Clear Sky Science · de
SEA CDM: Study-Experiment-Assay Common Data Model und Datenbanken zur domänenübergreifenden Datenintegration und -analyse
Warum die Organisation von Labordaten uns alle betrifft
Die moderne Medizin stützt sich auf Berge experimenteller Daten — von Impfstoffstudien und Infektionsforschung bis hin zur Krebsgenomik. Diese Daten sind jedoch häufig in inkompatiblen Formaten eingeschlossen, sodass es Wissenschaftlern schwerfällt, Ergebnisse zu kombinieren und wichtige Muster zu erkennen, etwa wer am besten auf einen Impfstoff anspricht oder warum manche Menschen stärkere Nebenwirkungen haben. Dieser Artikel beschreibt eine neue Methode, um unterschiedliche biomedizinische Experimente zu organisieren und zu verknüpfen, damit Forschende reichhaltigere Fragen stellen und schneller zuverlässigere Antworten erhalten können, die letztlich beeinflussen, wie wir Krankheiten verhindern und behandeln.
Eine gemeinsame Sprache für Experimente
Verschiedene Forschungsgruppen und Datenbanken beschreiben ihre Studien oft auf eigene Weise, selbst wenn sie sehr ähnliche Arbeiten durchführen. Eine Datenbank konzentriert sich möglicherweise auf Impfstoffstudien, eine andere auf Genaktivität in Einzelzellen und eine dritte auf klinische Ergebnisse — jeweils mit unterschiedlichen Bezeichnungen und Strukturen. Das Study–Experiment–Assay Common Data Model, kurz SEA CDM, bietet eine einfache gemeinsame "Grammatik" für all diese Bemühungen. Es zerlegt jedes biomedizinische Projekt in drei verknüpfte Schritte: die übergeordnete Studie, die eine Frage stellt; die Experimente, die an Menschen oder Tieren durchgeführt werden; und die Assays — etwa Bluttests oder Messungen der Genexpression —, die Ergebnisse erzeugen. Um diese Schritte herum standardisiert das Modell außerdem Schlüsselelemente wie wer oder was untersucht wurde, welche Proben entnommen wurden, welche Behandlungen angewandt wurden und welche Analysen durchgeführt wurden. 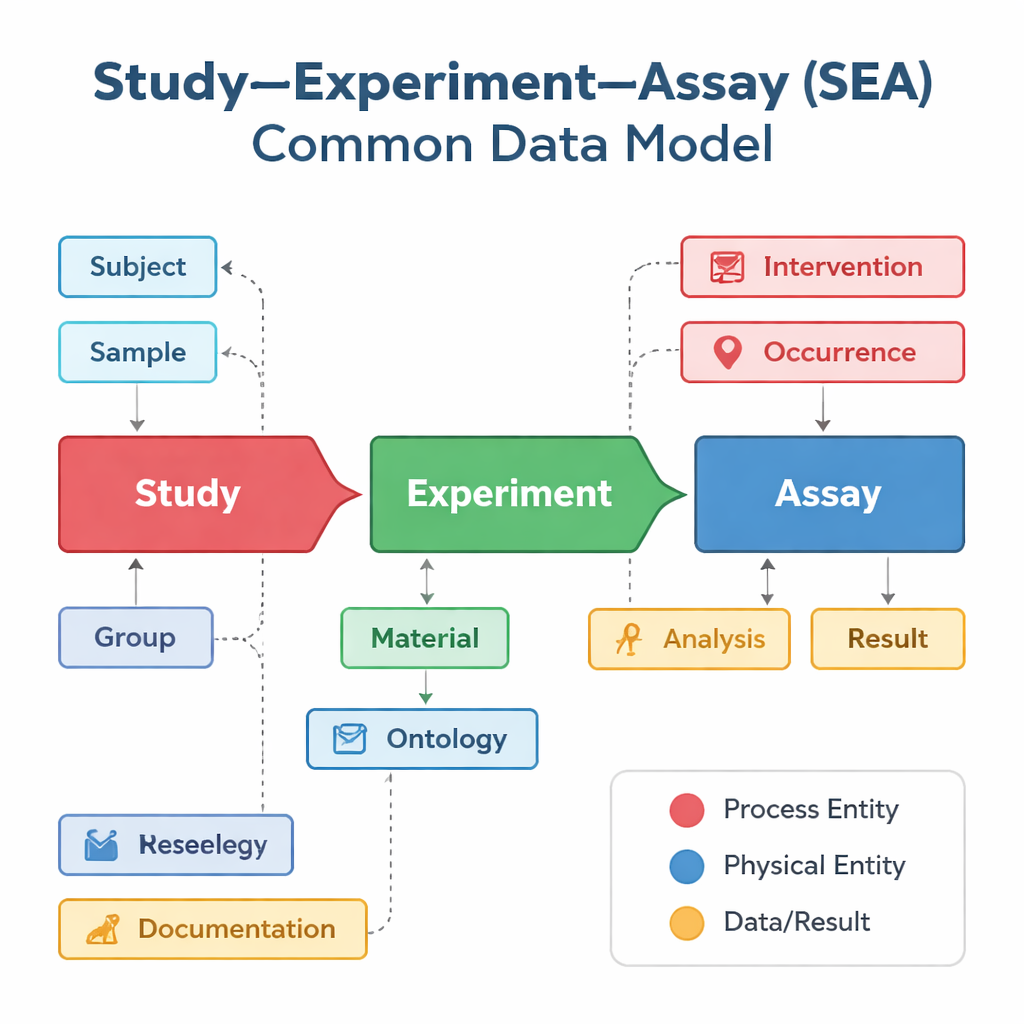
Ontologien: Etiketten in Wissen verwandeln
