Clear Sky Science · de
Transformerbasierte Relationsextraktion und Konzeptnormalisierung mithilfe eines annotierten Korpus klinischer Studien
Ärzten helfen, schneller die richtigen Patienten zu finden
Jede klinische Studie hängt davon ab, Patienten zu finden, die eine lange Liste von medizinischen Bedingungen, Behandlungen und Zeitrahmen erfüllen. Heutzutage müssen Ärztinnen und Ärzte häufig elektronische Gesundheitsakten und Studienbeschreibungen von Hand durchlesen, was langsam und fehleranfällig ist. Dieser Artikel stellt eine große, sorgfältig geprüfte Sammlung spanischer Texte zu klinischen Studien vor und zeigt, wie moderne künstliche Intelligenz diese unstrukturierte Sprache in organisierte Daten verwandeln kann – ein Schritt hin zu schnelleren, gerechteren und präziseren medizinischen Forschungsprozessen.
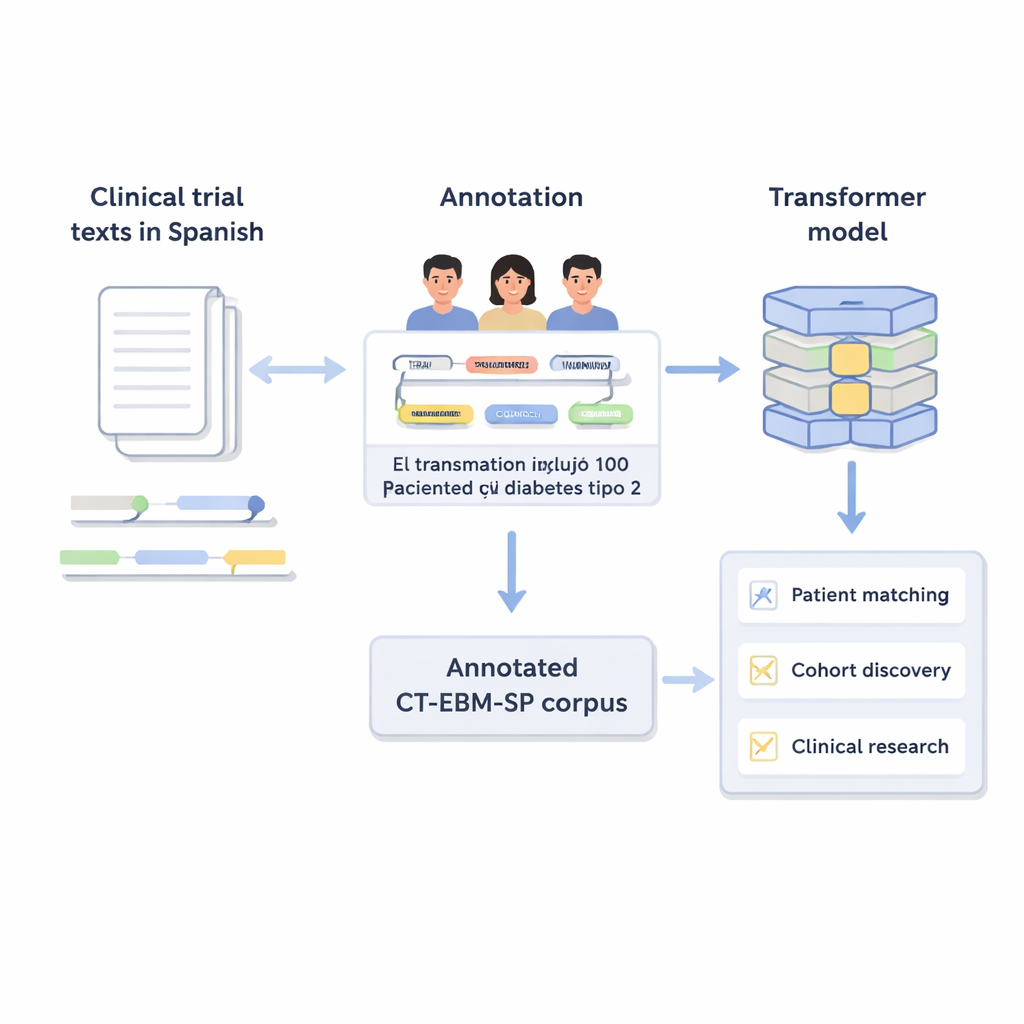
Freitext in strukturierte Informationen überführen
Klinische Studien beschreiben, wer teilnehmen darf und wer nicht, mit alltäglicher medizinischer Sprache: Altersgrenzen, frühere Erkrankungen, Laborwerte und bereits versuchte Behandlungen. Für Computer ist dieser freie Text schwer zu verarbeiten. Die Autoren erstellten Version 3 des CT‑EBM‑SP-Korpus, einen Datensatz mit 1.200 spanischen Texten zu klinischen Studien und insgesamt nahezu 300.000 Wörtern. Expertinnen und Experten markierten in diesen Texten 23 Typen medizinischer Entitäten, etwa Krankheiten, Medikamente, Testergebnisse und Zeitangaben, sowie Hinweise auf Negation (zum Beispiel „keine Vorgeschichte von“) und Unsicherheit. Außerdem wurden 11 Attribute annotiert, die Details erfassen, wie etwa ob ein Ereignis in der Vergangenheit oder Zukunft liegt und ob es den Patienten selbst oder ein Familienmitglied betrifft.
