Clear Sky Science · de
Statistik-informierte parametrisierte Quanten-Schaltung: auf dem Weg zur praktischen Quanten-Zustandsvorbereitung und -Lernens über das Prinzip der maximalen Entropie
Umwandlung realer Daten in Quantenzustände
Moderne Quantencomputer versprechen große Vorteile in Finanzen, Wissenschaft und maschinellem Lernen – aber nur, wenn wir zunächst unordentliche reale Daten in die empfindliche Sprache von Quantenzuständen übersetzen können. Dieses Papier stellt einen neuen Ansatz vor, genannt statistik-informierte parametrisierte Quanten-Schaltung (SI-PQC). Indem grundlegende Muster der Daten direkt in die Struktur einer Quanten-Schaltung eingebettet werden, zielt SI-PQC darauf ab, Wahrscheinlichkeitsverteilungen deutlich effizienter auf Qubits zu laden und so viele vorgeschlagene Quantenbeschleunigungen in der Praxis realistischer zu machen.
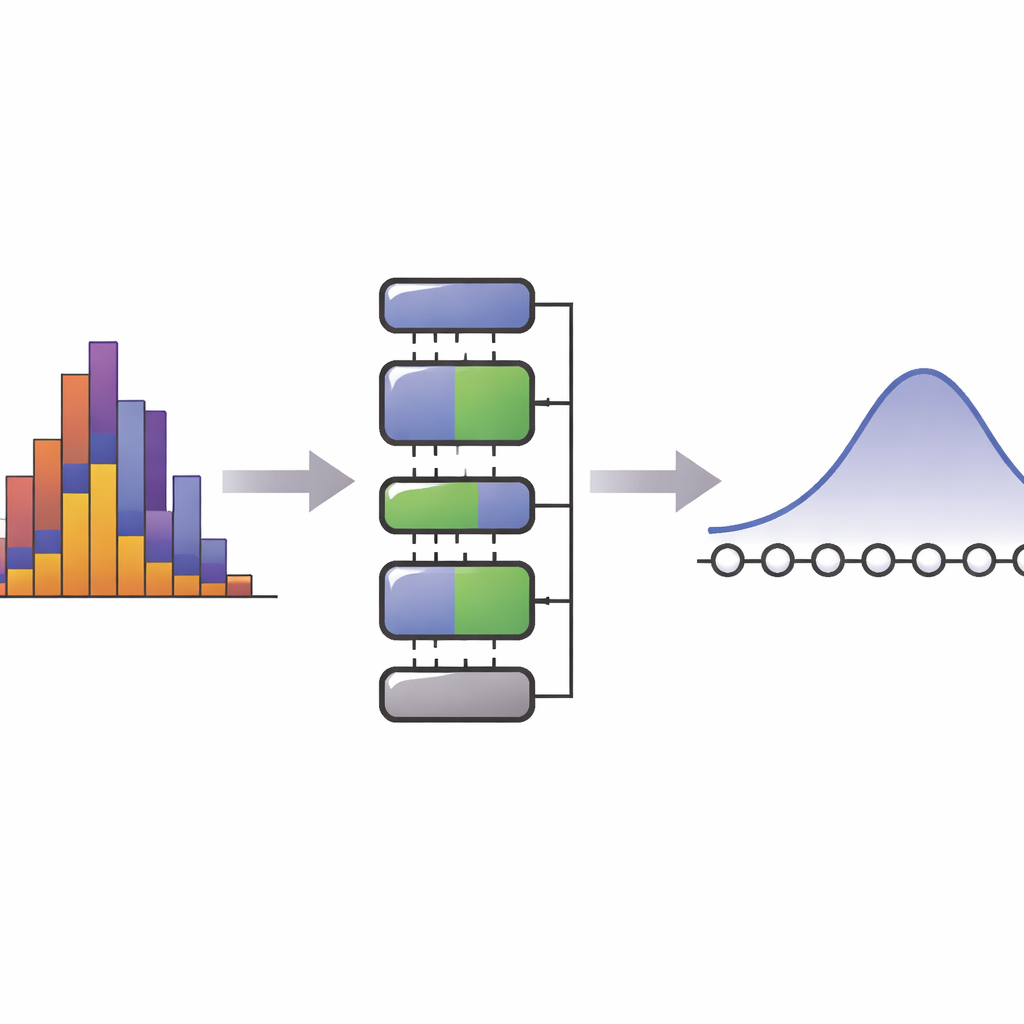
Warum es schwer ist, Daten in Quantenform zu bringen
Bevor ein Quantenalgorithmus laufen kann, muss seine Eingabe als Quanten-Zustand kodiert sein, dessen Amplituden einer Zielwahrscheinlichkeitsverteilung entsprechen – etwa einer Glockenkurve oder einer Mischung mehrerer Gipfel. Einen solchen Zustand allgemein aufzubauen ist berüchtigt aufwendig: Im schlimmsten Fall wächst die Anzahl der Gatter oder Hilfsqubits exponentiell mit der Datengröße. Bestehende Methoden versuchen, Modelle der Daten auszunutzen – etwa mit bekannten Formeln für Standardverteilungen oder durch Training flexibler Quantenschaltungen, um beobachtete Stichproben nachzuahmen. Diese Ansätze haben jedoch oft einen hohen Preis: Sie erfordern beträchtliche Vorverarbeitung oder lange Trainingsläufe, um Modellparameter in Gattereinstellungen zu übersetzen, und dieser Mehraufwand kann die theoretischen Vorteile des Quantenalgorithmus selbst zunichte machen, insbesondere wenn sich Daten oder Modellparameter im Zeitverlauf ändern.
Symmetrie und Unsicherheit als Gestaltungsprinzipien nutzen
