Clear Sky Science · de
Von Sprachmodellen gelenkte Antizipation und Entdeckung mammalischer Metaboliten
Verborgene Chemie in unseren Körpern
Jeder Tropfen Blut oder Urin enthält Tausende winziger Moleküle, die widerspiegeln, was wir essen, wie wir leben und ob wir krank werden. Für die meisten dieser Moleküle kennen Wissenschaftler jedoch weder Namen noch Funktion. Diese Arbeit stellt DeepMet vor, ein System der künstlichen Intelligenz, das die „Sprache“ dieser Moleküle liest und vorhersagt, welche in unseren aktuellen Karten der menschlichen und tierischen Chemie fehlen. Indem es Experimente auf die vielversprechendsten Kandidaten lenkt, hilft DeepMet Forschern, dieses chemische Dunkelmaterial aufzudecken und besser zu verstehen, wie unsere Körper funktionieren.
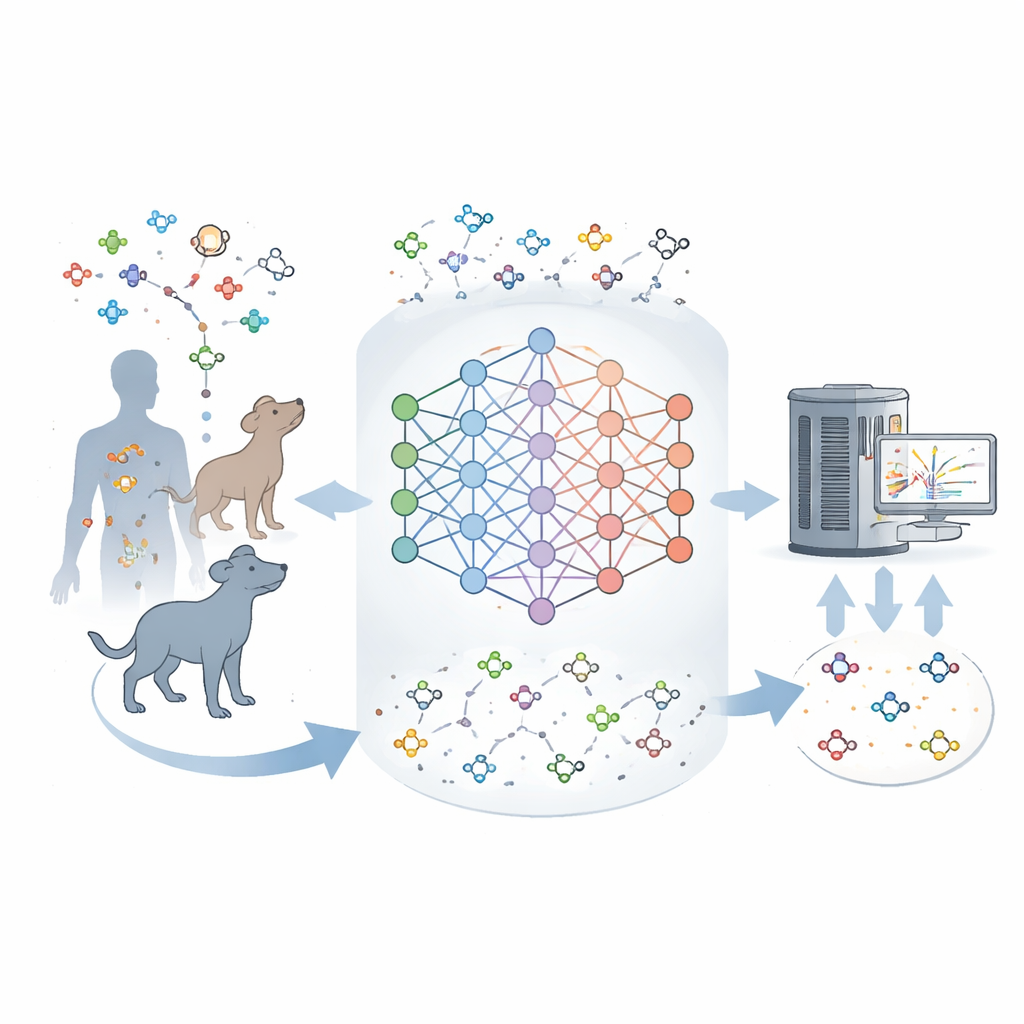
Warum so viele Moleküle unbekannt bleiben
Moderne Instrumente können Tausende Moleküle in einer Gewebeprobe gleichzeitig wiegen und teilweise charakterisieren. Aus diesen Fingerabdrücken die exakten Strukturen zu rekonstruieren, ist jedoch schwierig. Bestehende Datenbanken listen viele bekannte Metaboliten, doch die meisten Signale in realen Proben entsprechen nichts in diesen Katalogen. Diese Lücke deutet darauf hin, dass die derzeitigen Stoffwechselkarten unvollständig sind und viele natürliche Moleküle bei Säugetieren noch nie beschrieben wurden. Die Autoren wollten ein Werkzeug entwickeln, das aus bekannten Metaboliten lernt und dann die plausibelsten fehlenden Moleküle vorstellt — ähnlich wie Sprachmodelle wahrscheinliche Wörter in einem Satz vorhersagen.
