Clear Sky Science · de
Rekonstruktion extremer Meeresspiegel an der Küste Chinas mit mehreren Deep-Learning-Modellen
Warum Küstenwasserstände den Alltag beeinflussen
Chinas lange Küstenlinie ist Heimat von mehreren Hundert Millionen Menschen, wichtigen Häfen und schnell wachsenden Städten. Wenn starke Stürme das Meer landeinwärts drücken, können die resultierenden hohen Wasserstände Stadtteile überfluten, Infrastruktur beschädigen und Trinkwasser mit Salz verseuchen. Detaillierte Aufzeichnungen über solche extremen Küstenwasserstände sind jedoch überraschend rar und fragmentiert. Diese Studie schließt diese Lücke, indem sie fünfzig Jahre täglicher Höchstwasserstände entlang großer Teile der chinesischen Küste rekonstruiert und moderne KI-Werkzeuge verwendet, um lückenhafte Beobachtungen und Wetter-Reanalysedaten in einen konsistenten, öffentlich verfügbaren Datensatz zu überführen.
Die Zunahme und Abnahme des Meeresspiegels verfolgen
Küstenwasserstände werden von zwei Hauptfaktoren bestimmt: der regelmäßigen Anziehung von Mond und Sonne, die die Gezeiten erzeugt, und Sturmfluten, zeitlich begrenzten Wasserwülsten, die bei Tiefdruck und starken Winden durch Zyklone und andere Wetterereignisse an Land gedrückt werden. In China fallen tropische Wirbelstürme und andere Stürme oft mit bereits hohen Gezeiten zusammen, was besonders gefährliche Bedingungen schafft. Viele Pegelstationen, die den Meeresspiegel messen, haben allerdings nur kurze oder unterbrochene Aufzeichnungen, und manche Daten sind nicht öffentlich zugänglich. Das erschwert es Wissenschaftlern und Planern zu verstehen, wie extreme Meeresspiegel von Ort zu Ort und von Jahrzehnt zu Jahrzehnt entlang dieser stark exponierten Küste variieren.
Mit intelligenten Modellen Lücken füllen
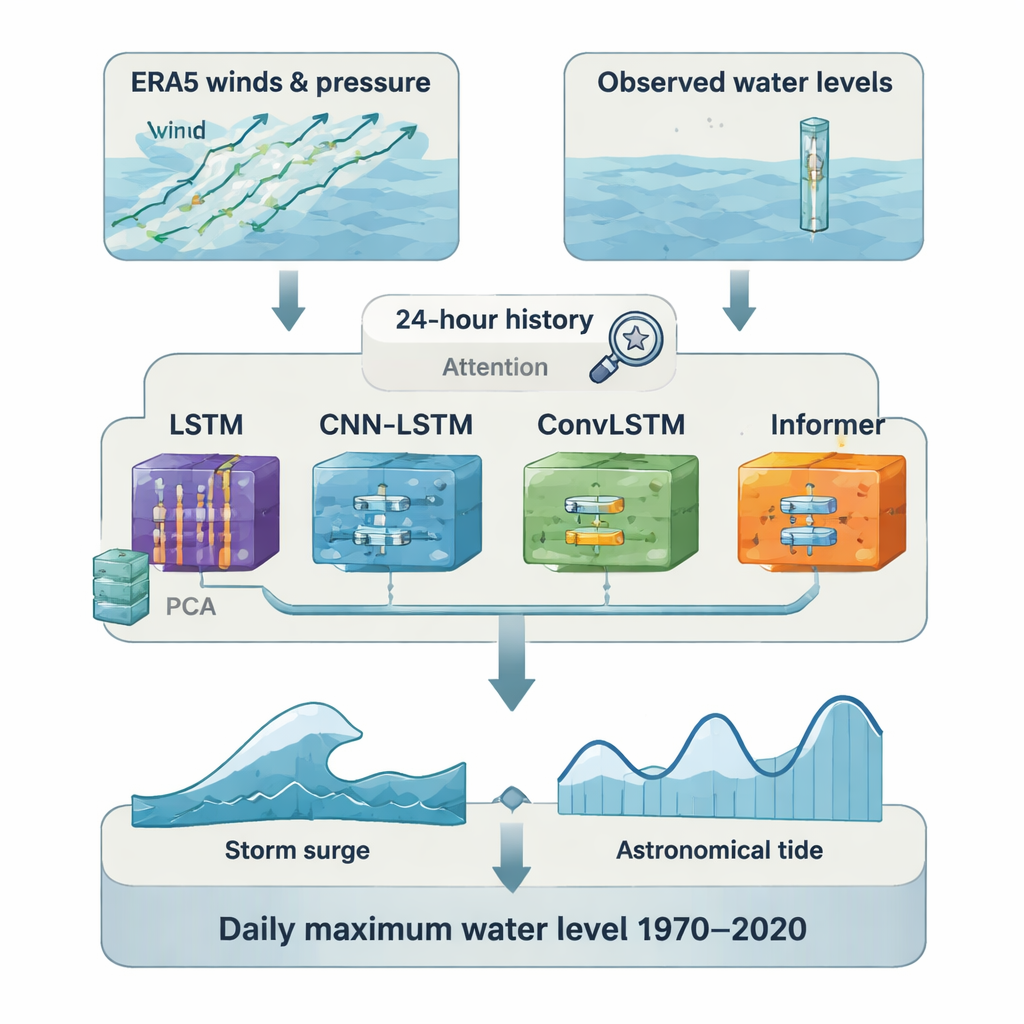
Die Autoren gingen das Problem an, indem sie moderne Deep-Learning-Techniken mit traditioneller Gezeitenanalyse kombinierten. Sie konzentrierten sich auf 23 Pegelstationen entlang der chinesischen Küste und sammelten detaillierte Wetterdaten aus der globalen Reanalyse ERA5, darunter Luftdruck und bodennahe Winde über ein 10×10-Grad-Feld um jede Station. Diese Wetterfelder wurden genutzt, um verschiedenen Typen neuronaler Netze beizubringen, wie tägliche maximale Sturmfluten mit der umgebenden Atmosphäre zusammenhängen. Gleichzeitig nutzte das Team ein Werkzeug namens UTide, um die vorhersehbaren Gezeitensignale aus den historischen Meeresspiegelaufzeichnungen zu extrahieren, sodass sie das regelmäßige An- und Absteigen der Gezeit vom unregelmäßigeren Flutanteil trennen konnten.
