Clear Sky Science · de
Ein 7T-fMRI-Datensatz synthetischer Bilder zur Modellierung von Out-of-Distribution-Sehen
Warum das für das Verständnis von Sehen und KI wichtig ist
Unsere Augen nehmen täglich eine enorme Vielfalt von Bildern auf, von Wäldern und Gesichtern bis zu Straßenschildern und Bildschirmrauschen. Dennoch basieren die meisten Hirn- und KI‑Studien auf einem engen Ausschnitt dieser visuellen Welt: Fotografien natürlicher Szenen. Dieses Paper stellt einen neuen Datensatz vor, der bewusst aus dieser Komfortzone ausbricht und sorgfältig entworfene synthetische Bilder verwendet, um sowohl unsere Theorien des menschlichen Sehens als auch die davon inspirierten KI‑Modelle auf die Probe zu stellen.
Aufbau eines neuen visuellen Prüfstands
Die Autor:innen erweitern den einflussreichen Natural Scenes Dataset (NSD), der ultra‑hochaufgelöste Hirnaktivität bei 7‑Tesla‑MRT aufzeichnete, während Probanden zehntausende Fotografien betrachteten. Dieser ursprüngliche Datensatz hat bereits einige der genauesten Modelle dafür ermöglicht, wie der visuelle Kortex auf Bilder reagiert. Da aber alle diese Bilder relativ gewöhnliche Fotos sind, ist schwer zu sagen, ob ein Modell, das im NSD gut funktioniert, wirklich allgemeine Prinzipien des Sehens erfasst oder sich einfach auf diese spezielle Bildkost spezialisiert hat. Um dem entgegenzuwirken, scannte das Team dieselben acht Freiwilligen erneut und zeigte ihnen 284 „synthetische“ Bilder, die bewusst außerhalb der üblichen Fotowelt liegen.
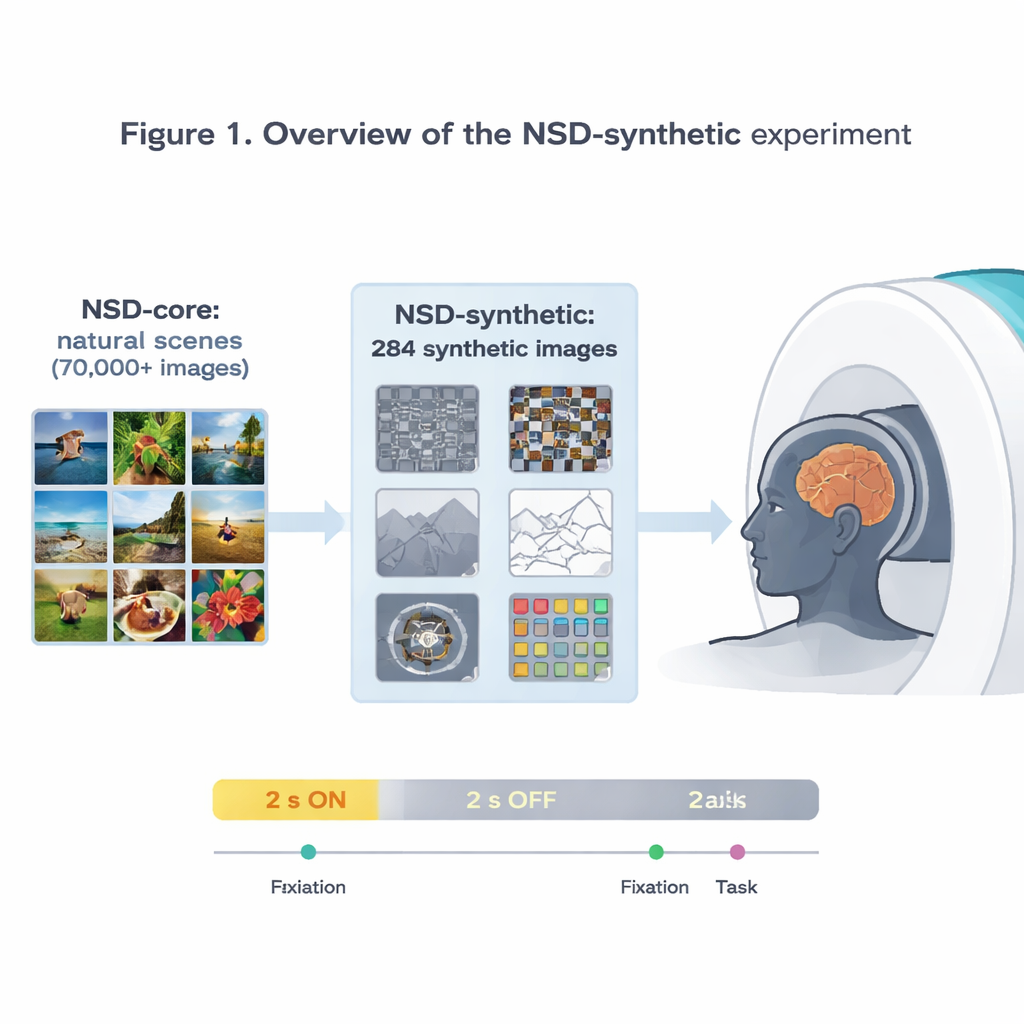
Seltsame Bilder, verlässliche Hirnantworten
Die synthetischen Bilder umfassen acht Familien: verschiedene Arten visuellen Rauschens, einfache Naturszenen und ihre veränderten Versionen (wie umgedreht oder als Strichzeichnungen), Szenen mit reduziertem Kontrast oder zerfetzter Phase, einzelne Wörter an verschiedenen Positionen, Spiral‑Gitter zur Untersuchung der Sensitivität für feine Muster und kräftig gefärbte Rauschflecken. Während die Probanden entweder auf einen winzigen flackernden Punkt fokussierten oder eine einfache Bildvergleichsaufgabe ausführten, maßen die Forschenden die Hirnaktivität alle 1,6 Sekunden. Sie zeigen, dass diese ungewöhnlichen Stimuli dennoch starke, zuverlässige Signale erzeugen, insbesondere in