Clear Sky Science · de
Filmszenen-Daten von Amazon X-Ray im US-Markt kombiniert mit IMDb
Warum Filmszenen wichtig sind, um Kultur zu verstehen
Filme prägen unsere Weltsicht, doch die meisten Studien konzentrieren sich auf Einspielergebnisse, grobe Genres oder Star-Power – nicht darauf, was tatsächlich von Szene zu Szene auf der Leinwand passiert. Dieser Beitrag stellt einen neuen Datensatz vor, der Forschenden erlaubt, auf Ebene einzelner Szenen, Figuren und Dialogzeilen zu arbeiten: mehr als 3.000 Filme, die in den USA über Amazon Prime Video gestreamt wurden. Durch die Kombination von Amazons X-Ray-Funktion mit der Internet Movie Database (IMDb) liefern die Autor:innen eine detaillierte, standardisierte Karte darüber, wer in welchem Moment eines Films zu sehen ist – und schaffen so die Grundlage für tiefere Untersuchungen von Repräsentation, Erzählstrukturen und sogar auf Video trainierten KI-Systemen.
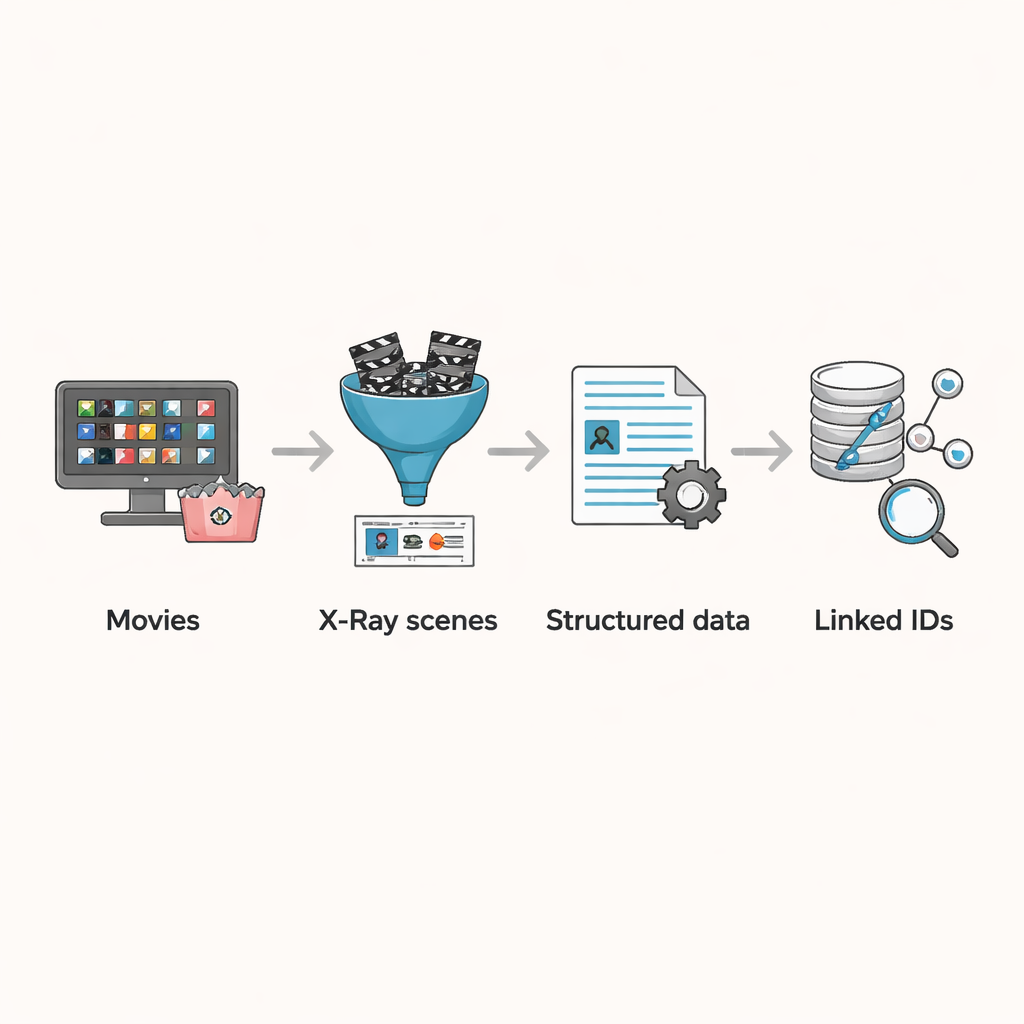
Von Rohdrehbüchern zu fertigen Szenen
Bisher stützten sich die meisten groß angelegten Filmstudien auf Drehbücher oder Untertiteldateien. Diese Quellen sind nützlich, aber unvollkommen. Drehbücher sind oft frühe Fassungen, die sich vom Finalcut unterscheiden können, und sie lassen kleinere Figuren oder späte Schnittänderungen aus. Untertitel erfassen gesprochene Zeilen, übersehen aber stille Figuren, Statisten im Hintergrund und rein visuelle Erzählmomente – etwa eine Kamera, die im Gesicht einer Figur verweilt. Wegen dieser Lücken mussten früher Versuche, zu verfolgen, wer mit wem auf der Leinwand interagiert oder wie verschiedene Gruppen dargestellt werden, häufig allein aus Textdaten schlussfolgern, was zu Fehlern bei der Figuren- und Beziehungsidentifikation führen kann.