Die Schlüsselidee von SI-PQC ist, Daten nicht als beliebige Zahlensammlung zu betrachten, sondern als durch einfache „Symmetrien“ strukturiert – etwa einen festen Mittelwert oder eine feste Streuung. Die Autoren greifen auf das Prinzip der maximalen Entropie zurück, ein Konzept aus Statistik und Physik, das besagt: Unter allen Verteilungen, die mit einer kleinen Menge bekannter Mittelwerte vereinbar sind, ist die ehrlichste, am wenigsten voreingenommene Vermutung diejenige mit der größten Entropie. Viele vertraute Verteilungen – wie die Gauß-Verteilung – lassen sich so erklären. SI-PQC trennt Information in zwei Teile. Ein Teil ist festes Wissen über die Form des Modells und die zu bewahrenden Merkmale. Der andere Teil sind einige wenige einstellbare Parameter, die das noch Unbekannte oder Variierende in den Daten erfassen. In der Schaltung übersetzt sich das in feste Layer, die über Probleme hinweg unverändert bleiben, und eine kompakte Menge verstellbarer Rotationsgatter, die die Modellparameter direkt kodieren.
Quantenverteilungen aufbauen und mischen
Mit diesem Entwurf konstruieren die Autoren einen „Lader für maximal-entropische Verteilungen“, der eine breite Palette typischer Wahrscheinlichkeitsformen auf einer überschaubaren Anzahl von Qubits vorbereiten kann. Sie testen ihre Schaltungen mit Exponential-, Chi-Quadrat-, Gauß- und Rayleigh-Verteilungen und zeigen, dass sich durch Anpassung des Grades einer Polynomapproximation der Quantenzustand sehr nahe an die Zielkurve bringen lässt, während die Schaltungstiefe kontrollierbar bleibt. Auffällig ist, dass die Schaltungsstruktur gleich bleibt, auch wenn sich die Parameter ändern, was Wiederverwendung und aggressive Optimierung ermöglicht. Die Autoren erweitern die Idee dann auf Mischungen von Verteilungen – Situationen, in denen die Unsicherheit von Parametern durch ein weiteres Wahrscheinlichkeitsgesetz beschrieben wird, wie bei Gaussian-Mischmodellen in maschinellem Lernen und Finanzwesen. Ihr „gewichteter Verteilungs-Mischer“ kann sowohl die sichtbaren Daten als auch einen latenten Raum möglicher Parametersetzungen in einem einzigen Quantenzustand kodieren und umgeht damit die exponentielle Explosion, die naivere Quanten-Konstruktionen plagt.
