Clear Sky Science · de
Semantische Angleichung des Metadatamodells des German Human Genome-Phenome Archive im europäischen Genomikfeld
Warum das Teilen von Genomdaten mehr braucht als nur Dateien
Die moderne Medizin stützt sich zunehmend darauf, unsere DNA zu lesen, um Krankheiten zu diagnostizieren und Behandlungen zu individualisieren. Die echte Stärke der Genomik zeigt sich jedoch, wenn Daten aus vielen Kliniken und Ländern kombiniert werden können. Das funktioniert nur, wenn jeder Datensatz klar und kompatibel beschrieben ist und Datenschutzgesetze wie die europäische DSGVO strikt eingehalten werden. Dieser Artikel erläutert, wie das German Human Genome-Phenome Archive (GHGA) ein detailliertes „Beschreibungs‑System“ für genomische Studien aufbaut, damit wertvolle Daten in Europa gefunden, verstanden und sicher geteilt werden können.
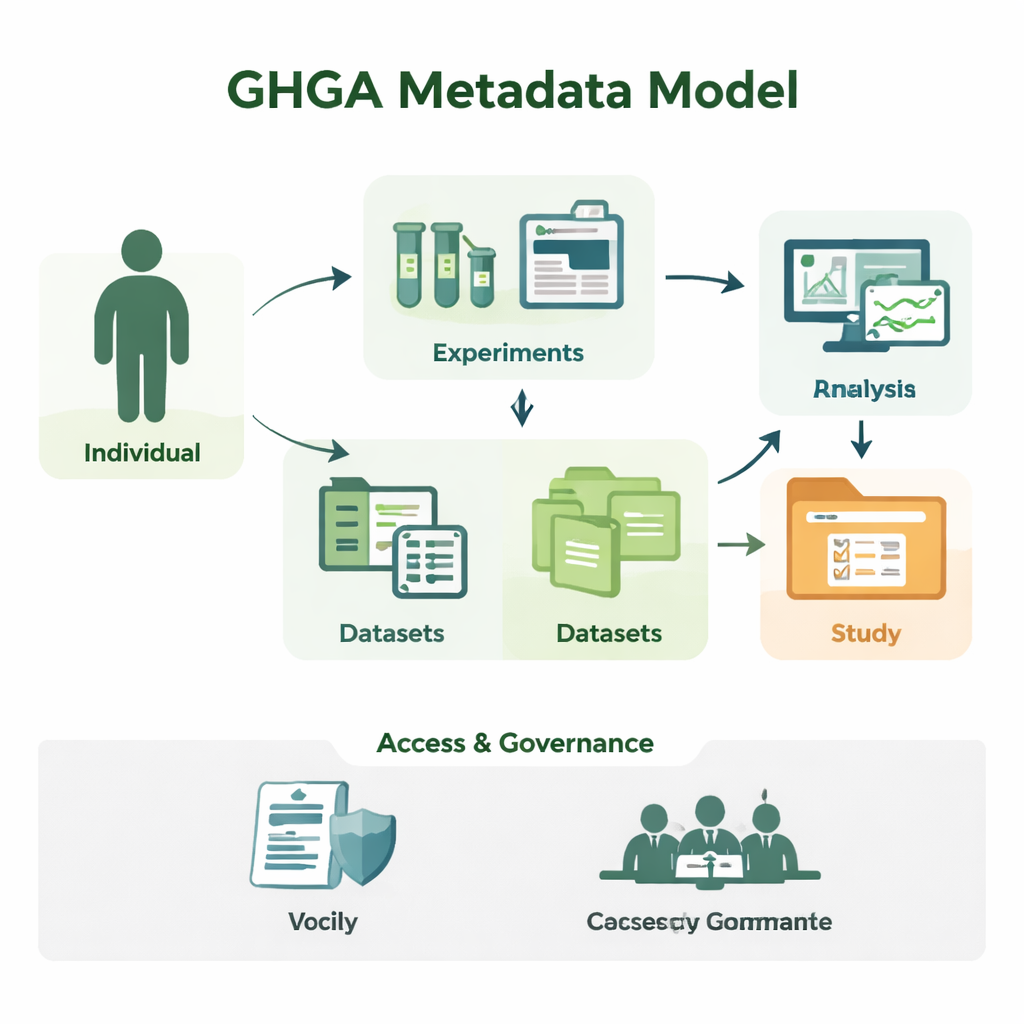
Von Rohsequenzen zu verständlichen Studien
Die Genomforschung erzeugt enorme Mengen an Sequenzdaten, aber eine Datei mit DNA‑Buchstaben für sich allein ist bedeutungslos. Forschende müssen wissen, von wem die Probe stammt, welches Gewebe verwendet wurde, wie das Experiment durchgeführt wurde und unter welchen Bedingungen die Daten wiederverwendet werden dürfen. GHGA erfasst diese Begleitinformationen als Metadaten. Sein Modell ordnet Metadaten in 16 Bausteine, etwa die am Studium teilnehmende Person (das „Individuum“), die entnommene Probe, das durchgeführte Experiment und die Analyse, die erzeugten Datendateien sowie die Datensätze und Studien, die sie bündeln. Indem wissenschaftliche Details von administrativen Angaben wie Zugangsbedingungen getrennt werden, bildet das Modell ab, wie ein echtes Labor und ein Datenportal funktionieren — und zwar so, dass Computer die Informationen zuverlässig verarbeiten können.