Der Maschine die Grammatik des Stoffwechsels beibringen
Das Team trainierte ein neuronales Netzwerk namens DeepMet an etwa 2.000 gut etablierten menschlichen Metaboliten, wobei jedes als kurze Zeichenkette kodiert wurde, die seine Struktur beschreibt. Nach einem ersten Training an arzneimittelähnlichen Molekülen, um allgemeine chemische Regeln zu erlernen, wurde DeepMet an diesem Metabolitensatz feinabgestimmt. Auf Aufforderung neue Strukturen zu erzeugen, produzierte das Modell Moleküle, die dieselben Bereiche des chemischen Raums wie reale Metaboliten belegten, und reproduzierte sogar viele bekannte Enzymreaktionstypen, obwohl es diese Regeln nie explizit gelernt hatte. Anders gesagt schien DeepMet die ungeschriebene Grammatik verinnerlicht zu haben, die Grundbausteine wie Zucker und Aminosäuren zu biologisch realistischen kleinen Molekülen verknüpft.
Vorhersage, welche neuen Moleküle wahrscheinlich existieren
Die Forschenden entnahmen dann eine Milliarde Kandidatenmoleküle aus DeepMet und zählten, wie oft jede einzigartige Struktur auftauchte. Häufig wiederkehrende Strukturen ähnelten eher bekannten Metaboliten, teilten gemeinsame chemische Kerne mit ihnen und passten zu plausiblen Enzymtransformationen. Um zu prüfen, ob diese hochfrequenten Kandidaten realen Molekülen entsprechen, verglich das Team DeepMets Vorhersagen mit Metaboliten, die nach Abschluss der Trainingsdaten in die Human Metabolome Database aufgenommen worden waren. DeepMet hatte die meisten dieser späteren Entdeckungen bereits generiert und viele davon unter seinen wahrscheinlichsten Kandidaten eingestuft. Aus den Tausenden top-gerankter, in Datenbanken fehlender Strukturen kauften oder synthetisierten die Autoren 80 und überprüften reale Humanproben mittels Massenspektrometrie. Sie bestätigten die Existenz mehrerer zuvor unerkannt gebliebener Metaboliten, von denen einige in der vorhandenen Literatur übersehen worden waren.
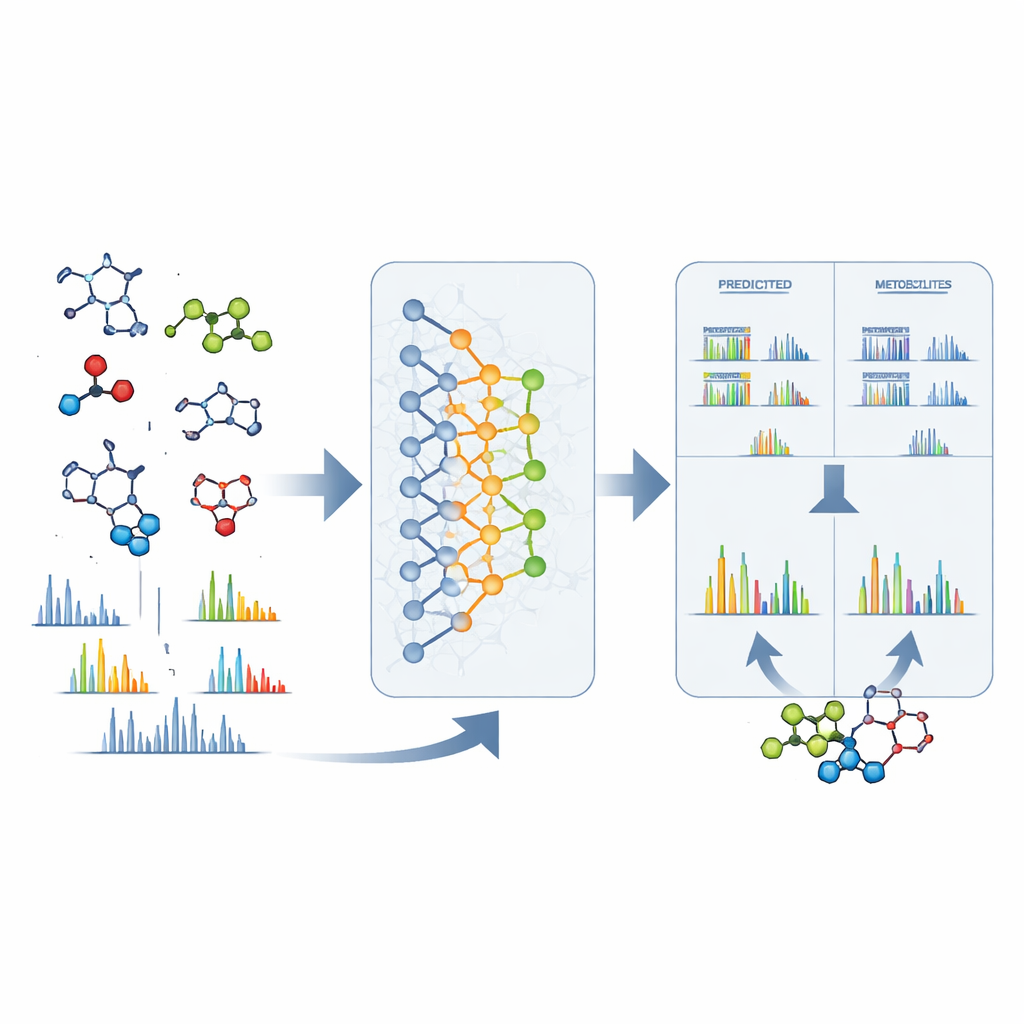
Von Rohsignalen zu konkreten Strukturen
