Clear Sky Science · de
Wissenschaftliche Literatur synthetisieren mit abruf-gestützten Sprachmodellen
Warum es so schwer ist, in der Wissenschaft auf dem Laufenden zu bleiben
Jedes Jahr erscheinen Millionen neuer wissenschaftlicher Artikel online. Kein einzelner Forschender kann sie alle lesen, doch wichtige medizinische Behandlungen, klimarelevante Erkenntnisse und technologische Durchbrüche können in dieser Flut von Informationen verborgen sein. Dieser Artikel untersucht, ob fortgeschrittene KI-Systeme Forschenden helfen können, dieses Meer von Studien zu durchsuchen und daraus klare, vertrauenswürdige Zusammenfassungen zu erstellen — ohne Dinge zu erfinden.
Eine neue Art von Forschungsassistent
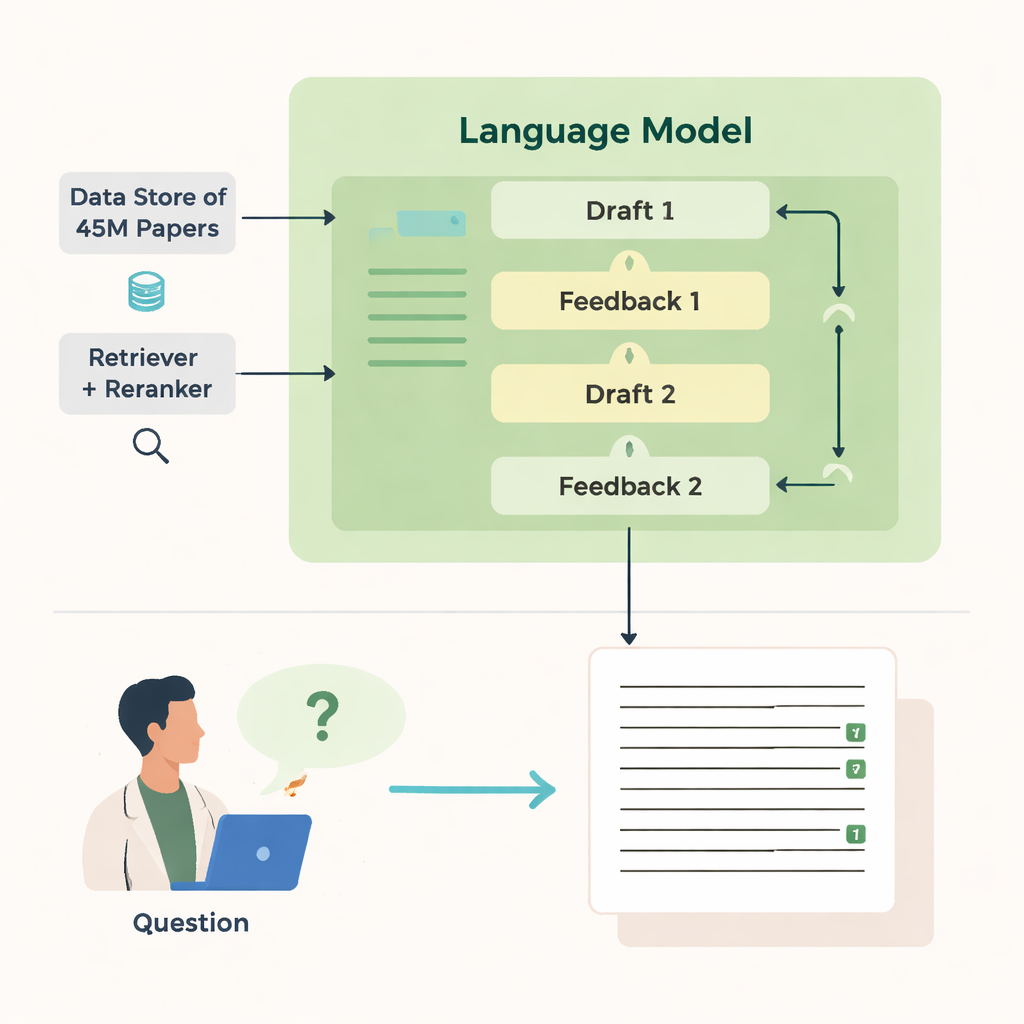
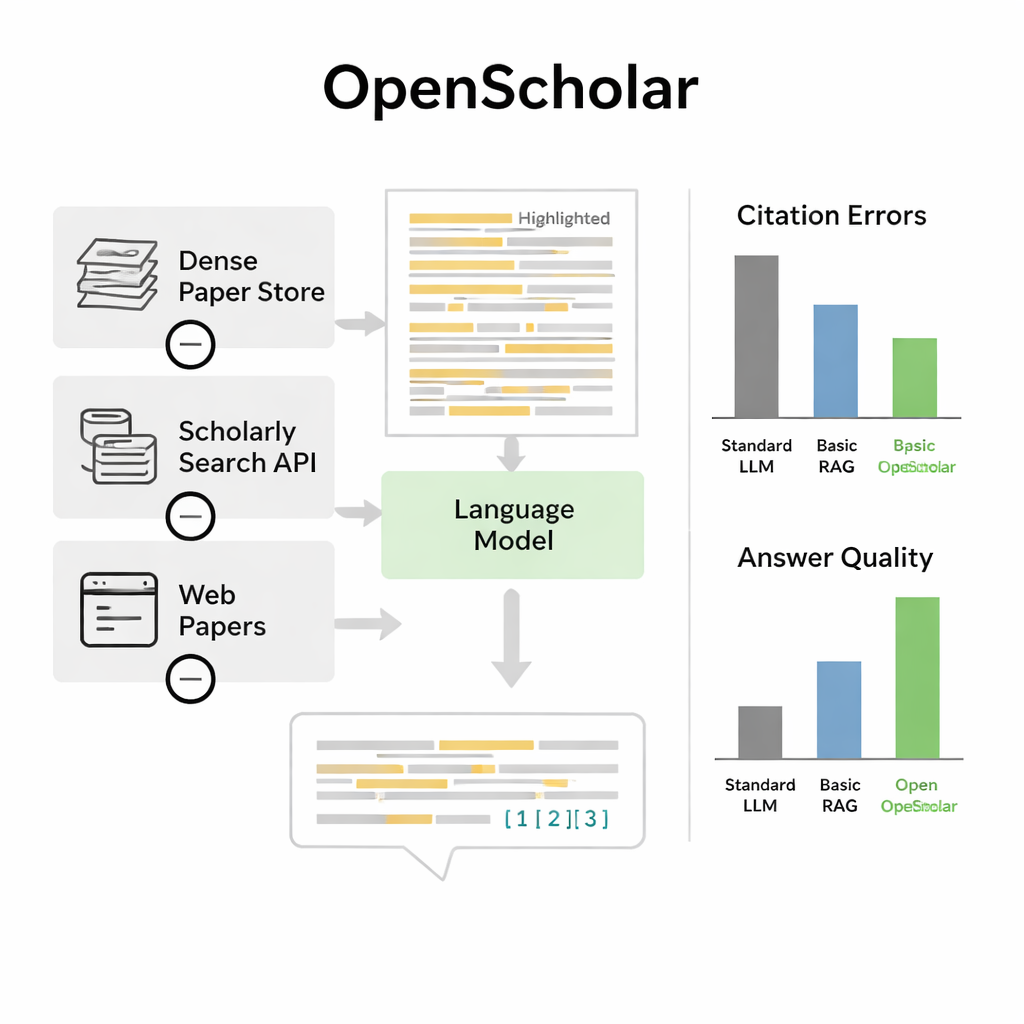
Die Autorinnen und Autoren stellen OpenScholar vor, ein KI-System, das speziell dafür entwickelt wurde, wissenschaftliche Literatur zu lesen und zu synthetisieren. Anders als allgemeine Chatbots ist OpenScholar eng angebunden an eine riesige offene Datenbank von etwa 45 Millionen Forschungsarbeiten, den OpenScholar DataStore. Wenn ein Wissenschaftler eine Frage stellt — etwa wie man levitierte Nanopartikel kühlt oder welche Methoden sich am