Clear Sky Science · de
Nanoporen-basierte massiv parallele Sensorik zur Peptidprofilierung und Proteinerkennung
Proteine einzeln lesen
Proteine sind die Arbeitspferde unserer Zellen, und genau zu wissen, welche davon vorhanden sind, wie sie modifiziert sind und wie sie interagieren, ist zentral für das Verständnis von Gesundheit und Krankheit. Die heute üblichen Werkzeuge zur Untersuchung von Proteinen sind leistungsfähig, aber oft langsam, teuer und schwer zu skalieren. Dieses Papier beschreibt eine neue Methode, um einzelnen Proteinfragmenten zuzuhören, während sie durch ein winziges Loch in einer Membran passieren, und mit Hilfe künstlicher Intelligenz diese Signale in detaillierte Fingerprints zu verwandeln. Der Ansatz könnte den Weg für schnellere, günstigere Tests zum Nachverfolgen von Krankheitsmarkern und zur Überprüfung, wie gut Forschungs- und Diagnostikantikörper tatsächlich funktionieren, öffnen.
Proteine in lesbare Stücke verwandeln
Die Forschenden bauen auf Nanoporen-Technologie auf, die ursprünglich für die DNA-Sequenzierung entwickelt wurde. In ihrem System werden natürliche Proteine zunächst in kürzere Fragmente, sogenannte Peptide, geschnitten und schonend modifiziert, sodass jedes Teil an beiden Enden an kurze DNA-Stücke gekoppelt werden kann. So entsteht eine „Oligo–Peptid–Oligo“-Struktur, die sich in Nanoporen-Geräten, die für DNA ausgelegt sind, gut verhält. Das Team nutzt ein spezifisches Schneideenzym, das dazu neigt, an jedem Fragment ein bestimmtes Aminosäurerest, Lysin, am Ende zu hinterlassen, wodurch die Chemie vorhersehbarer und mit vielen Proteinen kompatibel wird. Das Endergebnis ist eine gereinigte Bibliothek vieler solcher Peptid–DNA-Konstrukte, die in nur wenigen Stunden hergestellt werden kann.
Mit vielen Nanoporen gleichzeitig hören
Um diese Peptidfragmente tatsächlich zu detektieren, verwenden die Autorinnen und Autoren ein Array biologischer Nanoporen — winzige, aus Proteinen gefertigte Löcher in einer Membran, die mit Elektroden verbunden sind. Wenn eine Spannung angelegt wird, werden die DNA–Peptid–DNA-Strukturen von einem molekularen Motor nacheinander durch jede Pore gezogen. Wenn das Peptid durch den engsten Bereich passiert, blockiert es teilweise den Ionenfluss und verändert den elektrischen Strom. Weil die Plattform 256 Poren parallel nutzt und innerhalb von zwei Stunden über 100.000 solche Ereignisse aus einer einzigen Bibliothek erfassen kann, erzeugt sie einen massiven Strom von Einzelmolekülsignalen, die festhalten, wie jedes einzelne Peptid mit der Pore wechselwirkt. 
Von verrauschten Signalen zu klaren Fingerprints
Auf den ersten Blick wirken diese Stromverläufe verrauscht und variabel; dasselbe Peptid kann in unterschiedlichen Orientierungen eintreten und verschiedene Konformationen annehmen. Traditionelle zusammenfassende Größen wie mittlerer Strom und Ereignisdauer überlappen oft zwischen ähnlichen Peptiden. Der entscheidende Fortschritt dieser Arbeit ist eine zweistufige KI-Pipeline. Zuerst wird ein tiefes konvolutionales neuronales Netz mit großen Mengen an Verläufen trainiert, um zu klassifizieren, welches Peptid welches Muster erzeugt hat. Anschließend erstellt das Team „Dichte-Matrizen“, die zusammenfassen, wie das Signal im Verlauf jedes Ereignisses typischerweise variiert, und so Wolken verrauschter Verläufe in stabile 2D-Fingerprints verwandeln. Nur Lesevorgänge, deren detaillierte Zeitmuster zu diesen Fingerprints passen, werden beibehalten. Diese CNN-plus-Fingerprint-Strategie erhöht die Genauigkeit für Testpeptide auf etwa 99 % und kann zuverlässig Fragmente unterscheiden, die sich in nur einer Aminosäure unterscheiden, bestimmte Isomere und viele gängige chemische Modifikationen, die Proteine in Zellen erwerben.
