Clear Sky Science · de
Text‑Mining‑unterstützte Machine‑Learning‑Vorhersage und experimentelle Validierung von Emissionswellenlängen
Wissenschaftlichen Text in Licht verwandeln
Jedes Jahr veröffentlichen Forschende Zehntausende Artikel über Materialien, die leuchten – Stoffe, die in Telefonbildschirmen, medizinischen Scannern und Strahlungsdetektoren eingesetzt werden. In diesen Publikationen stecken Messungen darüber, welche Farben verschiedene Materialien abgeben, doch die Informationen sind verstreut, uneinheitlich formuliert und für Computer schwer nutzbar. Diese Studie zeigt, wie man die Fachliteratur automatisch ausliest, in einen großen, zuverlässigen Datensatz überführt und anschließend Machine Learning verwendet, um die Farbe des Lichts vorherzusagen, das neue Materialien abgeben werden – so können Forschende bessere Phosphore deutlich schneller entwerfen.
Warum leuchtende Materialien wichtig sind
Phosphore sind Materialien, die Energie aufnehmen und als sichtbares Licht wieder abstrahlen. Sie stehen im Zentrum von Technologien wie Ultra‑HD‑Displays, weißen LEDs, medizinischer Bildgebung und Strahlungsdetektion. Ingenieure wünschen sich Phosphore, die in ganz bestimmten Farben leuchten, auch bei hohen Temperaturen hell bleiben und möglichst wenig Energie verschwenden. In den vergangenen zwei Jahrzehnten ist die Forschung zu diesen Materialien explodiert und hat die Fachliteratur mit detaillierten Berichten über chemische Rezepturen und Emissionswellenlängen gefüllt. Diese Daten sind jedoch überwiegend in unstrukturiertem Text eingeschlossen – Formulierungen in Absätzen, Bildunterschriften und Methodenabschnitten, die für Menschen, nicht für Maschinen geschrieben sind. 
Computern beibringen, Materialien‑Artikel zu lesen
Die Autorinnen und Autoren entwickelten eine spezialisierte Text‑Mining‑Pipeline, die speziell auf die Phosphorforschung zugeschnitten ist. Anstatt generische Sprachwerkzeuge zu verwenden, entwarfen sie Regeln, die verstehen, wie Chemiker tatsächlich Formeln schreiben, insbesondere für „dotierte“ Materialien, bei denen eine geringe Menge eines Elements in ein Wirtsgitter eingedrungen ist. Ihr System erkennt korrekt komplexe Bezeichnungen wie ein Wirtsgitter gefolgt von mehreren Dotierionen und deren Konzentrationen und kann diese Bezeichnungen mit nahe stehenden Zahlen verknüpfen, die Emissionswellenlängen darstellen. Es bewältigt auch knifflige Formulierungen, etwa Sätze, die „es emittiert bei 630 nm“ sagen, ohne den Materialnamen zu wiederholen, oder Absätze, in denen mehrere Materialien und mehrere Wellenlängen zusammen erwähnt werden. Indem jede Satzstruktur danach klassifiziert wird, wie viele Materialien und Eigenschaften sie enthält, und dann ein passender Zuordnungsalgorithmus gewählt wird, reduziert die Pipeline Verwechslungen deutlich, welche Zahl zu welchem Material gehört.
Eine saubere Karte von Zusammensetzung zu Farbe erstellen
Mit dieser Pipeline angewendet auf 16.659 Fachartikel extrahierte das Team ungefähr 6.400 zuverlässige „Material–Emission“-Paare: die Formel eines Phosphors, seine Emissionspeak‑Wellenlänge, die Einheit und die digitale Kennung des Artikels. Sorgfältige Tests zeigten hohe Genauigkeit sowohl beim Erkennen vollständiger Phosphorformeln als auch beim Verknüpfen mit den korrekten Emissionswerten. Mit diesem strukturierten Datensatz konzentrierten sich die Forschenden auf eine besonders wichtige Familie: Materialien, die mit Europium‑Ionen (Eu²⁺) dotiert sind, welche je nach umgebendem Kristall ein breites Spektrum des sichtbaren Lichts emittieren können. Sie berechneten physikalisch sinnvolle Deskriptoren für jeden Wirtsstoff – etwa Details zur Kristallstruktur, Bindungslängen und elektronische Bandlücke – und verwendeten anschließend Feature‑Selection‑Methoden, um diese auf die wenigen Merkmale einzugrenzen, die für die Vorhersage der Farbe am wichtigsten sind.