Es reicht nicht, nur Spaltenüberschriften anzugleichen; dasselbe Konzept kann an verschiedenen Stellen unterschiedlich benannt werden. SEA CDM stützt sich auf kuratierte Vokabulare, sogenannte Ontologien, um sicherzustellen, dass „Grippeimpfung“, „trivalenter inaktivierter Influenza-Impfstoff“ und ein Markenname wie „Fluzone“ als verwandte Begriffe erkannt werden. Diese Ontologien sind strukturiert wie Familienstammbäume medizinischer und biologischer Begriffe. Weil SEA CDM jedem Variablenwert — etwa einer Krankheit, einem Zelltyp oder einem Impfstoff — eine offizielle Kennung aus einer Ontologie zuordnet, können Computer diese Bäume automatisch durchlaufen, alle relevanten Einträge finden und sogar Beziehungen ableiten. Eine kurze Abfrage kann beispielsweise jede Studie herausziehen, die irgendeinen trivalenten Influenza-Impfstoff verwendet hat, aus Hunderten von Produktnamen — was leistungsfähige, semantische Suchvorgänge ermöglicht, die weit über einfache Stichwortsuche hinausgehen. 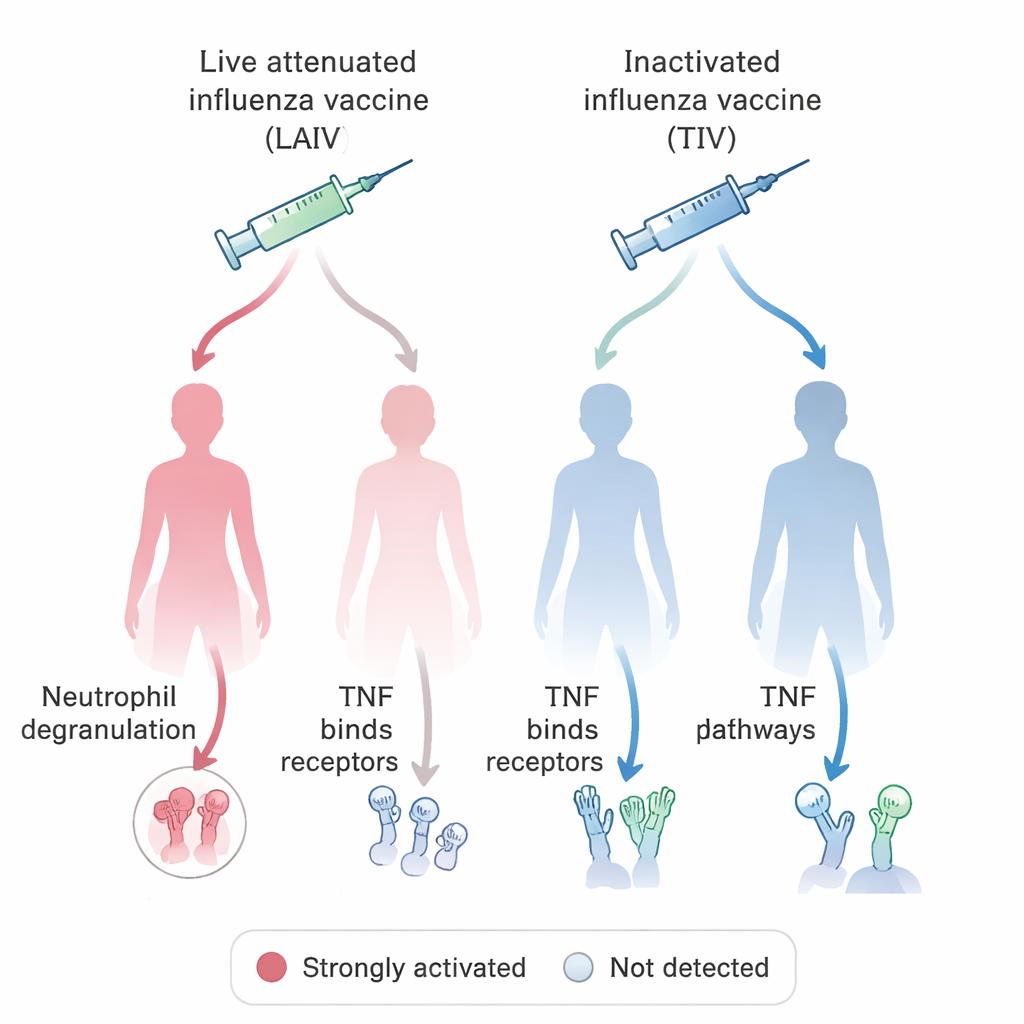
Von verstreuten Dateien zu vernetzten Datenbanken
Um ihr Modell in der Praxis zu testen, bauten die Autoren eine Familie von Datenbanken und Werkzeugen unter dem Dachnamen OSEAN. Sie konvertierten drei große öffentliche Ressourcen in die SEA CDM-Struktur: ImmPort, das Metadaten zu immunologischen Studien hostet; VIGET, das Impfstoffstudien mit Genaktivitätsdaten verknüpft; und CELLxGENE, das sich auf Einzelzellmessungen konzentriert. Mit maßgeschneiderten Pipelines übersetzten sie Dutzende originaler Tabellen und Dateiformate in einen konsistenten Satz von SEA CDM-Tabellen oder Graphknoten. Dadurch konnten sie mehr als tausend immunbezogene Studien, über zwei Millionen Proben sowie zahlreiche Beschreibungen von Impfstoffen, Krankheiten und Labormethoden in einem kohärenten Rahmen speichern, der mit derselben Software durchsuchbar ist.
Was vereinheitlichte Daten über Impfstoffe und Geschlechtsunterschiede offenbaren können
Mit diesem einheitlichen System stellte das Team eine biologisch und medizinisch relevante Frage: Wie stimulieren verschiedene Influenza-Impfstoffe das Immunsystem bei Frauen und Männern? Durch Abfragen der auf VIGET basierenden OSEAN-Datenbank und Anwendung einfacher Regeln dafür, was als „stimuliertes“ Gen zählt, identifizierten sie Hunderte von Genen, deren Aktivität nach einer Impfung mit entweder lebend- abgeschwächten Influenzaimpfstoffen (mit abgeschwächten Viren) oder inaktivierten, „abgetöteten“ Impfstoffen anstieg. Sie verglichen dann die Signalwege, an denen diese Gene beteiligt sind, und trennten die Daten nach Geschlecht. Ein auffälliges Muster betraf Neutrophile, eine Art von weißen Blutkörperchen, die Mikroben durch Freisetzung toxischer Granula angreifen, sowie die Signalübertragung über TNF, ein zentrales Entzündungsmolekül. In den meisten Gruppen war die Influenzaimpfung mit Hinweisen auf Neutrophilendegranulation verbunden, doch dieses Merkmal fehlte bei Frauen, die den lebend abgeschwächten Impfstoff erhielten. Im Gegensatz dazu war die TNF-verbundene Signalgebung bei diesen Frauen besonders ausgeprägt, aber nicht in den entsprechenden männlichen Gruppen. Diese Ergebnisse stehen im Einklang mit Tierstudien, die nahelegen, dass sich Neutrophilenverhalten und Impfantworten systematisch zwischen Männern und Frauen unterscheiden können.
Ein Ökosystem für künftige Entdeckungen aufbauen
Die Autoren argumentieren, dass die eigentliche Stärke des SEA CDM darin besteht, biomedizinische Daten FAIRer zu machen — findbar, zugänglich, interoperabel und wiederverwendbar. Indem Experimente eine gemeinsame Struktur erhalten und jedes wichtige Etikett an einen klar definierten Ontologiebegriff gebunden wird, erleichtert ihr System die Kombination von Daten aus verschiedenen Quellen, das Nachvollziehen der Probenverarbeitung und das Reproduzieren von Analysen erheblich. Die Influenza-Fallstudie zeigt, dass selbst relativ einfache Abfragen über eine harmonisierte Datenbank subtile, geschlechtsspezifische Muster in der Impfantwort aufdecken können, die Dosierung oder Impfstoffwahl beeinflussen könnten. Wenn mehr Ressourcen dieses gemeinsame Modell und die begleitenden Werkzeuge übernehmen, werden Forschende besser gerüstet sein, Hinweise über Krankheiten, Technologien und Populationen hinweg zu verknüpfen und fragmentierte Datensätze in ein echtes integratives Biodaten-Ökosystem zu verwandeln.
Zitation: Huffman, A., Yeh, FY., Hur, J. et al. SEA CDM: Study-Experiment-Assay Common Data Model and Databases for Cross-Domain Data Integration and Analysis. Sci Data 13, 238 (2026). https://doi.org/10.1038/s41597-026-06558-z
Schlüsselwörter: Datenintegration, biomedizinische Ontologie, Impfantwort, Geschlechtsunterschiede, Wissensgraph