Antikörper prüfen und ganze Proteine finden
Da Antikörper kurze Proteinabschnitte erkennen, wenden die Autorinnen und Autoren ihre Plattform an, um zu kartieren, welche Fragmente verschiedene kommerzielle Antikörper tatsächlich binden. Indem sie überlappende Peptidstücke eines Hormon-Vorläufers mischen, diejenigen anreichern, die von jedem Antikörper gebunden werden, und diese dann mit dem Nanoporen-System lesen, können sie bevorzugte Bindungsregionen punktgenau bestimmen und zeigen, wann von Anbietern empfohlene Antikörperpaare tatsächlich dieselbe Stelle erkennen und für Sandwich-Assays schlecht zueinander passen. In einem weiteren Test untersuchen sie eine bekannte Tag-Sequenz und vier nahezu identische Varianten und zeigen, dass die relative Anzahl der Nanoporen-Lesungen für jedes Peptid eng mit der Antikörperbindestärke korreliert — im Einklang mit aufwendigeren, oberflächenbasierten Messungen. Schließlich demonstrieren sie die Proteinerkennung: Sie trainieren das System auf Peptid-Fingerprints von drei menschlichen Proteinen, verdauen dann die vollständigen Proteine unbeaufsichtigt und zeigen, dass das kombinierte Muster der klassifizierten Peptide ausreicht, um korrekt zu bestimmen, welches Protein vorliegt, selbst bei einigen mehrdeutigen oder fehlenden Fragmenten. 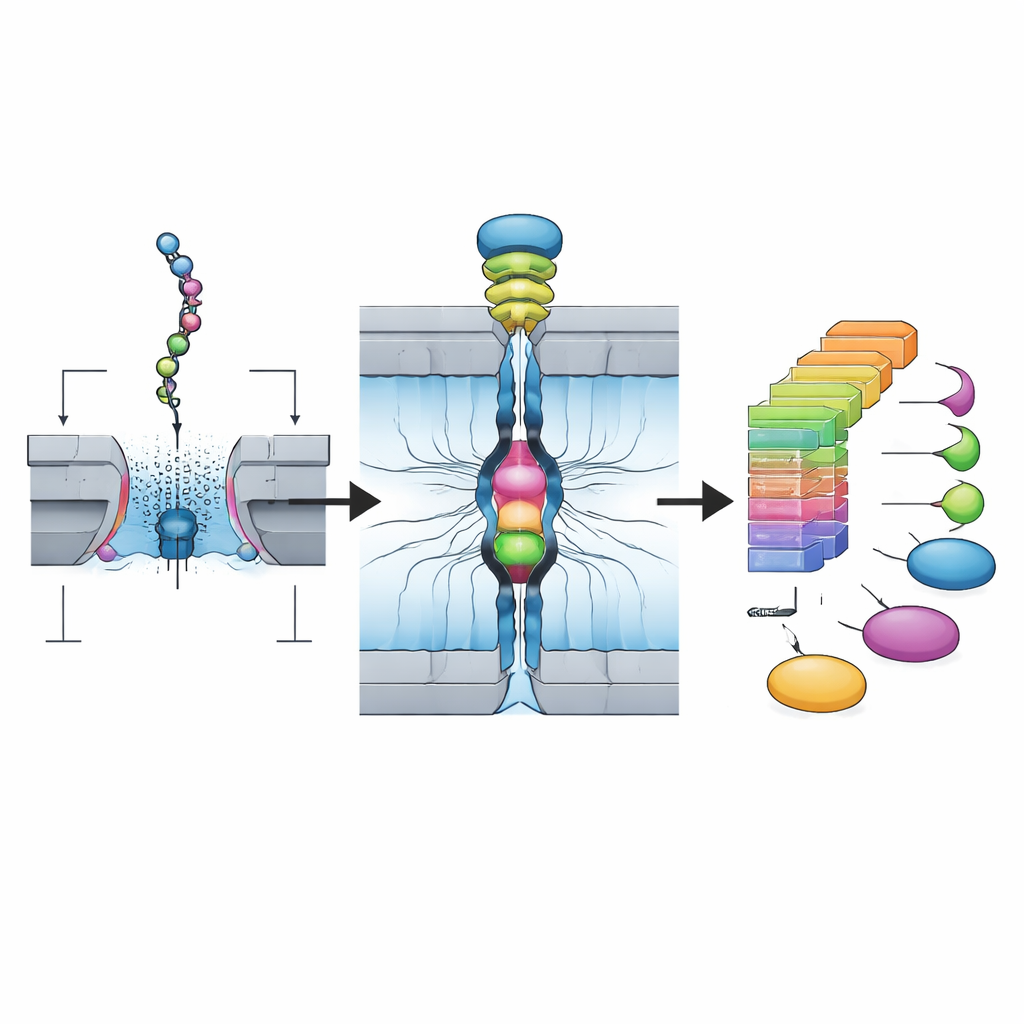
Warum das für zukünftige Tests wichtig ist
Einfach gesagt zeigt die Studie, dass ein DNA-ähnlicher Nanoporen-Sequenzer, kombiniert mit kluger Chemie und KI, als hochparalleles „Stethoskop“ für Proteinfragmente fungieren kann. Anstatt jede Aminosäure in der Reihenfolge lesen zu müssen, stützt sich das System auf reichhaltige, statistische Fingerprints aus Tausenden Einzelmolekülereignissen, um subtile Unterschiede in Ladung, Größe und Modifikation zu unterscheiden. Das ermöglicht schnelle, kostengünstige Prüfungen der Antikörperqualität und bietet einen Weg, ganze Proteine anhand ihrer Peptidmuster zu erkennen. Zwar gibt es weiterhin Grenzen — etwa Probleme mit bestimmten Peptidtypen und die Notwendigkeit guter Trainingsdaten — doch die Arbeit skizziert eine durchgängige Pipeline, die dazu beitragen könnte, routinemäßige, hochdurchsatzfähige Proteinanalytik näher an Labore der alltäglichen Forschung und schließlich an die klinische Diagnostik zu bringen.
Zitation: Wang, J., Chen, J., Pan, H. et al. Nanopore-based massively parallel sensing for peptide profiling and protein identification. Nat Commun 17, 3058 (2026). https://doi.org/10.1038/s41467-026-69628-1
Schlüsselwörter: Nanoporensensorik, Proteomik, Peptid-Fingerprinting, Antikörpervalidierung, Proteinidentifikation