Clear Sky Science · de
CNeuroMod-THINGS, ein dicht gesampeltes fMRT‑Datenset für die visuelle Neurowissenschaft
Warum das Anschauen von Bildern verrät, wie unser Geist arbeitet
Jeden Tag nehmen unsere Augen Tausende von Bildern auf – von Kaffeetassen und Smartphones bis hin zu Hunden, Bäumen und belebten Straßen. Im Verborgenen erkennt unser Gehirn rasch, was wir sehen, und speichert vieles davon oft später im Gedächtnis. Das CNeuroMod-THINGS‑Projekt hatte zum Ziel, diese verborgene Aktivität bis ins Detail einzufangen und damit eines der am dichtesten gemessenen Gehirndatensätze zu schaffen, die jemals beim Betrachten realer Bilder erhoben wurden. Diese Ressource soll die nächste Generation von Gehirn‑ und KI‑Forschung antreiben.
Aufbau einer umfangreichen Bibliothek von Gehirnantworten
Statt Hunderte von Freiwilligen ein- oder zweimal zu scannen, untersuchten die Forscher wiederholt nur vier besonders engagierte Teilnehmende. Jede Person kam 33 bis 36 Mal wieder, was sich auf rund 200 Stunden Bildgebung im größeren CNeuroMod‑Projekt summierte, davon Dutzende Stunden allein für Bilder. Während dieser Sitzungen sahen die Versuchspersonen bis zu 4.320 verschiedene Fotografien aus der THINGS‑Bildersammlung, die 720 alltägliche Objektkategorien wie Werkzeuge, Tiere, Fahrzeuge und Möbel abdeckt. Diese sorgfältige Bildauswahl stellt sicher, dass viele Bereiche unserer visuellen Welt repräsentiert sind und nicht nur einige wenige populäre Objekte.

Ein Erinnerungs‑Spiel im MRT‑Scanner
Um die Teilnehmenden bei der Sache zu halten und das Gedächtnis zu prüfen, verwandelten die Forschenden das Bildbetrachten in ein fortlaufendes Erkennungs‑Spiel. In jedem Durchgang erschien ein einzelnes Bild in der Bildschirmmitte, während die Person im MRT‑Scanner lag. Mit einem speziell angefertigten, videospielähnlichen Controller gaben die Teilnehmenden an, ob sie glaubten, das Bild sei neu oder schon zuvor gesehen worden, und wie sicher sie sich dabei waren. Die meisten Bilder wurden dreimal gezeigt: einmal beim ersten Kontakt, ein weiteres Mal ein paar Minuten später in derselben Sitzung und ein drittes Mal in einer späteren Sitzung, oft etwa eine Woche auseinander. Dieses Design erlaubte es dem Team, Kurzzeit‑ und Langzeitgedächtnis für exakt dieselben Bilder zu vergleichen und zugleich die entsprechenden Veränderungen in der Gehirnaktivität zu verfolgen.
Erfassung detaillierter Signale von Sehvermögen und Gedächtnis
Der Datensatz geht weit über einfache „An/Aus“‑Messungen der Gehirnaktivität hinaus. Die Autoren verwendeten fortgeschrittene Analysemethoden, um für jeden einzelnen Versuch und jedes Bild eine separate Antwort in jedem winzigen dreidimensionalen Pixel (Voxel) des Scans zu schätzen. Sie verfolgten außerdem mit Eye‑Tracking‑Kameras, wohin die Teilnehmenden blickten, überwachten Atmung und Herzfrequenz und maßen Kopfbewegungen. Qualitätskontrollen zeigen, dass die Signale bemerkenswert stabil sind: Die Teilnehmenden reagierten in fast jedem Durchgang, hielten ihren Blick nahe der Bildschirmmitte und bewegten sich nur wenig. In wichtigen visuellen Arealen – Regionen, die bekanntermaßen stark auf Gesichter, Körper oder Szenen ansprechen – erzeugte dasselbe Bild bei jeder Präsentation hochkonsequente Aktivitätsmuster. Diese Muster waren so deutlich, dass beim Auftragen der Antworten in einer vereinfachten zweidimensionalen Darstellung Bilder mit ähnlicher Bedeutung (beispielsweise Tiere oder Fahrzeuge) dazu neigten, zusammenzuklumpen.
