Clear Sky Science · de
Rechenmechanismen einzelner Neuronen für die Kodierung visueller Objekte im menschlichen Temporallappen
Wie das Gehirn weiß, was wir ansehen
Jedes Mal, wenn Sie über eine belebte Straße blicken, sagt Ihnen Ihr Gehirn sofort, welche Formen Menschen, welche Autos und welche Schilder sind, selbst wenn sie teilweise verdeckt oder ungewöhnlich beleuchtet sind. Diese Arbeit stellt eine auf den ersten Blick einfache Frage: Wie wandelt das menschliche Gehirn die Flut roher visueller Details, die auf unsere Augen trifft, in stabile Begriffe wie „Hund“ oder „Tasse“ um, die wir erkennen, speichern und benennen können?
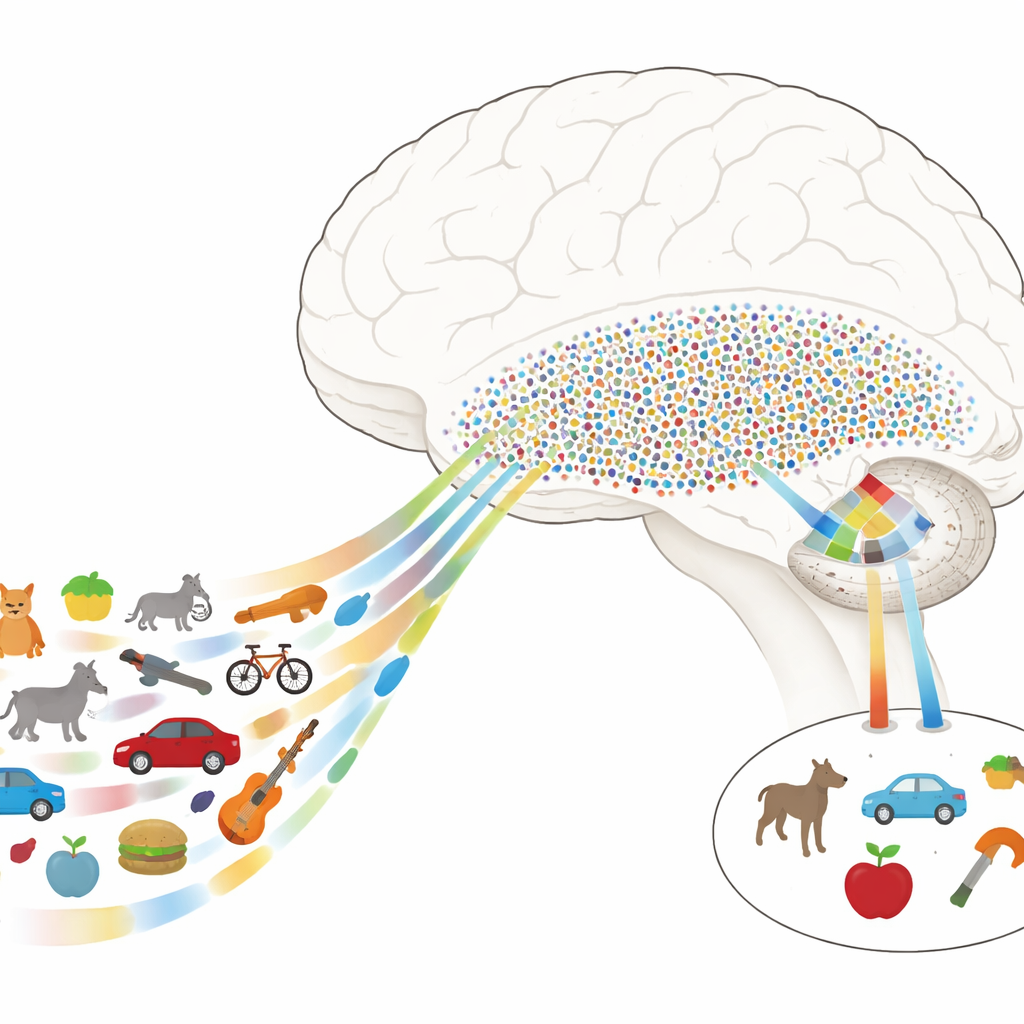
Von detailreichen Bildern zu bedeutungsvollen Dingen
Wissenschaftler wissen, dass die Objekterkennung stark von einer Kette von Regionen auf der Unterseite des Gehirns abhängt, dem ventralen visuellen Pfad. Frühe Stadien verarbeiten einfache Merkmale wie Kanten und Texturen, während spätere Stadien mehr auf vollständige Objekte und deren Bedeutung achten. Beim Menschen ist ein zentraler Abschnitt dieses Pfads der ventrale temporale Kortex (VTC), und direkt dahinter liegt der mediale Temporallappen (MTL), der für das Gedächtnis entscheidend ist. Das Rätsel war, wie das Gehirn von den detailreichen, bildhaften Beschreibungen des VTC zu den sparsamen, begrifflichen Codes des MTL gelangt, bei denen wenige Neuronen für viele verschiedene Ansichten desselben Objekts stehen können.
