Clear Sky Science · de
Aufdeckung zentraler Peak-Merkmale zur Authentifizierung von Olivenöl mithilfe von Raman-Spektroskopie und Chemometrie
Warum die Geschichte des Olivenöl-Betrugs wichtig ist
Wenn Sie für eine Flasche Olivenöl mehr bezahlen, erwarten Sie das Original und nicht eine heimlich mit billigeren Samenölen gestreckte Mischung. Da Olivenöl jedoch wertvoll ist und der weltweite Handel komplex, sind Betrug und Falschdeklaration häufige Probleme. Diese Studie stellt eine schnelle, zerstörungsfreie Methode vor, um solche Tricks zu erkennen: Man bestrahlt die Öle mit Laserlicht und lässt intelligente Computerprogramme die verborgenen chemischen Fingerabdrücke auslesen. Der Ansatz soll Verbrauchende, ehrliche Produzenten und Aufsichtsbehörden schützen, indem er das Überprüfen erleichtert, ob der Inhalt der Flasche mit dem Etikett übereinstimmt.
Mit Licht die Fingerabdrücke von Öl lesen
Die Forschenden verwendeten eine Technik namens Raman-Spektroskopie, bei der ein fokussierter Lichtstrahl auf eine Probe gerichtet und gemessen wird, wie das Licht zurückstreut. Unterschiedliche Moleküle schwingen auf ihre Weise und hinterlassen im resultierenden Spektrum ein Muster von Peaks, ähnlich einem Barcode. Olivenöl und häufige Verfälscher wie Sonnenblumen-, Raps- und Maisöl haben unterschiedliche Mischungen an Fettsäuren und natürlichen Pigmenten, weshalb ihre Spektren nicht identisch sind. Durch das Studium dieser Muster an reinen Ölen und sorgfältig hergestellten Mischungen konnte das Team eine kleine Menge von „Schlüsselpeaks“ identifizieren, deren Form und Stärke zuverlässig variierten, wenn mehr oder weniger Olivenöl in einer Mischung vorhanden war.
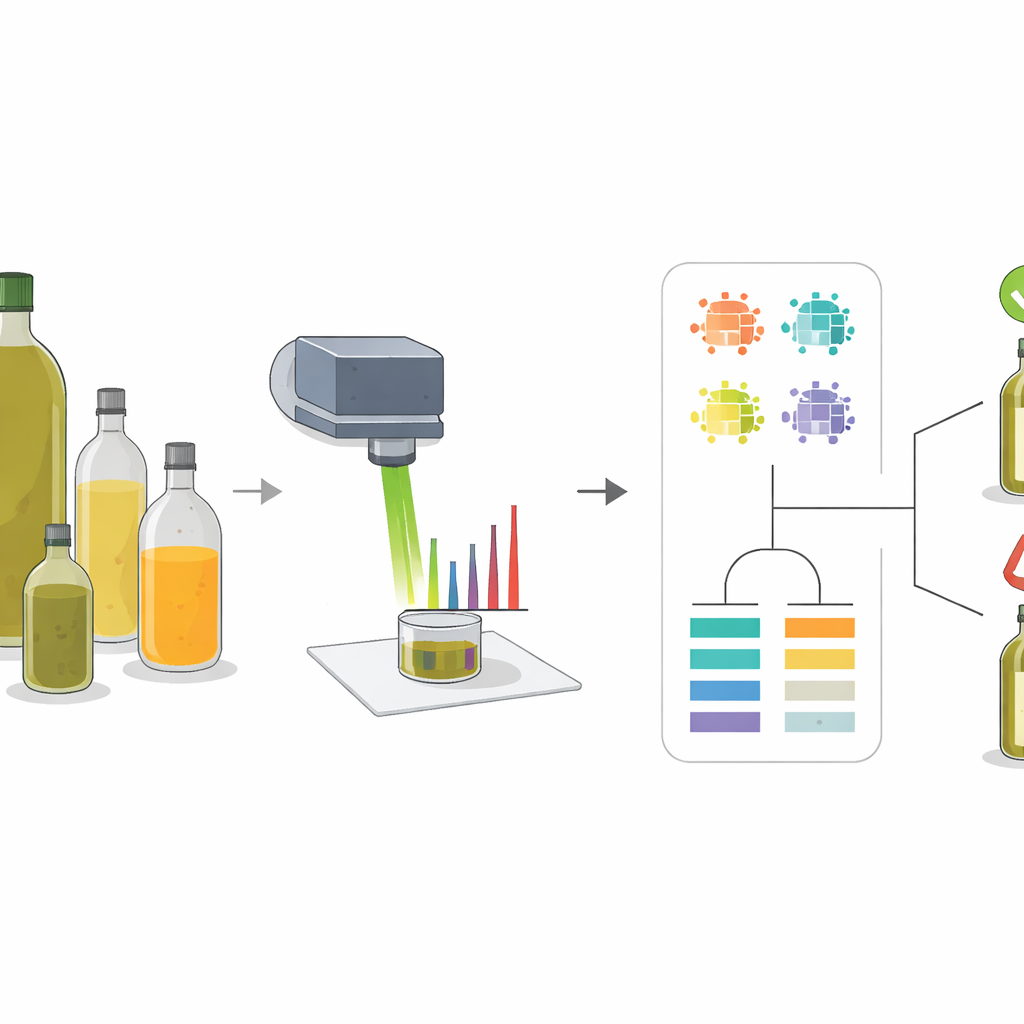
Die aussagekräftigsten Signale finden