X-Ray in forschungsfertige Daten verwandeln
Amazons X-Ray-Funktion schafft einen Ausweg aus diesen Problemen. Wenn Zuschauer:innen einen Film pausieren, zeigt X-Ray, welche Schauspieler:innen und Figuren gerade auf dem Bildschirm sind – Informationen, die kuratiert sind und direkt an den finalen Schnitt des Films gebunden sind. Die Autor:innen entwickelten eine Pipeline, um diese szenengenauen Daten für 3.265 Filme zu erheben, die im August 2023 im US-Prime-Video-Katalog verfügbar waren. Zunächst sammelten sie alle im Prime enthaltenen Filme, filterten Einträge ohne X-Ray-Informationen heraus und entfernten Duplikate durch wiederholte Titel oder alternative Versionen. Für jeden verbleibenden Film fingen sie die Datenströme ab, die der Player zum Laden von X-Ray- und Untertitelinformationen verwendet, und speicherten die Ergebnisse in strukturierten Dateien, die Szenengrenzen, die in jeder Szene vorhandenen Figuren und für die meisten Titel die exakten Zeitangaben jeder Untertitelsegment enthalten.
Szenen mit der weiteren Filmwelt verknüpfen
Die eigentliche Stärke des Datensatzes liegt in der Verknüpfung dieser Szenenaufschlüsselungen mit externen Informationen. Während X-Ray bereits jede Figur mit einem IMDb-Profil verknüpft, enthält es keine IMDb-ID für den Film selbst. Die Autor:innen entwickelten einen Abgleichsalgorithmus, der vom Filmtitel ausgeht, mehrere Kandidaten aus IMDb abruft und dann die dort gelistete Hauptbesetzung mit den in den X-Ray-Daten genannten Schauspieler:innen vergleicht. Überlappt mindestens eine relevante Person, gilt der Film als Übereinstimmung. Dieser automatisierte Prozess fand die überwiegende Mehrheit der Filme korrekt; die verbleibenden wenigen hundert Randfälle wurden anschließend manuell geprüft, Fehlklassifikationen korrigiert und Einträge entfernt, die keine erzählerischen Filme waren – etwa Stand-up-Specials. Das Endergebnis ist ein sorgfältig bereinigter Bestand an Filmen, in dem jede Szene, Figur und jeder Untertitel mit reichhaltigen Metadaten wie Jahr, Herkunftsland und demografischen Angaben zur Besetzung verknüpft werden kann.