frühen visuellen Arealen, die auf grundlegende Merkmale wie Kanten, Kontrast und Farbe reagieren. Aktivitätsmuster über die Großhirnrinde hinweg stimmen mit bekannten Präferenzen spezialisierter Regionen überein, etwa einem wortselektiven Bereich, der am stärksten auf zentral platzierte Wörter reagiert, und einem szenenselektiven Bereich, der am stärksten auf Umgebungsbilder anspricht.
Nachweis, dass die Daten wirklich „out of distribution“ sind
Damit dieser neue Datensatz Modelle herausfordern kann, müssen seine Hirnantworten sich tatsächlich von denen unterscheiden, die durch natürliche Fotografien ausgelöst werden. Die Autor:innen komprimieren Aktivitätsmuster sowohl aus dem ursprünglichen NSD als auch aus der synthetischen Sitzung in eine zweidimensionale Karte, die widerspiegelt, wie ähnlich die Antworten auf verschiedene Bilder sind. In diesem Raum gruppieren sich die Antworten auf synthetische Bilder getrennt von denen auf natürliche Fotos, selbst wenn Unterschiede zwischen Scan‑Sitzungen berücksichtigt werden. Darüber hinaus ordnen sich die synthetischen Bilder naturgemäß nach ihrem visuellen Typ—Rauschen mit Rauschen, Gitter mit Gittern usw.—und zeigen, dass das Gehirn diese Stimuli nach ihrer zugrundeliegenden Struktur organisiert, nicht nur nach ihrer oberflächlichen Erscheinung.
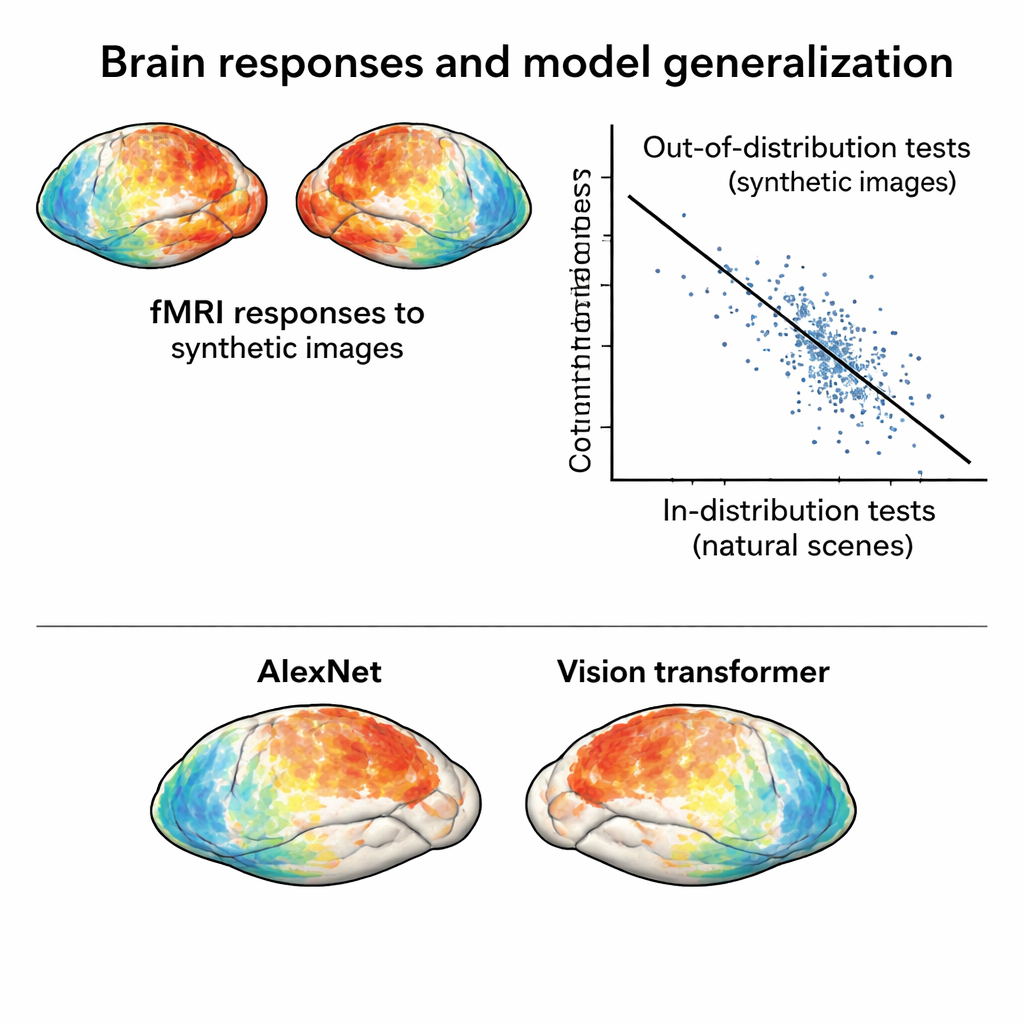
Hirn- und KI‑Modelle auf härterer Probe
Mithilfe dieses neuen „out‑of‑distribution“-Datensatzes trainiert das Team Standard‑Encoding‑Modelle: mathematische Werkzeuge, die Hirnantworten aus Bildmerkmalen vorhersagen, die von tiefen neuronalen Netzen extrahiert wurden. Modelle, die nur auf den natürlichen Fotos trainiert wurden, schneiden bei ähnlichen Fotos gut ab, aber ihre Genauigkeit sinkt deutlich, wenn sie Antworten auf die synthetischen Bilder vorhersagen sollen. Dieser Einbruch ist nicht auf verrauschte Daten zurückzuführen—die synthetischen Antworten sind tatsächlich sehr sauber—sondern auf echte Modellfehler. Entscheidend ist, dass der Vergleich verschiedener Netzwerkarchitekturen unter diesen härteren Bedingungen Unterschiede offenlegt, die in In‑Distribution‑Tests kaum sichtbar sind. Zum Beispiel schneiden ein moderner Vision Transformer und ein selbstüberwachtes Netzwerk bei synthetischen Bildern besser ab als klassische konvolutionale Netze, was nahelegt, dass die Art des Trainings die Robustheit stark prägt.