Anstatt sich auf eine einzelne Messgröße zu verlassen, extrahierte das Team mehrere Beschreiber aus jedem wichtigen Peak: wie hoch er war (Intensität), welche Fläche er bedeckte, wie breit er auf halber Höhe war und wie seine Fläche im Vergleich zu anderen Peaks stand. Anschließend nutzten sie Cluster- und Korrelationskarten, um zu sehen, wie diese Beschreiber Öle gruppierten und wie sie sich verschoben, wenn der Olivenölanteil zunahm. Peaks, die mit Farbverbindungen wie Beta-Carotin und mit bestimmten Arten ungesättigter Fette verknüpft sind, erwiesen sich als besonders informativ. Beispielsweise wurden bestimmte Peaks stärker, als der Olivenölanteil stieg, während andere abnahmen, weil sie mit Linolsäure verbunden sind, die in Sonnenblumenöl häufiger vorkommt. Diese Multi-Feature-Perspektive erfasste feine Unterschiede, die bei Verwendung nur eines einzelnen Intensitätswerts übersehen würden.
Algorithmen entscheiden lassen, was ehrlich oder verfälscht ist
Um diese spektralen Fingerabdrücke in praktische Entscheidungen zu überführen, trainierten die Autorinnen und Autoren mehrere Maschinenlernmodelle. Zuerst ließen sie die Modelle zehn Öltypen klassifizieren, darunter vier reine Öle und sechs Arten binärer und ternärer Mischungen. Baumgestützte Methoden — Random Forests und gradientenverstärkte Bäume — erzielten die besten Ergebnisse und ordneten fast alle Proben korrekt zu, wenn ihnen der vollständige Satz an Peak-Merkmalen vorlag. Anschließend wurden dieselben Modelltypen für numerische Vorhersagen eingesetzt: die Schätzung des tatsächlichen Prozentsatzes an Olivenöl in Zwei- und Drei-Öl-Mischungen. Auch hier übertrafen die baumbasierten Ansätze traditionellere Methoden und verfolgten den Olivenölanteil genau, selbst wenn sich die Signale verschiedener Öle im Spektrum stark überlappten.
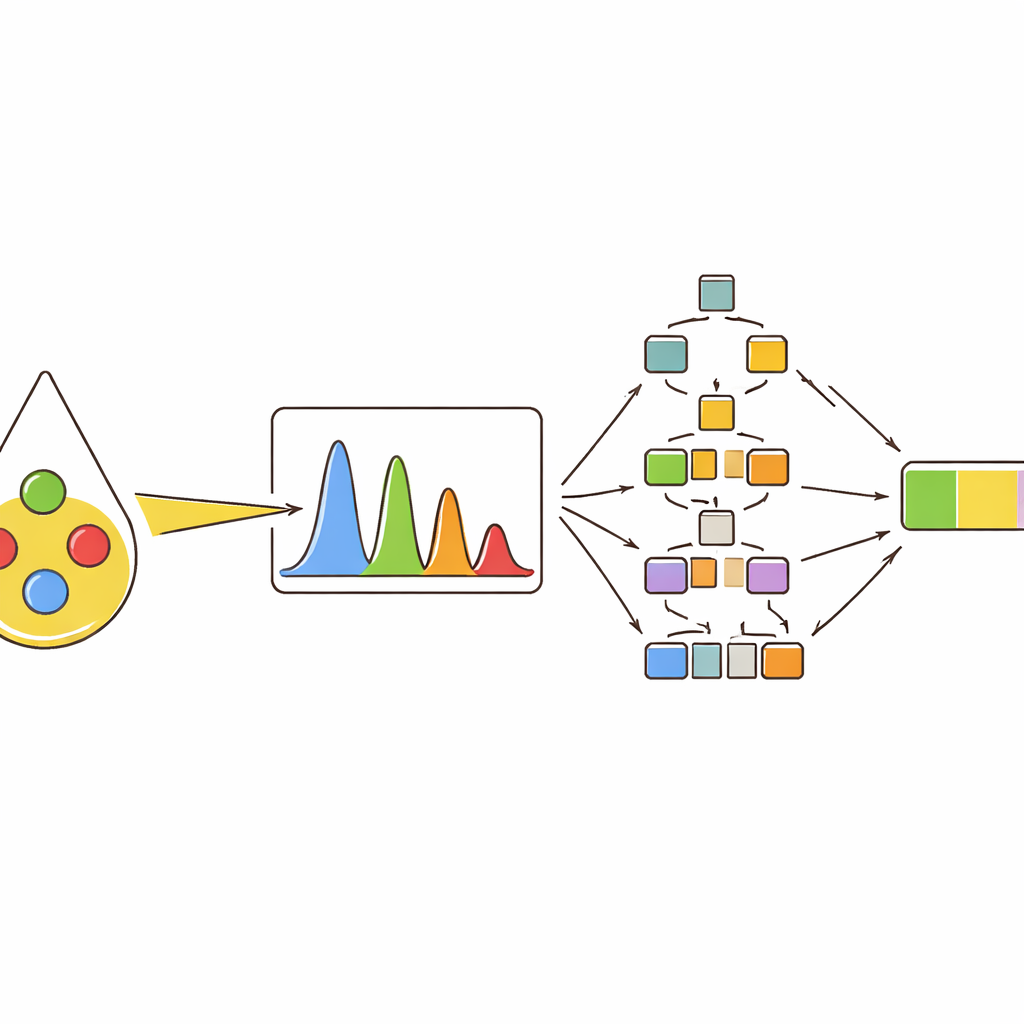
Die Blackbox intelligenter Modelle öffnen