Eine neuronale Karte des Objekt-Raums
Die Autoren zeichneten elektrische Aktivität direkt aus den Gehirnen von Epilepsiepatienten auf, die aus medizinischen Gründen bereits Elektroden implantiert hatten. Während die Patienten eine einfache Aufgabe ausführten, betrachteten sie Hunderte natürlicher Bilder aus vielen Kategorien — Tiere, Werkzeuge, Lebensmittel, Fahrzeuge, Pflanzen und mehr. Im VTC fanden die Forscher, dass sich die Antworten als Kombinationen weniger wichtiger Merkmalsrichtungen oder „Achsen“ beschreiben ließen, etwa wie natürlich versus von Menschen gemacht etwas erscheint, oder wie belebt versus unbelebt es ist. Durch mathematische Kombination dieser Achsen bauten sie einen „neuronalen Merkmalsraum“, in dem jedes Bild einen Ort einnimmt und ähnliche Objekte zusammen gruppiert sind, selbst wenn sie sich in niedrigen visuellen Details unterscheiden.
Vom dichten Merkmalsgitter zu sparsamen Konzeptzentren
In diesem neuronalen Merkmalsraum wirkt das VTC wie ein dichtes Gitter: Viele Stellen beteiligen sich an der Darstellung jedes Objekts und kodieren feine visuelle Unterschiede. Im Gegensatz dazu verhielten sich einzeln aufgezeichnete Neuronen im MTL sehr anders. Anstatt einzelne Merkmale nachzuverfolgen, reagierten viele dieser Zellen nur stark auf Objekte, die in bestimmten Regionen des VTC-Merkmalsraums lagen. Jede solche Neuron hatte effektiv ein „rezeptives Feld“ — nicht im physischen Raum, sondern in dieser abstrakten Karte von Objekteigenschaften. Objekte, die in die bevorzugte Region einer Zelle fielen, teilten oft sowohl wahrnehmungsbezogene Merkmale (zum Beispiel runde Formen oder grünliche Farben) als auch höherstufige Bedeutungen (etwa Lebewesen oder Werkzeuge), wodurch diese Neuronen sparsam, aber selektiv feuerten.
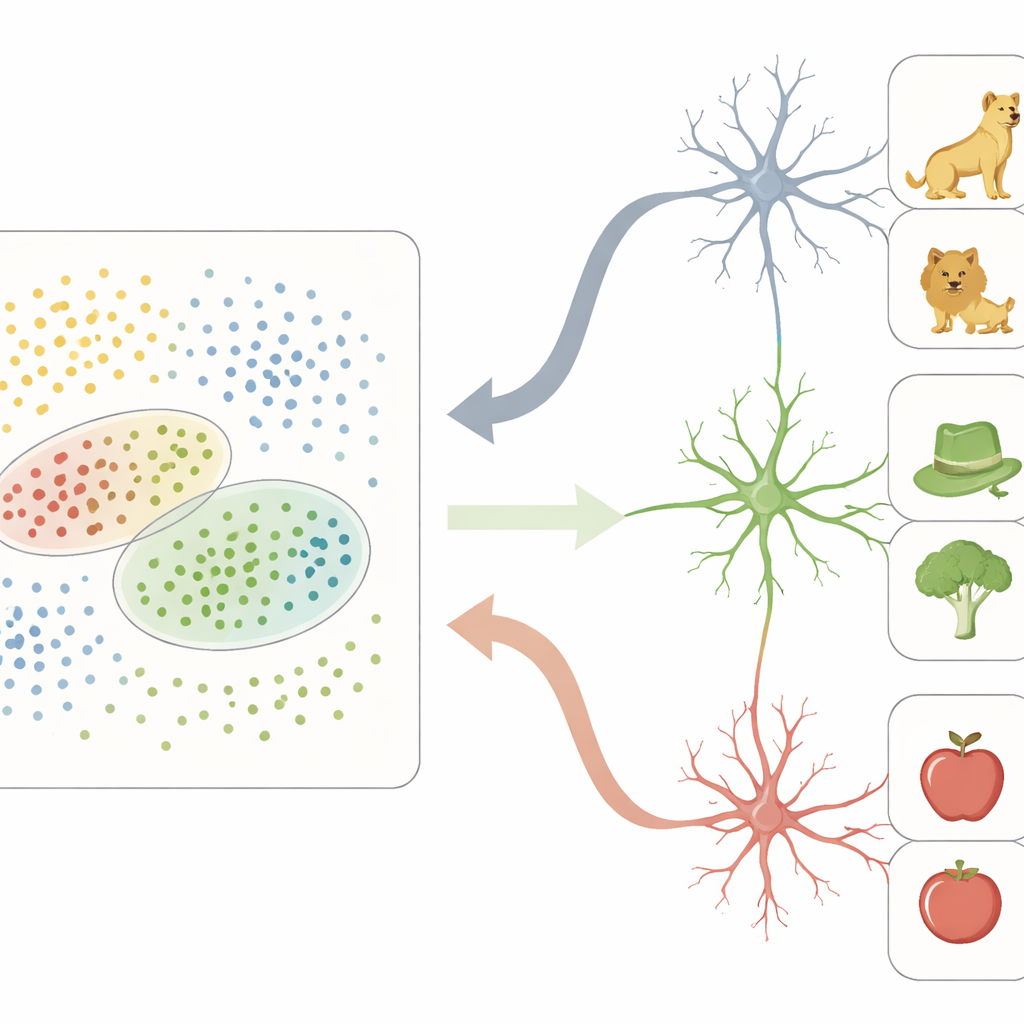
Verknüpfung von Sehen und Erinnern