Medizinische Begriffe auf eine gemeinsame Sprache bringen
Eine große Herausforderung in der Medizin ist, dass dasselbe Konzept auf vielerlei Weise geschrieben werden kann. Um das zu lösen, verband das Team die meisten markierten Entitäten mit standardisierten Codes aus dem Unified Medical Language System (UMLS), einem umfangreichen mehrsprachigen medizinischen Wörterbuch. Dieser Schritt, Konzeptnormalisierung genannt, sorgt dafür, dass unterschiedliche Schreibweisen oder Formulierungen auf denselben eindeutigen Identifikator verweisen. Zum Beispiel werden mehrere Varianten von „25‑Hydroxyvitamin D“ alle auf ein einziges UMLS-Konzept abgebildet. Insgesamt enthält der Korpus über 87.000 Entitäten und mehr als 68.000 Relationen; rund 82 % der Entitäten konnten erfolgreich normalisiert werden. Zwei Expertinnen bzw. Experten überprüften diese Verknüpfungen unabhängig voneinander und erzielten eine sehr hohe Übereinstimmung, was die Zuverlässigkeit der Annotationen unterstreicht.
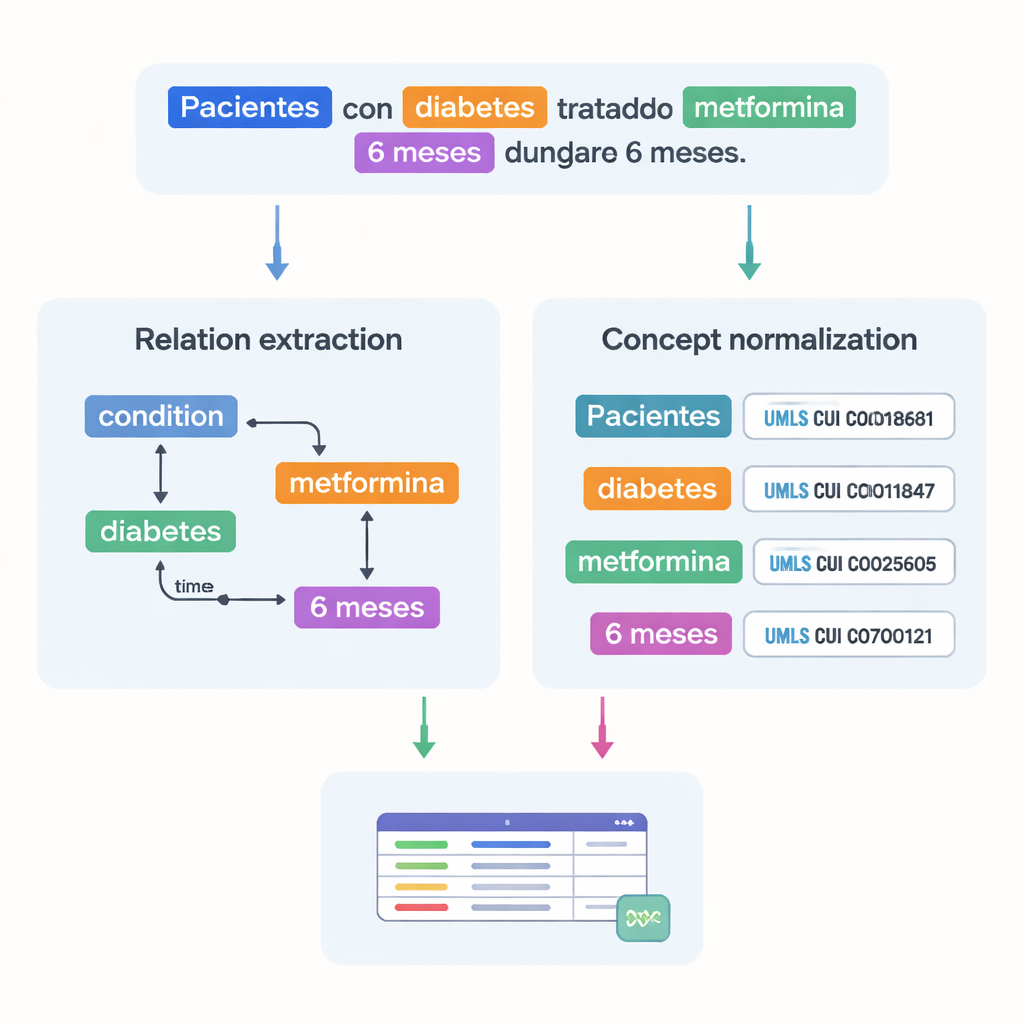
Wie medizinische Fakten zueinander in Beziehung stehen
Über die bloße Auflistung medizinischer Begriffe hinaus dokumentiert der Datensatz, wie diese miteinander verbunden sind. Die Autoren definierten 18 Relationstypen, um Muster abzubilden, die in Studien relevant sind, etwa welche Dosis zu welchem Medikament gehört, wie lange eine Behandlung dauert oder welche Erkrankung ein Patient hat. Temporale Relationen zeigen, ob ein Ereignis vor oder nach einem anderen stattfindet; andere Verknüpfungen kennzeichnen, wo eine Erkrankung im Körper auftritt oder ob eine Formulierung Negation oder Spekulation ausdrückt. Zusammen erlauben diese Relationen Computern, Graphen der Patientensituation zu bauen — wer der Patient ist, welche Erkrankung vorliegt, welche Behandlung angewendet wird und unter welchen zeitlichen Bedingungen — statt nur einzelne Wörter zu erkennen.
Training und Prüfung moderner KI-Modelle
