Wie das Gehirn verborgene Regeln in einer verrauschten Welt findet
Jeden Tag erkennen wir mühelos Muster: Ein rotes Licht bedeutet Stopp, eine belebte Straße heißt langsamer fahren, eine bestimmte Körperhaltung kündigt an, dass ein Haustier gleich springen wird. Hinter diesen Fähigkeiten steht die Fähigkeit des Gehirns, versteckte oder „latente“ Strukturen in der Welt zu entdecken und sie in vielen verschiedenen Aufgaben wiederzuverwenden. Dieses Papier stellt eine auf den ersten Blick einfache Frage: Was macht ein bestimmtes Muster von Populationenaktivität im Gehirn besser als ein anderes für das schnelle und genaue Lösen vieler verwandter Aufgaben?
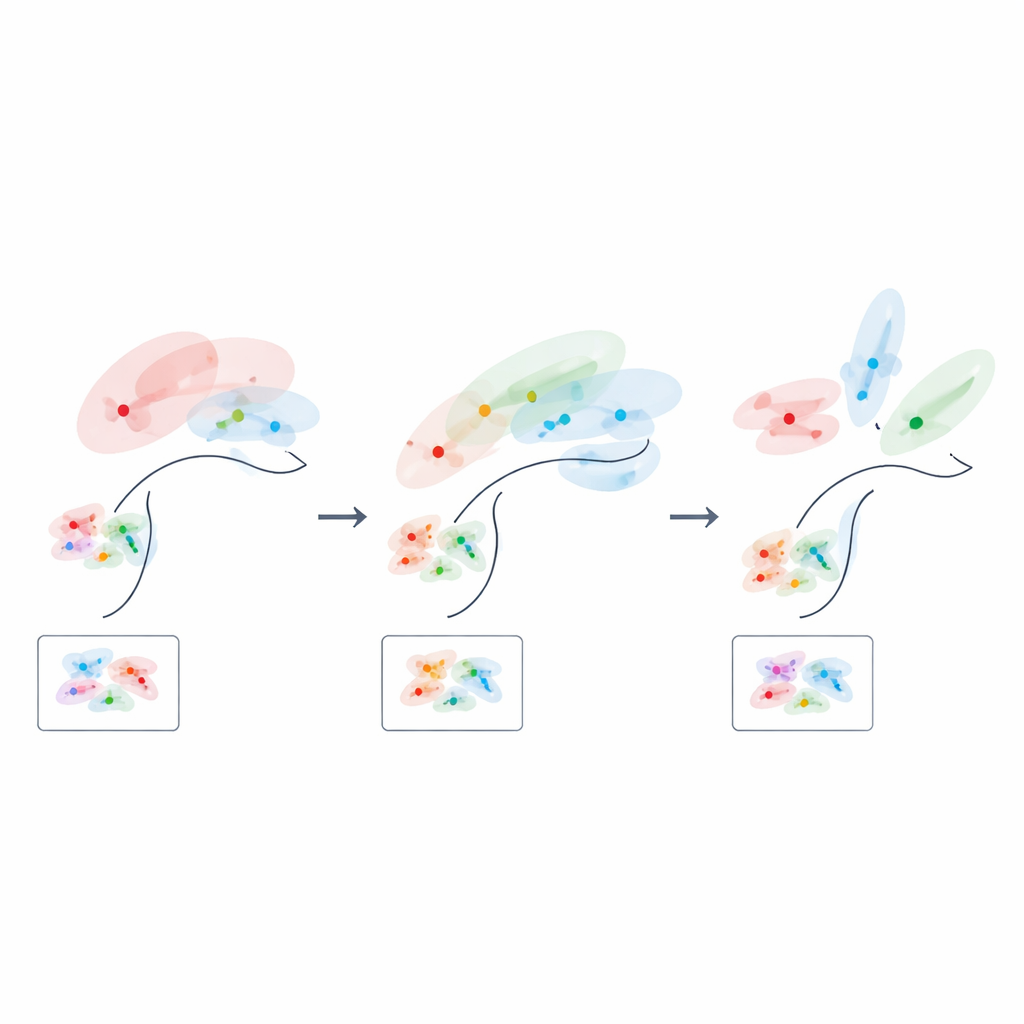
Die verborgenen Stellschrauben neuronaler Codes Figure 1.
Die Autorinnen und Autoren untersuchen Gehirnaktivität auf Populationsebene und betrachten das Feuern vieler Neuronen als Punkte in einem hochdimensionalen Raum. Sie konzentrieren sich auf Aufgaben, die eine gemeinsame zugrundeliegende Menge latenter Variablen teilen – zum Beispiel Form, Größe und Position eines Objekts oder den Ort und die Geschwindigkeit eines Tiers. Ein nachgeschaltetes Neuron oder Schaltkreis liest diese Muster mit einer einfachen linearen Regel aus, vergleichbar mit dem Durchziehen einer Ebene durch die Punktwolke, um „Kategorie A“ von „Kategorie B“ zu trennen. Anstatt jedes Neuron im Detail zu simulieren, leiten die Autorinnen und Autoren eine analytische Formel her, die vorhersagt, wie gut ein solcher Ausleser auf neue Beispiele generalisieren wird, gegeben die Geometrie der neuronalen Aktivität. Bemerkenswerterweise finden sie, dass die Leistung von nur vier Kennzahlen bestimmt wird, die erfassen, wie stark Neuronen die latenten Variablen widerspiegeln, wie sauber verschiedene Variablen getrennt sind, wie das Rauschen angeordnet ist und wie viele effektive Dimensionen die Aktivität einnimmt.