DeepMet ist auch nützlich, wenn ein unbekannter Peak in einem Massenspektrometer auftritt. Allein anhand der exakten Masse eines mysteriösen Moleküls kann das Modell viele Strukturen aufzählen, die das gleiche Gewicht hätten, und sie nach ihrer Metabolit-Ähnlichkeit sortieren. In fast einem Drittel der Testfälle war die korrekte Struktur an oberster Stelle; in vielen weiteren Fällen tauchte sie unter nur wenigen hochrangigen Kandidaten auf und ähnelte meist stark der Favoritin des Modells. Um die Auswahl weiter einzugrenzen, kombinierten die Autoren DeepMet mit separater Software, die vorhersagt, wie jeder Kandidat im Massenspektrometer zerbrechen würde. Das Abgleichen dieser vorhergesagten Muster mit realen Spektren verdoppelte die Identifikationsgenauigkeit annähernd. Die Suche großer öffentlicher Datensätze mit diesem kombinierten Ansatz lieferte vorläufige Strukturen für viele zuvor anonyme Signale und wies auf Metaboliten hin, die sich zwischen Krankheiten, Ernährungsweisen und Mikrobiom‑Zuständen unterscheiden.
Das chemische Dunkelmaterial des Lebens erhellen
Durch die Verbindung von aus Daten gewonnener chemischer Intuition mit leistungsfähigen Musterabgleichen gegen Massenspektren bietet DeepMet eine Roadmap, um neue Metaboliten gezielt und praxisnah zu entdecken. Es kann noch nicht jedes unbekannte Molekül aufdecken — manche Strukturen liegen zu weit entfernt von dem, was es gesehen hat, und bestimmte Isomere bleiben ohne spezialisierte Methoden ununterscheidbar. Die Studie zeigt jedoch, dass Werkzeuge im Stil von Sprachmodellen nicht nur realistische Moleküle erfinden können, sondern auch reale Verbindungen vorhersagen, die Biologen später in Tieren und Menschen bestätigen. Für Laien lautet die Schlussfolgerung: KI kann Chemikern jetzt systematisch helfen, verborgene Chemie in unseren Körpern aufzudecken, möglicherweise neue Biomarker zu enthüllen, Verbindungen zwischen Ernährung, Mikroben und Wirt nachzuzeichnen und das heutige metabolische Dunkelmaterial allmählich in die gut kartierte Biologie von morgen zu verwandeln.
Zitation: Qiang, H., Wang, F., Lu, W. et al. Language model-guided anticipation and discovery of mammalian metabolites. Nature 651, 211–220 (2026). https://doi.org/10.1038/s41586-025-09969-x
Schlüsselwörter: Metabolomik, chemische Sprachmodelle, DeepMet, Massenspektrometrie, metabolisches Dunkelmaterial