Um zu zeigen, dass der Korpus praktisch nutzbar ist, fine‑tunten die Autoren mehrere transformerbasierte KI-Modelle, darunter mehrsprachige Versionen von BERT und RoBERTa. Sie trainierten diese Modelle für zwei Aufgaben: Relationsextraktion, bei der die Verknüpfungen zwischen Entitäten wiederhergestellt werden sollen, und medizinische Konzeptnormalisierung, die Text auf UMLS-Codes abbildet. Bei der Relationsextraktion erreichte das beste Modell einen F1‑Wert von knapp 0,88, was bedeutet, dass es die meisten Relationen korrekt identifizierte und vergleichsweise wenige Fehler machte. Für die Konzeptnormalisierung erriet ein mehrsprachiges Modell namens SapBERT, ohne zusätzliches Training, den richtigen Begriff beim ersten Versuch in fast 90 % der Fälle. Diese Ergebnisse zeigen, dass gut annotierte, mittelgroße Datensätze genaue und effiziente Modelle ermöglichen können, selbst ohne riesige allgemeine Sprachmodelle.
Warum diese Ressource für die künftige Versorgung wichtig ist
Der CT‑EBM‑SP-Korpus und die dazugehörigen Modelle bilden eine Grundlage für Werkzeuge, die spanische Texte zu klinischen Studien automatisch parsen, mit Patientenakten abgleichen und die Kohortensuche in Krankenhäusern unterstützen können. Da die Daten an internationale medizinische Standards angelehnt und von Expertinnen und Experten sorgfältig überprüft wurden, können sie auch bei der Entwicklung ähnlicher Ressourcen für andere Sprachen mit weniger digitalen Werkzeugen helfen. Alltagssprachlich geht es bei dieser Arbeit darum, es zu erleichtern und sicherer zu machen, dass die richtigen Patienten die passenden Studien angeboten bekommen, wodurch medizinische Entdeckungen beschleunigt und die Belastung für das Gesundheitspersonal reduziert werden.
Zitation: Campillos-Llanos, L., Valverde-Mateos, A., Capllonch-Carrión, A. et al. Transformer-based relation extraction and concept normalization using an annotated clinical trials corpus. Sci Data 13, 280 (2026). https://doi.org/10.1038/s41597-026-06608-6
Schlüsselwörter: klinische Studien, medizinisches Text Mining, spanisches Gesundheitswesen, Transformer-Modelle, evidenzbasierte Medizin