Clear Sky Science · de
Zeitlich aufgelöste Multiomik-Genexpressionsdaten während der Differenzierung humaner embryonaler Stammzell-abgeleiteter polyhormonaler Zellen
Wie Zellen lernen, Organe zu werden
Unser Körper beginnt als winzige Ansammlung ähnlicher Zellen, die auf irgendeine Weise lernen, sehr unterschiedliche Gewebe zu bilden – vom Gehirn bis zur Bauchspeicheldrüse. Diese Studie verfolgt diesen Lernprozess im Labor, indem menschliche embryonale Stammzellen Schritt für Schritt in frühe Pankreaszellen gelenkt werden. Durch die Verfolgung der Aktivität von Tausenden Genen über die Zeit auf mehreren Ebenen entsteht eine umfangreiche Referenzkarte, die Forschern helfen kann, die menschliche Entwicklung besser zu verstehen und langfristig Strategien zur Behandlung von Erkrankungen wie Diabetes zu verbessern.
Beobachtung, wie Stammzellen einen Weg wählen
Menschliche embryonale Stammzellen sind besonders, weil sie sich in nahezu jeden Zelltyp des Körpers verwandeln können. In dieser Studie leiteten die Forscher diese Stammzellen in eine bestimmte Richtung: eine pankreasspezifische Linie namens polyhormonale Zellen, die Schlüsselhormone wie Insulin und Glukagon produzieren können. Sie ahmten die frühe Entwicklung in einer Schale nach, indem sie das Nährmedium schrittweise änderten und die Zellen zunächst in einen primitiven darmähnlichen Zustand, das Endoderm, und dann über 17 Tage hinweg zu hormonproduzierenden Pankreaszellen führten. Proben wurden an zehn sorgfältig gewählten Zeitpunkten entnommen, um die gesamte Reise von flexiblen Stammzellen zu spezialisierten hormonproduzierenden Zellen zu erfassen. 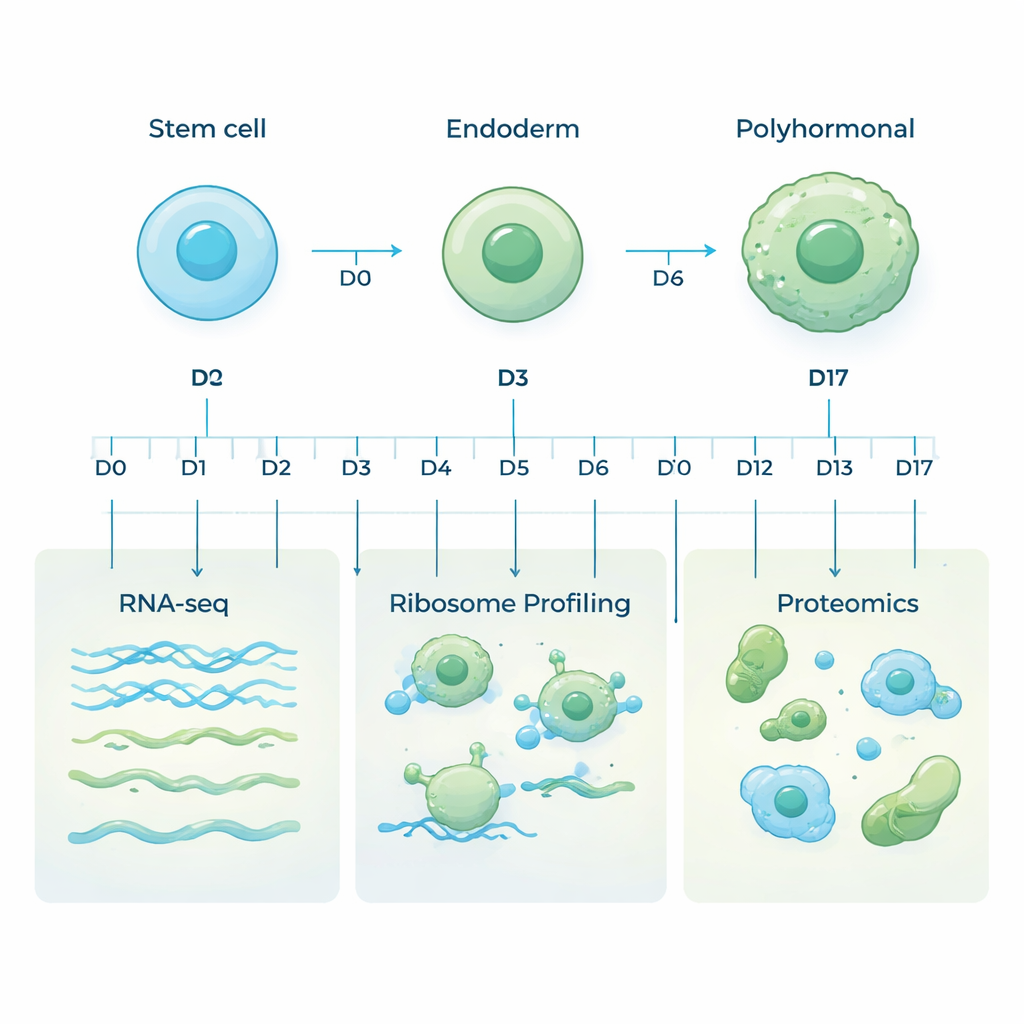
Ein Blick unter die Haube auf drei Ebenen