besten für die Gehirnbildgebung eignen — durchsucht das System zunächst die Datenbank nach relevanten Abschnitten und entwirft dann eine Antwort mit Inline-Zitaten, ähnlich einem von Menschen verfassten Übersichtsartikel. Diesen Prozess wiederholt es mehrfach, kritisiert und verfeinert eigene Entwürfe, um Klarheit, Vollständigkeit und Zitierqualität zu verbessern.
Wie es sucht und schreibt
Die Stärke von OpenScholar beruht auf mehreren koordinierten Komponenten. Ein „Retriever“-Modul durchsucht vorab berechnete Textembeddings aus Millionen von Artikeln, um vielversprechende Textausschnitte zu finden, während ein „Reranker“ diese Ausschnitte neu ordnet, um die relevantesten in den Vordergrund zu rücken. Das Sprachmodell nutzt dann diese Belege, um eine ausführliche Antwort mit nummerierten Referenzen zu erzeugen. Nach dem ersten Entwurf erzeugt das Modell eigenes Feedback — es weist auf fehlende Perspektiven, schwache Struktur oder dünne Belege hin — und löst bei Bedarf gezieltere Suchen aus. Anschließend schreibt es die Antwort um, fügt neue Arbeiten ein und passt die Zitate an. Eine abschließende Prüfung stellt sicher, dass Aussagen, die Unterstützung benötigen, durch mindestens eine gefundene Quelle belegt sind.