Vier einfache Zutaten für gute Generalisierung
Die erste Zutat ist die allgemeine Korrelation zwischen einzelnen Neuronen und den latenten Variablen: Wenn kleine Änderungen der verborgenen Variablen klare Verschiebungen in neuronalen Antworten verursachen, haben nachgeschaltete Ausleser mehr Informationssignal zur Verfügung. Die zweite und dritte Zutat beschreiben die „Faktorisierung“: Idealerweise werden verschiedene latente Variablen entlang unabhängiger Richtungen kodiert, und zufälliges Rauschen driftet in Richtungen, die orthogonal zu diesen Signalachsen liegen. Das erleichtert einer einzigen linearen Grenze das Übertragen über viele Aufgaben, die alle von derselben verborgenen Struktur abhängen. Die vierte Zutat ist die effektive Dimensionalität, die erfasst, wie viele Richtungen im Aktivitätsraum die Population tatsächlich nutzt. Höhere Dimensionalität neigt dazu, Rauschen auf mehr Richtungen zu verteilen und die Zuverlässigkeit zu verbessern, muss aber gegen die Klarheit abgewogen werden, mit der das Signal auf verhaltensrelevante Variablen ausgerichtet ist.
Test der Theorie in künstlichen und biologischen Gehirnen Figure 2.
Um ihre Theorie zu prüfen, wenden die Autorinnen und Autoren sie zunächst auf künstliche neuronale Netze an. In mehrschichtigen Perzeptrons, die auf vielen verwandten Klassifizierungsaufgaben trainiert wurden, und in einem tiefen Netzwerk, das Körperteile von Mäusen in Videoaufnahmen verfolgt, messen sie die vier geometrischen Größen in jeder Schicht. Die vorhergesagten Fehler stimmen eng mit der tatsächlichen Leistung einfacher Ausleser überein, die auf diesen internen Repräsentationen trainiert wurden. Anschließend wenden sie sich realen Gehirndaten zu. Aufnahmen aus visuellen Arealen von Makaken zeigen, dass sich die Geometrie auf dem Weg von den Augen durch höhere visuelle Kortexbereiche so entwickelt, dass der Generalisierungsfehler sinkt: Korrelationen mit latenten Variablen nehmen zu, störende Variabilität wird von Signalrichtungen weggeschoben und bestimmte Formen der Dimensionalität werden umgestaltet. Bei Ratten, die eine räumliche Alternationsaufgabe lernen, verbessern sich Verhalten und Ausleseleistung über Trainingstage hinweg, während sich die Geometrie von Hippocampus- und präfrontaler Aktivität systematisch in einer Weise verändert, die den Vorhersagen der Theorie entspricht.
Wie Lernen den neuronalen Raum umschreibt
Da ihre Formel Geometrie direkt mit Leistung verknüpft, können die Autorinnen und Autoren fragen, wie ein „optimaler“ neuronaler Code in verschiedenen Lernphasen aussehen sollte. Früher, wenn nur wenige Trainingsbeispiele verfügbar sind, sind die besten Codes niedrigdimensional und stark an die informationsreichsten latenten Variablen angelehnt, wodurch weniger nützliche Merkmale effektiv komprimiert werden. Mit zunehmender Erfahrung verschiebt sich die optimale Lösung: Die Repräsentation aufgabenrelevanter Struktur dehnt sich in mehr Dimensionen aus, und die enge Korrelation zwischen einzelnen Neuronen und einzelnen Variablen entspannt sich tatsächlich. Mit anderen Worten scheint das Gehirn mit einer fokussierten, niedrigdimensionalen Skizze der Aufgabe zu beginnen und füllt beim Lernen allmählich eine reichere, stärker verteilte Landkarte aus.
Warum das für das Verständnis von Gehirnen und Maschinen wichtig ist
Für eine allgemeine Leserschaft lautet die Kernbotschaft: Populationenaktivität im Gehirn ist nicht einfach ein Gewirr von Spikes; sie hat eine Form, und diese Form ist bedeutsam. Indem vier messbare geometrische Merkmale identifiziert werden, die steuern, wie gut einfache Ausleser über verwandte Aufgaben generalisieren können, liefert diese Arbeit eine gemeinsame Sprache zum Vergleich biologischer und künstlicher neuronaler Netze. Sie legt nahe, dass sich bei Tieren und Maschinen während des Lernens die interne Aktivität von kompakten, hochgradig ausgerichteten Codes hin zu höherdimensionalen, besser faktorisierten Codes umorganisiert, die weiterhin aufgabenrelevante Informationen vor Rauschen schützen. Diese geometrische Sicht erklärt, wie dieselben neuronalen Schaltkreise verborgene Strukturen flexibel in vielen Situationen wiederverwenden können und so die scheinbar mühelose Generalisierung ermöglichen, die unserer alltäglichen Intelligenz zugrunde liegt.
Zitation: Wakhloo, A.J., Slatton, W. & Chung, S. Neural population geometry and optimal coding of tasks with shared latent structure.
Nat Neurosci29, 682–692 (2026). https://doi.org/10.1038/s41593-025-02183-y