Die meisten Studien betrachten nur die Boten-RNA (mRNA), die die Anweisungen der Gene trägt. mRNA ist jedoch nur ein Teil der Geschichte: Nicht jede Nachricht wird in Protein übersetzt, und Proteine selbst können mit unterschiedlichen Raten gebildet oder abgebaut werden. Um ein vollständigeres Bild zu erhalten, wandte das Team drei komplementäre Ansätze an denselben Proben an. RNA-Sequenzierung ermittelte, welche Gene in mRNA transkribiert wurden. Ribosomprofilierung verfolgte, welche Botschaften aktiv von den eiweißbildenden Maschinen der Zelle gelesen wurden. Massenspektrometrie-basierte Proteomik maß schließlich die tatsächlich vorhandenen Proteine. Zusammengenommen zeigen diese Ebenen, wie Genaktivität kontrolliert wird, während sich Zellen in ihrer Identität verändern.
Verfolgen zentraler Signale der Zellidentität
Um zu prüfen, ob die Zellen den beabsichtigten Entwicklungsweg tatsächlich eingeschlagen hatten, überwachten die Wissenschaftler bekannte Markergene. Früh waren klassische Stammzellmarker wie OCT4 und NANOG hoch und verblassten dann mit dem Fortschreiten der Differenzierung. Als die Zellen in die Endoderm-Phase eintraten, stiegen Marker wie KIT und SOX17 an. In den Endstadien traten die polyhormonalen Marker Insulin (INS) und Glukagon (GCG) sowohl auf RNA- als auch auf Proteinebene deutlich hervor, was bestätigte, dass die Zellen eine pankreasähnliche, hormonproduzierende Identität angenommen hatten. Obwohl einer der biologischen Replikate diese Stadien etwas langsamer durchlief als das andere, folgten beide dem gleichen allgemeinen Verlauf, was auf kleine natürliche Unterschiede und nicht auf technische Probleme hindeutet. 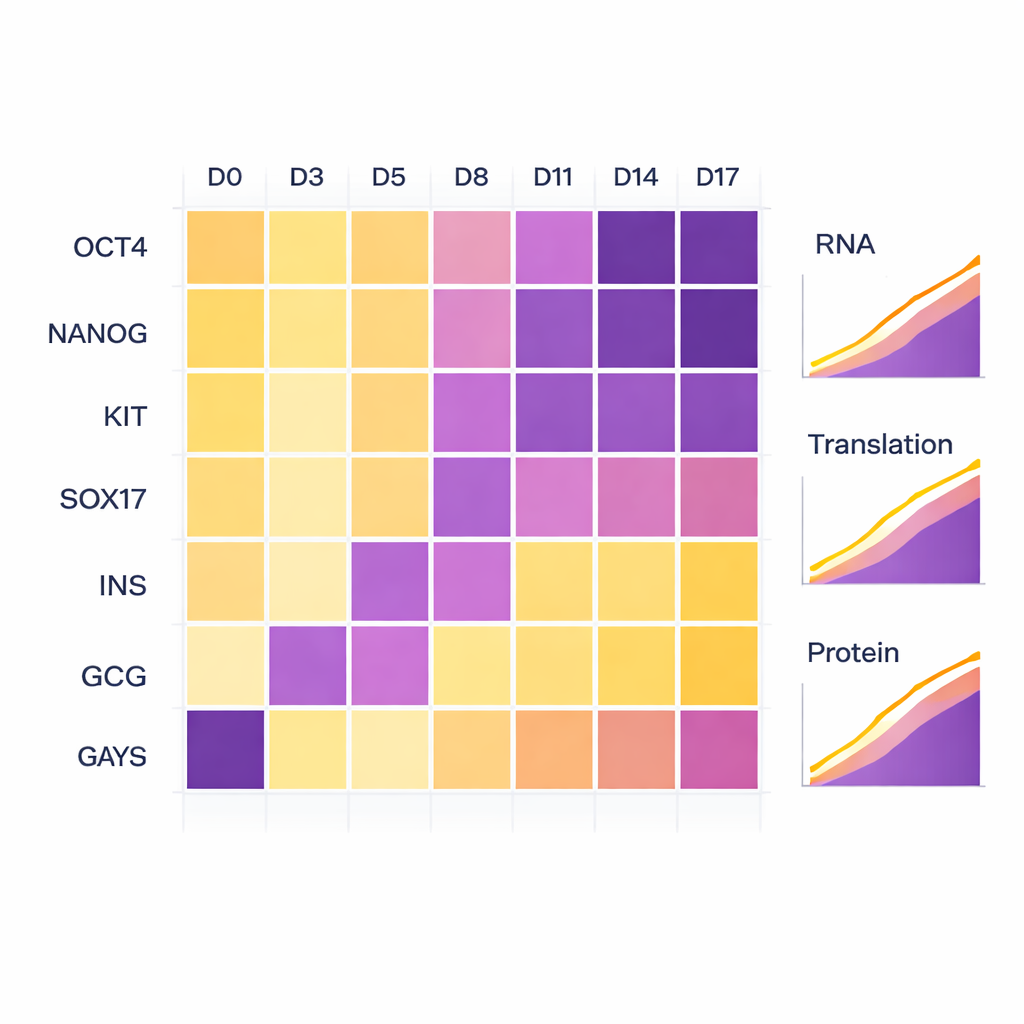
Qualitätsprüfungen für eine vertrauenswürdige Ressource
Da diese Arbeit als Gemeinschaftsressource dienen soll, investierten die Autoren umfangreiche Anstrengungen in die Überprüfung von Datenqualität und Konsistenz. Für jede der drei Methoden bewerteten sie Sequenzier- und Messgenauigkeit, Genabdeckung und die Übereinstimmung wiederholter Experimente. Stammzell- und polyhormonale Stadien zeigten