Daten nützlich halten, Personen unidentifizierbar
Da das GHGA sensible Gesundheitsdaten von Menschen verwaltet, musste das Team das Modell so gestalten, dass es wissenschaftlich reichhaltig ist, ohne die Identifizierung einer Person zu erleichtern. Nach europäischem DSGVO‑Recht gelten Informationen, die vernünftigerweise mit einer Person verknüpft werden können, als personenbezogen, selbst wenn Namen entfernt sind. Der Artikel beschreibt eine sorgfältige Datenschutzanalyse, die zeigte, wie die Kombination von Angaben wie Alter, Postleitzahl und seltenen Diagnosen Identitäten offenbaren kann. Als Reaktion darauf vermeidet das öffentliche Portal von GHGA feinmaschige Ortsangaben, fasst Alter in breite Bänder statt genaue Jahre zusammen und aggregiert detaillierte Diagnosecodes zu gröberen Kategorien. Auf diese Weise können Forschende weiterhin einschätzen, ob ein Datensatz für ihre Arbeit relevant ist, während der Aufwand, eine einzelne Person herauszufiltern, unrealistisch wird.
Prüfung der Kompatibilität mit Europas Genomik‑Ökosystem
Damit GHGA wirklich nützlich ist, müssen die Metadaten in ein größeres europäisches Netzwerk von Genomarchiven und Tools passen. Die Autorinnen und Autoren verglichen ihr Modell deshalb Feld für Feld mit vier anderen weitverbreiteten Rahmenwerken: zwei Versionen des European Genome‑phenome Archive (EGA), dem ISA‑tab‑Standard und dem FAIR Genomes‑Modell aus den Niederlanden. Sie führten einen detaillierten „Crosswalk“ durch, der für jedes GHGA‑Feld fragte, ob es ein Äquivalent in den anderen Modellen gibt und umgekehrt. Sie stellten fest, dass die meisten zentralen GHGA‑Eigenschaften klare Entsprechungen anderswo haben, besonders bei der Beschreibung von Studien, Proben, Experimenten, Analysen und Dateiformaten. Das bedeutet, dass GHGA‑Datensätze zusammen mit Daten aus anderen europäischen Systemen verstanden und integriert werden können.
Gemeinsame Grundlagen finden – und was noch fehlt
Aus diesem Vergleich extrahierte das Team 25 „Konsens“-Metadatenfelder, die in mindestens drei der fünf Modelle vorkommen. Diese decken Wesentliches ab wie Geschlecht und Gesundheitszustand der Teilnehmenden, das verwendete Gewebe, den Sequenztyp und das Instrument, die Analysemethode, Dateiformate sowie grundlegende Studienbeschreibungen und Kontaktdaten. Diese gemeinsamen Felder stimmen mit bestehenden Mindestberichtsempfehlungen überein und können als Kerncheckliste für alle dienen, die neue Portale für genomische Daten entwerfen. Gleichzeitig zeigte die Analyse Informationen, die einige Modelle erfassen, die GHGA derzeit jedoch auslässt oder nur in flexibler, freitextlicher Form akzeptiert — etwa genaue Datumsangaben zu Probenentnahme und Sequenzierung, ausgeschlossene Diagnosen und detaillierte Kontaktpersonen. Viele dieser Auslassungen sind bewusste Abwägungen zugunsten von Datenschutz und Anonymität.
Was das für die künftige Gesundheitsforschung bedeutet
Insgesamt zeigt die Studie, dass das Metadatamodell von GHGA detailliert, flexibel und eng an internationale Praxis angelehnt ist, dabei aber innerhalb strenger europäischer Datenschutzregeln bleibt. Es deckt bereits alle Felder ab, die andere Archive als verpflichtend betrachten, und lässt sich auf neue Technologien wie Einzelzell‑ und räumliche Omics erweitern. Indem es eine klare Möglichkeit bietet, zu beschreiben, wer und was eine genomische Studie umfasst, wie die Daten erzeugt wurden und unter welchen Bedingungen sie wiederverwendet werden dürfen, trägt GHGA dazu bei, isolierte Datensilos in eine vernetzte Forschungsressource zu verwandeln. Für Patientinnen und Patienten erhöht das die Wahrscheinlichkeit, dass ihre gespendeten Daten sicher zu Entdeckungen und besseren Behandlungen über Grenzen hinweg beitragen können — und das über Jahre hinweg.
Zitation: Mauer, K., Iyappan, A., Parker, S. et al. Semantic alignment of the German Human Genome-Phenome Archive metadata model in Europe’s genomics field. Sci Data 13, 242 (2026). https://doi.org/10.1038/s41597-026-06575-y
Schlüsselwörter: Austausch genomischer Daten, Metadatenstandards, Datenschutz und DSGVO, GHGA, personalisierten Medizin