Verschiedene Varianten des Deep Learning testen
Statt sich auf einen einzigen Algorithmus zu verlassen, verglich die Studie systematisch vier Deep-Learning-Modelle: ein Long Short-Term Memory (LSTM)-Netzwerk, ein hybrides CNN-LSTM, das zunächst räumliche Muster erfasst, ein ConvLSTM, das Raum und Zeit zusammen verarbeitet, und ein Informer-Modell, das auf der in der Sprachverarbeitung verbreiteten Transformer-Architektur basiert. Um die Modelle effizient zu halten, komprimierten die Forschenden die umfangreichen Wetterfelder vor dem Training mittels Hauptkomponentenanalyse. Sie fütterten zudem jedes Modell mit einer 24-stündigen Historie der atmosphärischen Bedingungen und verwendeten Aufmerksamkeitsmechanismen, damit das Netz sich auf die wichtigsten Zeitpunkte konzentrieren kann. Für jede Station reservierten sie etwa 20 % der Aufzeichnung als unabhängige Testperiode und wählten das Modell, das dort am besten abschnitt, für die endgültige Rekonstruktion aus.
Fünfzig Jahre hoher Wasserstände rekonstruieren
Nachdem die Modelle trainiert waren, nutzten die Forschenden das jeweils bestperformende Modell an jedem Standort, um tägliche maximale Sturmfluten für den gesamten Zeitraum 1970–2020 zu rekonstruieren. Diese Schätzungen der Sturmfluten wurden dann zu den entsprechenden astronomischen Gezeiten aus UTide addiert, um tägliche maximale Gesamtwasserstände zu erzeugen. Da die höchste Flut und die höchste Sturmflut an einem Tag meist zu leicht unterschiedlichen Zeiten auftreten, stellt diese einfache Addition eine obere Abschätzung dessen dar, was tatsächlich geschah; Tests mit stündlichen Daten legen nahe, dass diese Überschätzung im Mittel etwa 15 Zentimeter bzw. rund 15 % beträgt. Selbst mit dieser konservativen Verzerrung stimmen die rekonstruierten Serien dort, wo Beobachtungen vorliegen, eng mit den Messungen überein: Im Mittel liegt die Korrelation zwischen rekonstruierten und beobachteten täglichen Maxima bei etwa 0,9, und die Fehler betragen Größenordnungen von einigen zig Zentimetern, auch bei sehr hohen Wasserständen oberhalb des 95. Perzentils.
Was das für Küsten und Gemeinschaften bedeutet
Für Wissenschaftler, Ingenieure und Küstenplaner liefert der neue Datensatz ein detailliertes, konsistentes Bild darüber, wie sich extreme Meeresspiegel in den letzten fünf Jahrzehnten entlang der chinesischen Küste verhalten haben. Er übertrifft mehrere weit verbreitete globale Produkte, insbesondere bei Taifunen und anderen Extremereignissen, und wird mit vollständigen Metadaten, Code und Leistungskennzahlen bereitgestellt, sodass andere ihn wiederverwenden und überprüfen können. Für die breite Öffentlichkeit bedeutet diese Arbeit, dass Bewertungen von Überflutungsrisiken, Deichkonstruktionen, Evakuierungsplänen und langfristiger Anpassung nun auf deutlich reichhaltigeren Informationen basieren können als zuvor. Kurz gesagt: Indem Computer „nachspielen“ gelernt haben, wie sturmgetriebene Höchstwasserstände sich über Jahrzehnte verhalten, bietet die Studie eine stärkere wissenschaftliche Grundlage zum Schutz von Küstengemeinden vor heutigen Gefahren und zur Vorbereitung auf den künftigen Meeresspiegelanstieg.
Zitation: Fang, J., Huang, J., Bian, W. et al. Reconstruction of Extreme Sea Levels in coastal China using Multiple Deep Learning models. Sci Data 13, 268 (2026). https://doi.org/10.1038/s41597-026-06593-w
Schlüsselwörter: Sturmflut, extremer Meeresspiegel, Küstenüberflutung, Deep Learning, Chinas Küstenlinie