstärken.
Zitation: Zhang, Y., Pan, Z., You, Y. et al. Community-level education percentile rank estimation in China using multi-source big data and machine learning. Sci Data 13, 304 (2026). https://doi.org/10.1038/s41597-026-06664-y
Schlüsselwörter: Bildungsungleichheit, städtisches China, Big Data, maschinelles Lernen, Nachbarschaften