Clear Sky Science · de
Zuverlässigkeit von LLMs als medizinische Assistenten für die Allgemeinheit: eine randomisierte, präregistrierte Studie
Warum Ihr Telefon nicht der beste erste Arzt sein könnte
Immer mehr Menschen wenden sich an KI‑Chatbots, wenn sie sich unwohl fühlen, in der Hoffnung auf schnelle Antworten: ob sie sich Sorgen machen sollten, was ihre Symptome bedeuten könnten und ob sie ins Krankenhaus gehen sollten. Diese Studie stellt eine einfache, aber dringliche Frage: Wenn normale Menschen leistungsfähige Sprachmodelle zu Hause als medizinische Helfer nutzen, treffen sie dann tatsächlich bessere Gesundheitsentscheidungen — oder vermittelt die Technologie nur ein falsches Sicherheitsgefühl?
Prüfung intelligenter Maschinen an realistischen Fällen
Um das herauszufinden, entwickelten Forscher im Vereinigten Königreich zehn realistische medizinische Fallgeschichten, etwa eine plötzlich eintretende starke Kopfschmerzattacke oder Atembeschwerden, basierend auf häufigen Beschwerden, denen viele von uns begegnen könnten. Ein Team erfahrener Ärztinnen und Ärzte einigte sich für jede Geschichte auf den besten „nächsten Schritt“ — von zu Hause bleiben und Selbstversorgung bis zum Notruf — und listete die wichtigen Erkrankungen auf, die eine sorgfältige Person in Betracht ziehen sollte. Anschließend wurden 1.298 Erwachsene aus dem ganzen Vereinigten Königreich per Zufall einer von vier Optionen zugewiesen: die Nutzung eines von drei führenden KI‑Chatbots oder die Nutzung dessen, worauf sie zu Hause normalerweise zurückgreifen würden, etwa Websuche oder persönliche Erfahrung.
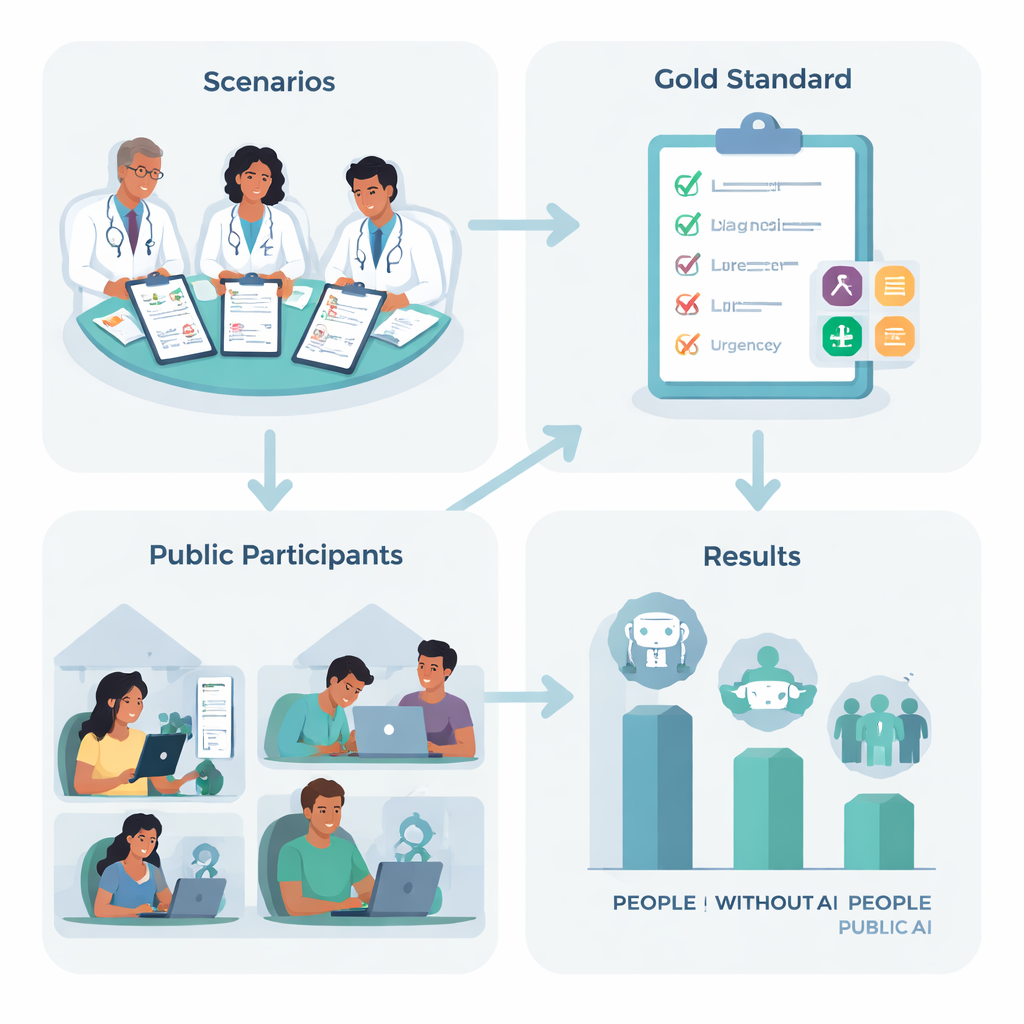
Wie Menschen und Maschinen abschnitten — getrennt und zusammen