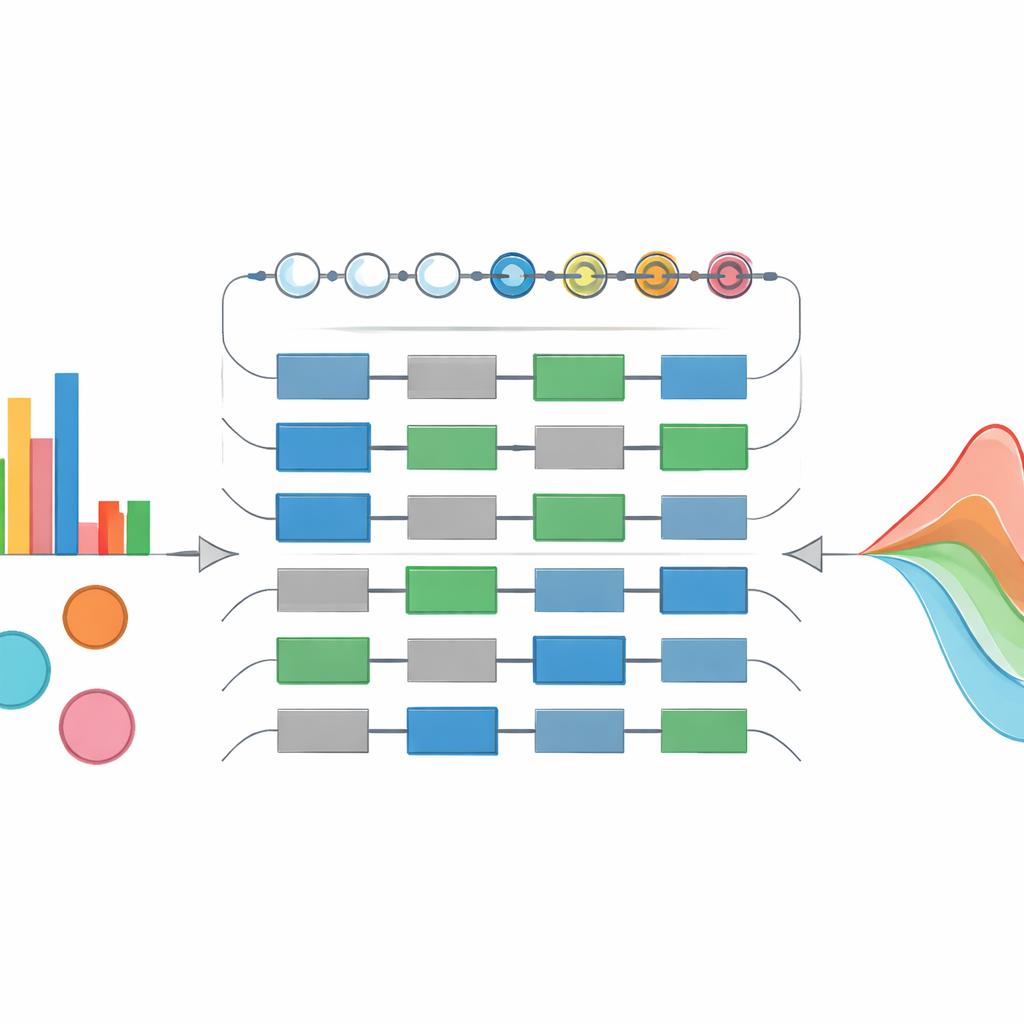
Mit Quantenhilfe aus Daten lernen
Über die Zustandsvorbereitung hinaus dient SI-PQC auch als trainierbares Modell zum Lernen aus Daten. Da die Anzahl freier Parameter in der Schaltung eng auf die Freiheitsgrade des zugrunde liegenden statistischen Modells abgestimmt ist, ist die Trainingslandschaft kleiner und interpretierbarer als bei generischen variationalen Quantenschaltungen. Die Autoren demonstrieren dies, indem sie ein Gaussian-Mischmodell mittels einer hybriden Quanten–Klassik-Schleife anpassen, die Schaltungswinkel so justiert, dass der Abstand zwischen dem vorbereiteten Quantenzustand und den Stichprobendaten minimiert wird. Im Verlauf des Trainings konvergieren sowohl der Quantenzustand als auch die von ihm repräsentierten klassischen Parameter (wie Mittelwerte und Varianzen) zu ihren wahren Werten. Theoretisch sollten solche kompakten, von Symmetrien geleiteten Schaltungen besser generalisieren, weniger Trainingsdaten benötigen und weniger anfällig für flache, „öd“-Regionen ohne Gradienten sein.