Machine Learning die Leuchtfarbe vorhersagen lassen
Als Nächstes trainierten und verglichen die Autorinnen und Autoren mehrere Machine‑Learning‑Modelle, um die Emissionswellenlänge aus diesen Deskriptoren vorherzusagen. Ein Algorithmus namens XGBoost erreichte die besten Ergebnisse und erzielte einen Bestimmtheitskoeffizienten (R²) von etwa 0,91 auf ungesehenen Testdaten – ein starkes Indiz dafür, dass das Modell die wesentlichen Zusammenhänge zwischen Struktur und Farbe erfasst. Um zu prüfen, ob der Ansatz in der Praxis funktioniert, nutzten sie das Modell, um vielversprechende neue Eu²⁺‑dotierte Sulfid‑ und Nitrid‑Phosphore vorzuschlagen, synthetisierten vier Kandidaten im Labor und maßen deren Emission. Die gemessenen Wellenlängen lagen nur etwa 10 Nanometer neben den Vorhersagen, was bedeutet, dass die Modell‑„Vermutungen“ sehr nahe an der experimentellen Realität waren. 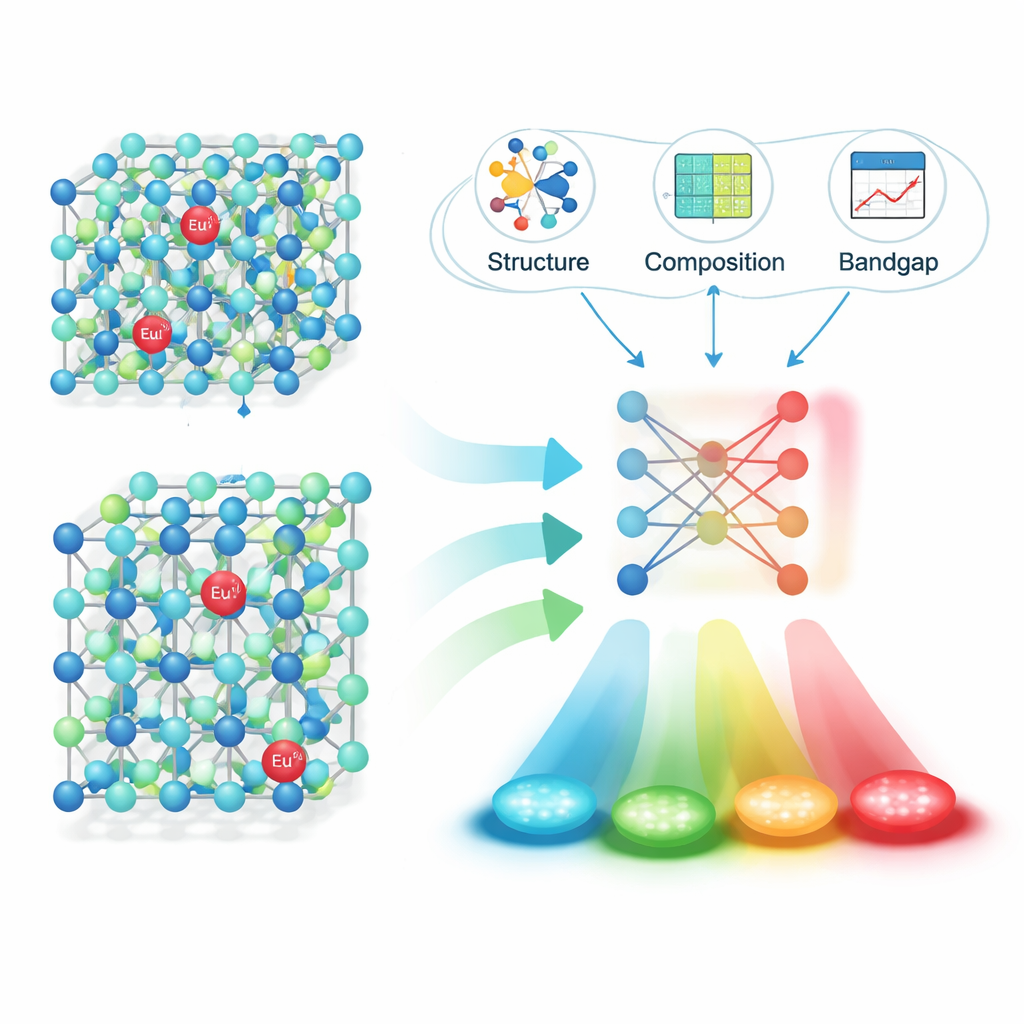
Von Publikationen zu praktischen Entwürfen
Für Nicht‑Spezialisten ist die Kernbotschaft, dass diese Arbeit verstreute, von Menschen geschriebene Artikel in eine kohärente, durchsuchbare Karte verwandelt, die „woraus ein Material besteht“ mit „welcher Farbe es leuchtet“ verbindet. Indem das Lesen, Organisieren und Lernen automatisiert und die Vorhersagen anschließend durch reale Experimente bestätigt werden, skizziert die Studie einen geschlossenen Kreislauf: Text → Daten → Modell → neues Material. Dieses Framework lässt sich auf andere Eigenschaften wie Helligkeit und Stabilität und sogar auf andere Klassen funktionaler Materialien erweitern. Damit weist es auf eine Zukunft hin, in der Forschende statt mit Trial‑and‑Error rasch die vielversprechendsten Rezepturen identifizieren können, wodurch die Entwicklung besserer Beleuchtungs‑, Anzeige‑ und Sensortechnologien beschleunigt wird.
Zitation: Huang, L., Zhang, X., Li, S. et al. Text mining-assisted machine learning prediction and experimental validation of emission wavelengths. npj Comput Mater 12, 98 (2026). https://doi.org/10.1038/s41524-026-01967-5
Schlüsselwörter: leuchtende Materialien, Text‑Mining, Machine Learning, Phosphore, Vorhersage von Emissionswellenlängen