Wurden die Sprachmodelle isoliert getestet, indem man ihnen die vollständigen Falldarstellungen vorlegte und direkt nach einer Diagnose und einer empfohlenen Handlung fragte, schnitten sie beeindruckend gut ab. Über die drei Systeme hinweg nannten sie in etwa 95 % der Fälle mindestens eine relevante medizinische Ursache korrekt und wählten das richtige Dringlichkeitsniveau in mehr als der Hälfte der Fälle — deutlich besser als ein zufälliges Raten. Auf dem Papier wirkten diese Systeme wie starke Kandidaten, um besorgte Patientinnen und Patienten zu leiten.
Wenn KI‑Ratschläge auf echte Menschen treffen
Aber sobald Alltagsnutzer ins Spiel kamen, änderte sich das Bild. Teilnehmerinnen und Teilnehmer, die KI nutzten, waren nicht genauer als die Kontrollgruppe bei der Entscheidung, was als Nächstes zu tun ist, und sie waren tatsächlich schlechter darin, relevante zugrundeliegende Erkrankungen zu benennen. Menschen in der Nicht‑KI‑Gruppe identifizierten etwa 1,8‑mal häufiger eine korrekte Erkrankung als diejenigen, die Chatbots verwendeten. Die meisten Teilnehmenden in allen Gruppen unterschätzten, wie ernst die Situation war. Mit anderen Worten: Der Zugang zu einem fortgeschrittenen Sprachmodell half den Menschen nicht, ihre Symptome besser zu verstehen, und lenkte sie nicht eindeutig zu sichereren Entscheidungen.
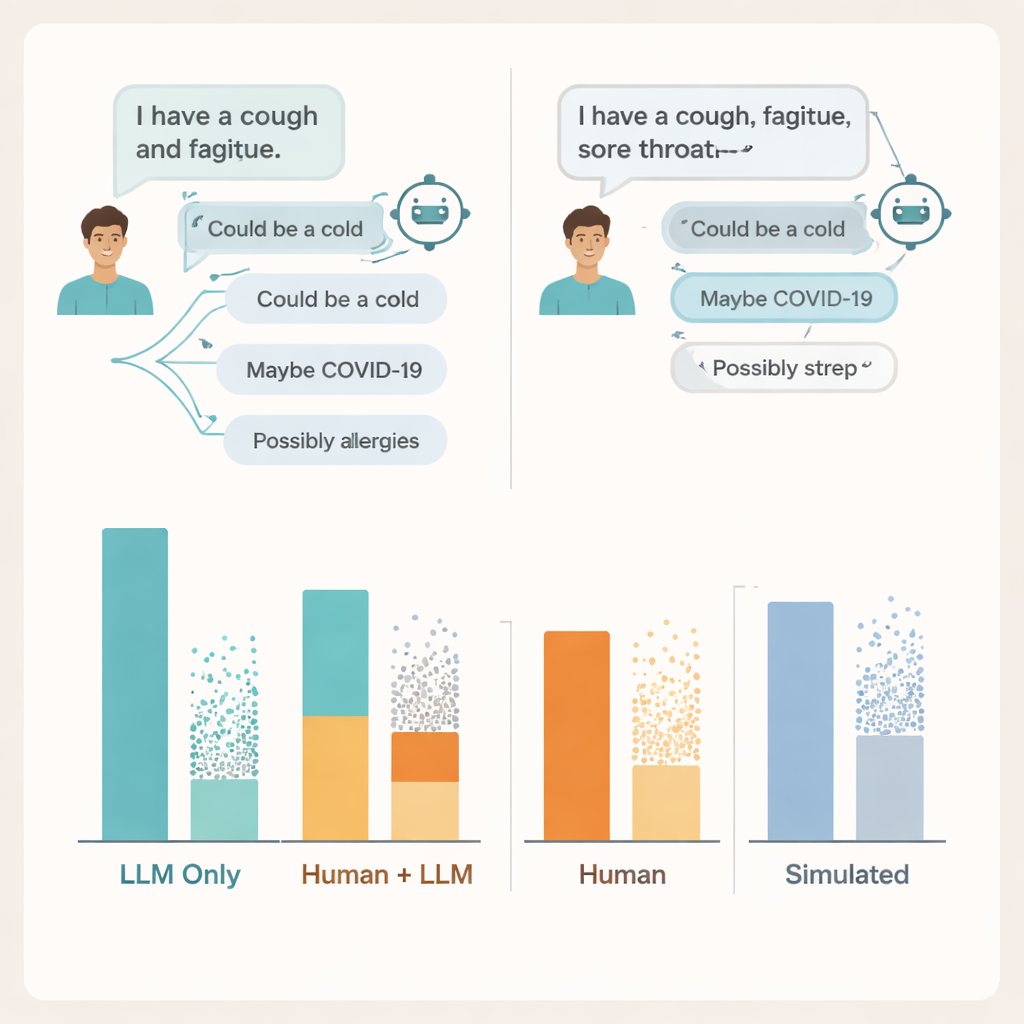
Wo die Unterhaltung scheitert
Um die Gründe zu klären, untersuchten die Forscher die tatsächlichen Chat‑Transkripte. Sie fanden Probleme auf beiden Seiten der Konversation. Viele Nutzerinnen und Nutzer teilten nicht genug Details über ihre Symptome mit, damit die KI fundierte Ratschläge geben konnte — ähnlich wie Patientinnen und Patienten manchmal wichtige Informationen auslassen, wenn sie mit einem Arzt sprechen. Die Modelle nannten oft mindestens eine relevante Erkrankung, fügten aber auch mehrere falsche oder ablenkende Möglichkeiten hinzu, und die Nutzer hatten Schwierigkeiten zu erkennen, welche Vorschläge wichtig waren. In einigen Fällen führten nahezu identische Symptom‑Beschreibungen zu deutlich unterschiedlichen Ratschlägen desselben Modells, was es den Menschen erschwerte, ein klares Gefühl dafür zu entwickeln, wann sie dem auf dem Bildschirm Gezeigten vertrauen sollten.