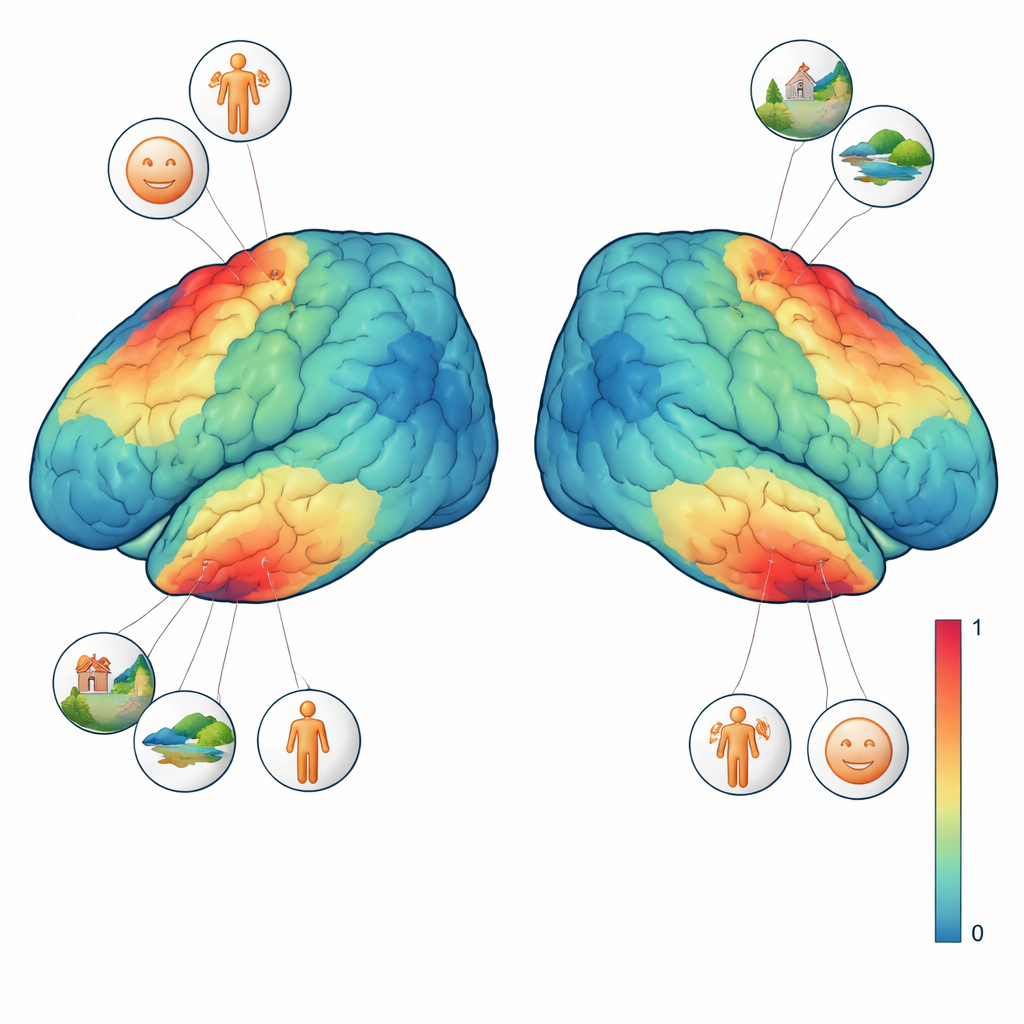
Aufzeigen dessen, worauf unterschiedliche Gehirnregionen achten
Um diese Signale besser zu interpretieren, absolvierten drei der vier Teilnehmenden zusätzliche Sehtests. In einem Test bewegten sich ausgedehnte Formen über einen strukturierten Hintergrund, um zu zeigen, welchen Teil des Gesichtsfelds jede Gehirnregion „sieht“. In einem anderen wurden kurze Blöcke mit Gesichtern, Orten, Körperteilen, Figuren und allgemeinen Objekten gezeigt, um Regionen zu lokalisieren, die eine bestimmte Bildart gegenüber anderen bevorzugen. Durch die Kombination dieser Localizer‑Aufgaben mit dem Hauptexperiment konnte das Team präzise Fragen stellen wie: Reagiert ein einzelnes Voxel stärker, wenn ein Gesicht vorhanden ist, oder wenn die gesamte Szene sichtbar ist? Sie fanden heraus, dass gesichtsselektive Regionen am stärksten antworteten, wann immer irgendeine Art von Gesicht auftrat, während eine szene‑selektive Region Bilder mit reichen Hintergründen wie Zimmern, Straßen oder Landschaften bevorzugte – selbst wenn keine Menschen sichtbar waren. Diese feingranularen Präferenzen zeigten sich auf Ebene einzelner Bilder und sogar einzelner Voxel.
Eine Grundlage für intelligentere Modelle des Sehens
Im Kern ist CNeuroMod-THINGS eine sorgfältig kuratierte öffentliche Ressource und kein einmaliges Ergebnis. Alle Gehirndaten, Eye‑Tracking‑Daten, Verhaltensreaktionen, Bildannotationen und Analyse‑Codes werden unter einer offenen Lizenz frei verfügbar gemacht. Da dieselben vier Personen in vielen anderen Aufgaben gescannt wurden – beim Anschauen von Filmen, beim Spielen von Videospielen, beim Zuhören von Geschichten – können Forschende jetzt detaillierte, personenbezogene Modelle erstellen, die kontrollierte Experimente mit natürlicheren Erfahrungen verknüpfen. Für Nicht‑Spezialisten lautet die Quintessenz: Wir verfügen nun über eine hochauflösende „Lookup‑Tabelle“, die zeigt, wie ein menschliches Gehirn auf Tausende alltäglicher Bilder reagiert. Das wird Wissenschaftlern helfen, Theorien zur visuellen Wahrnehmung und zum Gedächtnis zu testen und das Design künstlicher Sehsysteme zu leiten, die die Welt etwas mehr so sehen, wie wir sie wahrnehmen.
Zitation: St-Laurent, M., Pinsard, B., Contier, O. et al. CNeuroMod-THINGS, a densely-sampled fMRI dataset for visual neuroscience. Sci Data 13, 141 (2026). https://doi.org/10.1038/s41597-026-06591-y
Schlüsselwörter: fMRT, visuelle Wahrnehmung, Objekterkennung, Gehirndaten, Gedächtnis