Wie weit können Modelle von vertrauten Bildern abweichen?
Die Autor:innen gehen weiter und behandeln die „Distanz“ zu den Trainingsdaten als Kontinuum, nicht als binäres Merkmal. Sie messen, wie weit die Hirnantwort zu jedem Bild von der Wolke der Antworten auf natürliche Szenen entfernt liegt. Je weiter ein synthetisches Bild in diesem Raum entfernt ist, desto schlechter schneiden Modelle tendenziell ab und desto ungenauer können sie feststellen, welches Bild eine Person gesehen hat, wenn man nur die Hirnaktivität verwendet. Sie zeigen auch, dass selbst innerhalb der Welt gewöhnlicher Fotografien clever gewählte Testsets als „leicht out of distribution“ fungieren können: Modelle sind am besten auf Bildern, die aus demselben Cluster wie ihr Trainingsset stammen, weniger gut bei entfernten natürlichen Szenen und am schlechtesten bei den synthetischen Stimuli. Dieses gestufte Bild macht den neuen Datensatz zu einem Werkzeug, um genau zu untersuchen, welche Arten visueller Struktur aktuelle Modelle verpassen.
Was das für künftige Hirn‑ und KI‑Forschung bedeutet
Für Nicht‑Spezialist:innen lautet die Kernbotschaft: Gute Leistung auf vertrauten Bildern garantiert nicht, dass ein von Hirnmodellen inspiriertes KI‑System wirklich erfasst hat, wie wir sehen. Durch die Veröffentlichung von NSD‑synthetic zusammen mit dem ursprünglichen NSD stellen die Autor:innen eine öffentliche „Crash‑Test‑Strecke“ für Sehmodelle bereit: eine Möglichkeit zu sehen, wo sie versagen, wenn die Bilder abstrakter, farbenfroher oder weniger natürlich werden. Weil der Datensatz offen verfügbar ist und eng in eine bereits weitverbreitete Ressource integriert ist, wird er mit hoher Wahrscheinlichkeit zu einem Standard‑Benchmark, um Theorien des menschlichen Sehens und die künstlichen Netze, die es nachahmen sollen, zu testen und zu verbessern.
Zitation: Gifford, A.T., Cichy, R.M., Naselaris, T. et al. A 7T fMRI dataset of synthetic images for out-of-distribution modeling of vision. Nat Commun 17, 1589 (2026). https://doi.org/10.1038/s41467-026-69345-9
Schlüsselwörter: visueller Kortex, fMRI-Datensatz, synthetische Bilder, out-of-distribution, tiefe neuronale Netze