Um zu zeigen, dass dies kein bloßer mathematischer Trick ist, untersuchte das Team, wie diese Hirnareale in Echtzeit interagieren. Sie fanden, dass VTC-Stellen mit starken Achsen-Signalen besonders synchron mit kategorieempfindlichen Stellen im MTL waren, insbesondere in bestimmten rhythmischen Hirnwellen. Die Information floss tendenziell in niedrigeren Frequenzen vom VTC zum MTL, die mit vorwärtsgerichteter Verarbeitung assoziiert sind, während Rückkopplungen vom MTL zum VTC auf etwas höheren Frequenzen ritten. Entscheidend war: Wenn ein MTL-Neuron auf eine spezifische Region des Merkmalsraums abgestimmt war, stimmten seine Spikes mit schnellen Rhythmen im VTC überein, und diese Kopplung war stärker für genau die Bilder, die das Neuron kodierte. Ein zweites Experiment mit einer anderen Bildsammlung bestätigte, dass sowohl die VTC-Merkmalskarte als auch die MTL-Regionstimmung über Stimulussets hinweg stabil waren.
Warum das für alltägliches Sehen und Erinnern wichtig ist
Zusammen stützen diese Ergebnisse eine konkrete rechnerische Erklärung: Das VTC verteilt visuelle Objekte entlang sinnvoller Merkmalsachsen und bildet eine reiche, kontinuierliche Landschaft, und der MTL setzt kleine, selektive „Zeiger“ auf Regionen dieser Landschaft. Diese Umwandlung verwandelt einen detailreichen, verteilten Bild-Code in einen sparsamen Konzept-Code, der sich leichter speichern, abrufen und mit anderen Erinnerungen verbinden lässt. Für Nicht-Spezialisten heißt das: Einen Hund in einer regnerischen Nacht zu erkennen ist kein einfacher Nachschlag, sondern das Ergebnis eines geschichteten, kooperativen Prozesses, bei dem ein Teil des Gehirns eine strukturierte Karte von Erscheinungsbildern baut und ein anderer Teil lernt, Regionen dieser Karte als eigenständige, beständige Ideen zu markieren und auszulesen.
Zitation: Cao, R., Zhang, J., Zheng, J. et al. Computational single-neuron mechanisms of visual object coding in the human temporal lobe. Nat Commun 17, 2234 (2026). https://doi.org/10.1038/s41467-026-68954-8
Schlüsselwörter: Objekterkennung, ventraler temporaler Kortex, medialer Temporallappen, neuronale Kodierung, visuelles Gedächtnis