Warum Standardtests die realen Risiken übersehen
Das Team verglich diese Ergebnisse außerdem mit zwei gängigen Bewertungsmethoden für medizinische KIs: Multiple‑Choice‑Prüfungsfragen und vollständig simulierte „Patienten“-Chats zwischen zwei Modellen. In beiden Fällen wirkten die Systeme erneut stark, sie erreichten oder übertrafen übliche Bestehensgrenzen bei Prüfungsfragen und schnitten bei simulierten Patienten besser ab als bei echten. Trotzdem stimmten hohe Prüfungsergebnisse und polierte simulierte Gespräche nicht mit der Leistung überein, die reale Menschen beim Einsatz derselben Werkzeuge zeigten. Bewertungsmaßstäbe, die Wissen isoliert prüfen, argumentieren die Autorinnen und Autoren, verfehlen die unordentliche, fragile Natur realer Mensch‑KI‑Interaktionen.
Was das für Patientinnen, Patienten und Gesundheitssysteme bedeutet
Die Studie kommt vorerst zu dem Schluss: Allgemeine Sprachmodelle sind nicht bereit, als unbeaufsichtigte Erstberater für die Öffentlichkeit zu fungieren. Sie enthalten zwar eine große Menge an medizinischem Wissen, doch dieses Wissen führt nicht automatisch zu sichereren Entscheidungen, wenn verunsicherte Menschen zu Hause unvollständige oder verwirrte Fragen eingeben. Damit KI in risikoreichen Bereichen wie der Gesundheitsversorgung wirklich hilfreich wird, bedarf es mehr als besserer Prüfungsergebnisse — es braucht sorgfältiges Design, Tests mit diversen realen Nutzenden und strengere Kontrollen darüber, wie Informationen gesammelt, erklärt und im Austausch vertrauenswürdig gemacht werden.»}
Zitation: Bean, A.M., Payne, R.E., Parsons, G. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat Med 32, 609–615 (2026). https://doi.org/10.1038/s41591-025-04074-y
Schlüsselwörter: medizinische Chatbots, Selbstdiagnose, KI im Gesundheitswesen, Patientenentscheidung, große Sprachmodelle