Behauptungen und Zitate auf die Probe stellen
Um zu prüfen, ob OpenScholar tatsächlich nützt, entwickelten die Autorinnen und Autoren ScholarQABench, ein großes Benchmark, das reale Fragen aus Literaturübersichten nachbildet. Es enthält fast 3.000 von Expertinnen und Experten verfasste Fragen und Hunderte langer Antworten aus Informatik, Physik, Neurowissenschaften und Biomedizin. Wichtig ist, dass diese Fragen meist das Lesen mehrerer Arbeiten erfordern, nicht nur eines Abstracts. Das Team bewertete Systeme entlang mehrerer Dimensionen: faktische Korrektheit, wie gut Antworten Schlüsselpunkte abdeckten, Schreibklarheit und wie genau Zitate die zugrunde liegenden Arbeiten widerspiegeln. Automatische Prüfungen wurden mit detaillierten Bewertungen von Promovierenden auf Doktorandenniveau kombiniert, die KI-generierte Antworten mit menschlichen verglichen.
Stärkere Chatbots übertreffen und Expertinnen ebenbürtig
In diesem Benchmark übertraf OpenScholar sowohl Standard-Sprachmodelle als auch frühere Werkzeuge, die einfach Retrieval an einen allgemeinen Chatbot anhängten. Eine kompakte Acht-Milliarden-Parameter-Version, die vollständig mit offenen Daten trainiert wurde, schnitt bei einer anspruchsvollen Syntheseaufgabe über mehrere Arbeiten besser ab als GPT-4o und ein konkurrierendes System namens PaperQA2, obwohl diese auf größeren proprietären Modellen beruhten. Auffällig war, wie häufig gewöhnliche Chatbots Referenzen halluzinierten: in 78–90 Prozent der Fälle enthielten ihre Zitatlisten Arbeiten, die nicht existierten oder die Behauptungen nicht stützten. Demgegenüber erreichte OpenScholar eine Zitationsgenauigkeit, die mit der von menschlichen Expertinnen und Experten konkurrierte. Bei direkten Vergleichen zogen Expertinnen und Experten OpenScholar-8B etwa zur Hälfte der Zeit expertengeschriebene Antworten vor, und eine OpenScholar-Pipeline auf Basis von GPT-4o etwa 70 Prozent der Zeit — hauptsächlich, weil die KI mehr relevante Studien abdeckte und sie klar organisierte.
Grenzen und mögliche Verbesserungen
Trotz dieser Fortschritte betonen die Autorinnen und Autoren, dass OpenScholar keinen Ersatz für Forschende darstellt. Das System kann weiterhin die repräsentativsten Arbeiten übersehen, weniger wichtige Arbeiten überbetonen oder faktische Fehler einführen, insbesondere in kompakteren Modellen. Auch das Benchmark selbst hat Grenzen: Es konzentriert sich hauptsächlich auf Informatik, Biomedizin und Physik, und die sorgfältig annotierten Fragen sind noch relativ wenige, weil Expertenzeit teuer ist. Bewertungen tun sich außerdem schwer, subtilere Qualitäten vollständig zu erfassen, etwa ob Zitate wirklich grundlegende Arbeiten hervorheben oder ob eine Antwort tatsächlich dazu geeignet wäre, ein neues Experiment anzuleiten.
Was das für die Alltagspraxis der Wissenschaft bedeutet
Für Nicht-Spezialistinnen und Nicht-Spezialisten ist die Hauptbotschaft, dass sorgfältig gestaltete KI‑Werkzeuge Forschende bereits jetzt dabei unterstützen können, wissenschaftliche Literatur effektiver zu navigieren — vorausgesetzt, sie sind an reale Daten gebunden und unterliegen strengen Standards für Belege und Transparenz. OpenScholar zeigt, dass ein KI-System, das von Grund auf so gebaut ist, dass es reale Arbeiten abruft, prüft und zitiert — und dessen Leistung gegen menschliche Expertinnen und Experten getestet wird — Literaturzusammenfassungen erzeugen kann, die nicht nur lesbar, sondern auch verifizierbar sind. In der Praxis könnten solche Werkzeuge Forschende entlasten, damit sie sich stärker auf die Planung von Experimenten und die Interpretation von Ergebnissen konzentrieren, wobei die Menschen weiterhin die Entscheidungshoheit darüber behalten, was wahr und wichtig ist.
Zitation: Asai, A., He, J., Shao, R. et al. Synthesizing scientific literature with retrieval-augmented language models. Nature 650, 857–863 (2026). https://doi.org/10.1038/s41586-025-10072-4
Schlüsselwörter: wissenschaftliche Literaturübersicht, abruf-gestützte Sprachmodelle, OpenScholar, Genauigkeit von Zitaten, KI-Forschungstools