Praktische Vorteile in Finanzen und Risiko
Um die Relevanz in der Praxis zu zeigen, untersucht das Papier zwei finanzielle Aufgaben: Preisfindung für Derivate und Risikobewertung. Viele Quantenvorschläge in diesem Bereich beruhen auf Monte-Carlo-ähnlichen Quantenroutinen, die die Schätzung erwarteter Auszahlungen oder Verlustwahrscheinlichkeiten beschleunigen können – vorausgesetzt, die zugrunde liegende Preisverteilung lässt sich schnell auf einem Quantengerät vorbereiten. SI-PQC reduziert die klassische Vorverarbeitungszeit und die Tiefe des zustandsvorbereitenden Teils dieser Algorithmen deutlich und kann seine Parameter in konstanter Zeit aktualisieren, wenn sich Marktbedingungen ändern – entscheidend für Online-Preissetzung und Berechnung der Griechen. Die Autoren entwerfen außerdem ein quantenunterstütztes Verfahren zur Schätzung des Value at Risk direkt aus Streaming-Empiriedaten. Hier dienen einfache laufende Mittelwerte aus klassischen Monitoren als Zwangsbedingungen in einem Maximalentropie-Modell, das SI-PQC in eine approximative Quanten-Version der Echtzeit-Verlustverteilung verwandelt. Quantenzustandsamplituden-Schätzung liefert dann Risikomaße, die eng an denen aus den Rohdaten berechneten Werten liegen.
Was das für die Zukunft bedeutet
Für Nichtfachleute ist die zentrale Botschaft, dass effizientes „Data Loading“ für Quantenüberlegenheit genauso wichtig ist wie die Geschwindigkeit des Quantenalgorithmus selbst. SI-PQC bietet einen prinzipiengeleiteten Weg, diese Lücke zu überbrücken, indem einfache, interpretierbare statistische Strukturen direkt in das Layout von Quantenschaltungen kodiert werden, während der verstellbare Teil klein und flexibel bleibt. Die Autoren zeigen, dass diese Strategie komplexe Verteilungen vorbereiten und lernen, Mischungen natürlich handhaben und die End-to-End-Ressourcen in an Finanzen orientierten Anwendungen deutlich senken kann. Wenn sich diese Ideen auf zukünftiger Hardware skalieren lassen, könnten sie dazu beitragen, Quantencomputing von einem abstrakten Versprechen zu praktischen Werkzeugen in Bereichen wie Echtzeithandel, adaptivem maschinellen Lernen und sogar medizinischer Diagnostik zu machen – überall dort, wo sich statistische Muster schnell ändern und in Quantenzeit erfasst und verarbeitet werden müssen.
Zitation: Zhuang, XN., Chen, ZY., Xue, C. et al. Statistics-informed parameterized quantum circuit: towards practical quantum state preparation and learning via maximum entropy principle. npj Quantum Inf 12, 45 (2026). https://doi.org/10.1038/s41534-026-01191-5
Schlüsselwörter: Quanten-Zustandsvorbereitung, maximale Entropie, Quanten-Maschinelles Lernen, Gaussian-Mischmodelle, Quanten-Finanzwesen