klare und reproduzierbare Unterschiede auf RNA-, Translations- und Proteinebenen. Hauptkomponentenanalysen – statistische Karten, die ähnliche Proben gruppieren – zeigten, dass die Zeitpunkte in der richtigen Reihenfolge lagen, wobei frühe und späte Stadien deutlich getrennt und biologische Replikate eng beieinander gruppiert waren. Allein die Proteomik-Daten verfolgten zuverlässig fast 7.500 Proteine über alle Zeitpunkte hinweg, mit relativ wenigen fehlenden Messwerten, was die Tiefe des Datensatzes unterstreicht.
Eine Grundlage für zukünftige Entdeckungen
Die Autoren stellen alle Roh- und verarbeiteten Daten öffentlich zur Verfügung, zusammen mit Analyse-Skripten und Referenzdateien, sodass andere Forscher den Datensatz erneut verwenden und neu analysieren können. Über die Beschreibung hinaus, wie sich ein Zelltyp in einen anderen verwandelt, liefert diese Arbeit ein detailliertes, zeitaufgelöstes Bild davon, wie Genbotschaften, ihre Translation und die resultierenden Proteine während eines wesentlichen Entwicklungsübergangs miteinander interagieren. Für Nicht-Fachleute ist die zentrale Erkenntnis, dass das Zellschicksal durch mehrere Regulationsebenen gesteuert wird, die zeitlich abgestimmt zusammenwirken, und dass dieser Datensatz einen hochauflösenden „Film“ dieser Veränderungen bietet. Forscher können diese Ressource nun nutzen, um zu untersuchen, warum einige Gene früh und andere spät reagieren, wie verschiedene Organe ähnliche oder unterschiedliche Regeln befolgen könnten und wie man Stammzellen besser in medizinisch nützliche Richtungen lenkt.
Zitation: Keskin, A., Shayya, H.J., Patel, A. et al. Temporal multiomics gene expression data across human embryonic stem cell-derived polyhormonal cell differentiation. Sci Data 13, 278 (2026). https://doi.org/10.1038/s41597-026-06606-8
Schlüsselwörter: Stammzellen, Pankreasentwicklung, Genexpression, Multiomik, polyhormonale Zellen