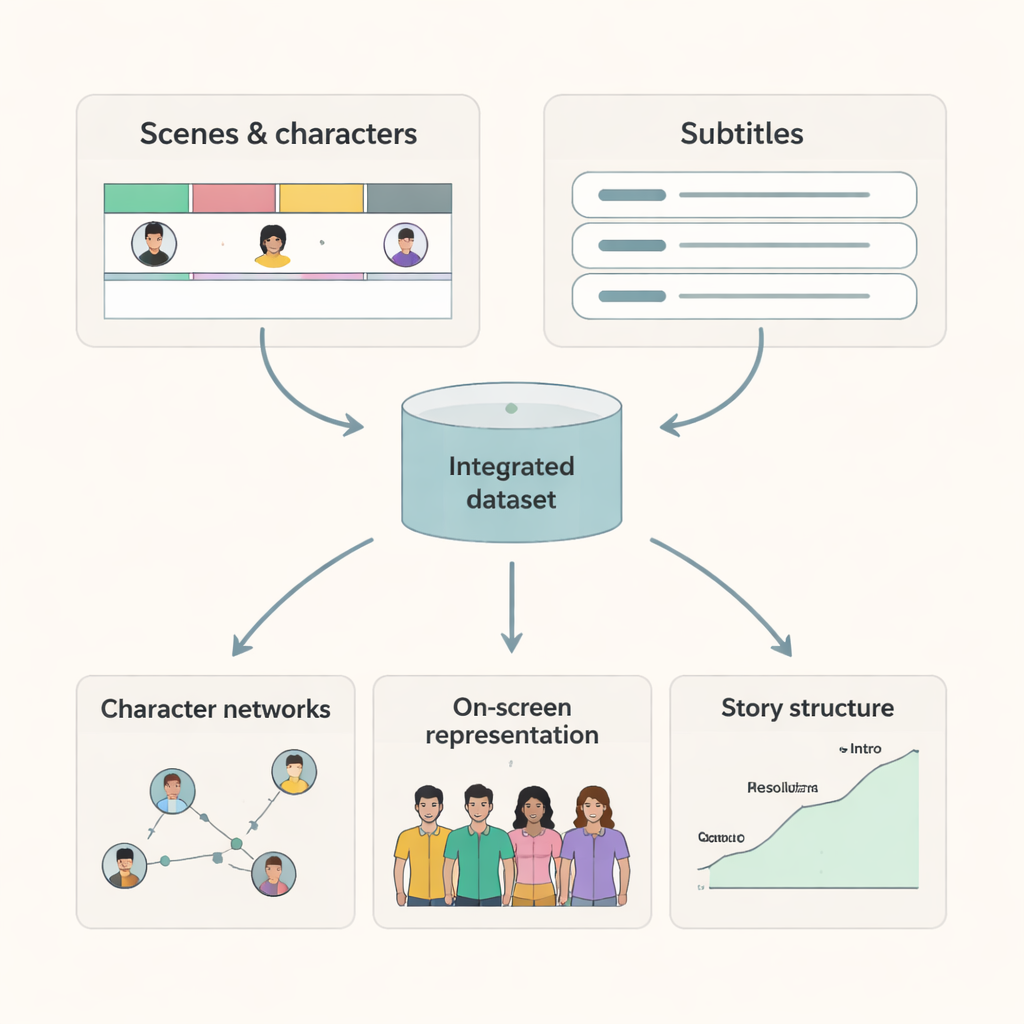
Was Forschende mit diesen Filmen tun können
Da jede Szene klare Start- und Endzeiten sowie eine Liste der Anwesenden aufweist, können Forschende nun präzise Karten von Figureninteraktionen und Screen Time erstellen. Mit Szenen abgeglichene Untertitel ermöglichen Studien darüber, wie sich Sprache zwischen Figuren und Kontexten unterscheidet oder wie bestimmte Themen sich dialogisch entfalten. In Kombination mit weiteren Informationen aus IMDb und anderen Quellen können Wissenschaftler:innen Fragen untersuchen wie: Wie hat sich das Geschlechterverhältnis auf der Leinwand über Jahrzehnte verändert? Erhalten Figuren unterschiedlicher Herkunft gleichwertige narrative Aufmerksamkeit? Wie unterscheiden sich Interaktionsmuster zwischen Genres oder Ländern? Der Datensatz bietet außerdem ein hochwertiges Benchmark für KI-Modelle, die Videoinhalte verstehen sollen, weil er Ground-Truth-Angaben dazu liefert, wer sichtbar ist und wann.
Eine neue Perspektive auf alltägliche Filme
Einfach gesagt verwandelt diese Arbeit Tausende von Filmen in einen durchsuchbaren Katalog, Szene für Szene, darüber, wer auftaucht, wer spricht und wie Geschichten strukturiert sind. Zwar beschränkt sich die Sammlung auf Titel, die in US-Prime Video verfügbar sind, und ist abhängig von Amazons internen X-Ray-Prozessen, dennoch deckt sie Filme aus vielen Jahrzehnten und Genres ab, nicht nur berühmte Preisträger. Diese Breite erlaubt es Forschenden, alltägliche Filme zu untersuchen – nicht nur die Klassiker, die im Gedächtnis bleiben. Mit weiteren Updates und Erweiterungen verspricht der Datensatz, unser Verständnis davon zu vertiefen, wie Filme Gesellschaft widerspiegeln – und Sozialwissenschaftler:innen wie Technolog:innen ein treueres Bild dessen zu liefern, was tatsächlich auf der Leinwand passiert.
Zitation: Shrestha, S., Heo, Y., Barron, A.T.J. et al. Scene-level movie data from Amazon X-Ray in the US market combined with IMDb. Sci Data 13, 275 (2026). https://doi.org/10.1038/s41597-026-06602-y
Schlüsselwörter: Filmdatensätze, Szenenanalysen, Amazon X-Ray, IMDb-Metadaten, On-Screen-Darstellung