Viele leistungsfähige Maschinenlernwerkzeuge sind schwer zu interpretieren; sie liefern zwar gute Ergebnisse, geben aber kaum Einblick, warum eine bestimmte Entscheidung getroffen wurde. Um dem zu begegnen, nutzte die Studie eine Erklärungsmethode, die jedem Eingangsmerkmal einen Beitrag zur finalen Vorhersage zuweist. Das zeigte, dass wenige spezifische Peaks die Urteile der Modelle dominierten und je nach Wert der Peaks die prognostizierte Olivenölmenge konsequent nach oben oder unten drückten. Dieselben Peaks traten als wichtigste Merkmale in verschiedenen Mischtypen und in Tests mit kommerziellen Supermarktölen wieder auf, die nur einen geringen Olivenölanteil enthielten. Bei diesen Realproben schätzten die besten Modelle den Olivenölgehalt sehr nahe am tatsächlichen Wert, was sowohl Genauigkeit als auch Transparenz des Ansatzes stützt.
Was das für Ihre Flasche zu Hause bedeutet
Alltagsnah zeigt die Arbeit, dass ein schneller, lichtbasierter Scan, interpretiert von gut gestalteten und erklärbaren Computermodellen, erkennen kann, ob ein „Olivenöl“ rein, stark verdünnt oder irgendwo dazwischen ist. Indem man sich auf eine Handvoll robuster spektraler Merkmale konzentriert und diese in fortgeschrittene, dennoch interpretierbare Algorithmen einbindet, entwickelten die Forschenden ein Werkzeug, das in Routine-Qualitätskontrollen integriert werden könnte, möglicherweise sogar in tragbaren Geräten. Zwar sind breitere Tests über mehr Regionen, Sorten und Betrugsarten hinweg noch nötig, doch dieses Rahmenkonzept weist in eine Zukunft, in der die Überprüfung der Ehrlichkeit wertvoller Lebensmittel wie Olivenöl schneller, einfacher und verlässlicher für alle wird.
Zitation: Chen, Y., Shao, R., Zeng, S. et al. Unveiling key peak features for olive oil authentication utilizing Raman spectroscopy and chemometrics. npj Sci Food 10, 88 (2026). https://doi.org/10.1038/s41538-026-00738-2
Schlüsselwörter: Authentifizierung von Olivenöl, Erkennung von Lebensmittelbetrug, Raman-Spektroskopie, maschinelles Lernen, Qualität von Speiseölen