Clear Sky Science · de
DNA-Diamant formuliert ein zerlegbares Modell einer Zusammensetzungs-Buchstabenkonstellation für DNA-Datenspeicherung
Warum zukünftige Daten in DNA leben könnten
Unsere Telefone, Unternehmen und wissenschaftlichen Instrumente erzeugen Daten deutlich schneller, als Festplatten und Magnetbänder mithalten können. DNA — dasselbe Molekül, das genetische Informationen in Lebewesen trägt — kann auch zur Speicherung digitaler Dateien in einer außerordentlich kompakten, langlebigen Form verwendet werden. Diese Arbeit stellt eine neue Methode vor, noch mehr Information in synthetische DNA-Stränge zu packen, ohne dabei die Praxis- oder Lesbarkeit zu gefährden, und macht DNA-Speicherung potenziell kostengünstiger und besser skalierbar.
Von vier DNA-Buchstaben zu reichhaltigeren Mischungen
Traditionelle DNA-Speicherung nutzt die vier natürlichen DNA-Basen — A, T, G und C — um digitale Bits darzustellen, ähnlich wie Nullen und Einsen auf einer Festplatte. In diesem Schema kann jede Position in einem DNA-Strang höchstens zwei Bits tragen, weil sie auf eine von vier Optionen beschränkt ist. Die Autoren bauen auf einer aufkommenden Idee auf: Statt an jeder Position eine einzelne Base zu platzieren, erzeugen sie kontrollierte Mischungen von Basen, sogenannte zusammengesetzte Buchstaben. Zum Beispiel kann eine Position aus einer 50:50-Mischung von A und T bestehen oder aus einer 25:25:25:25-Mischung aller vier Basen. Wenn viele Kopien jedes Strangs synthetisiert werden, offenbaren Sequenzierungen diese Basisanteile und damit ein digitales Symbol, das mehr als zwei Bits repräsentieren kann.
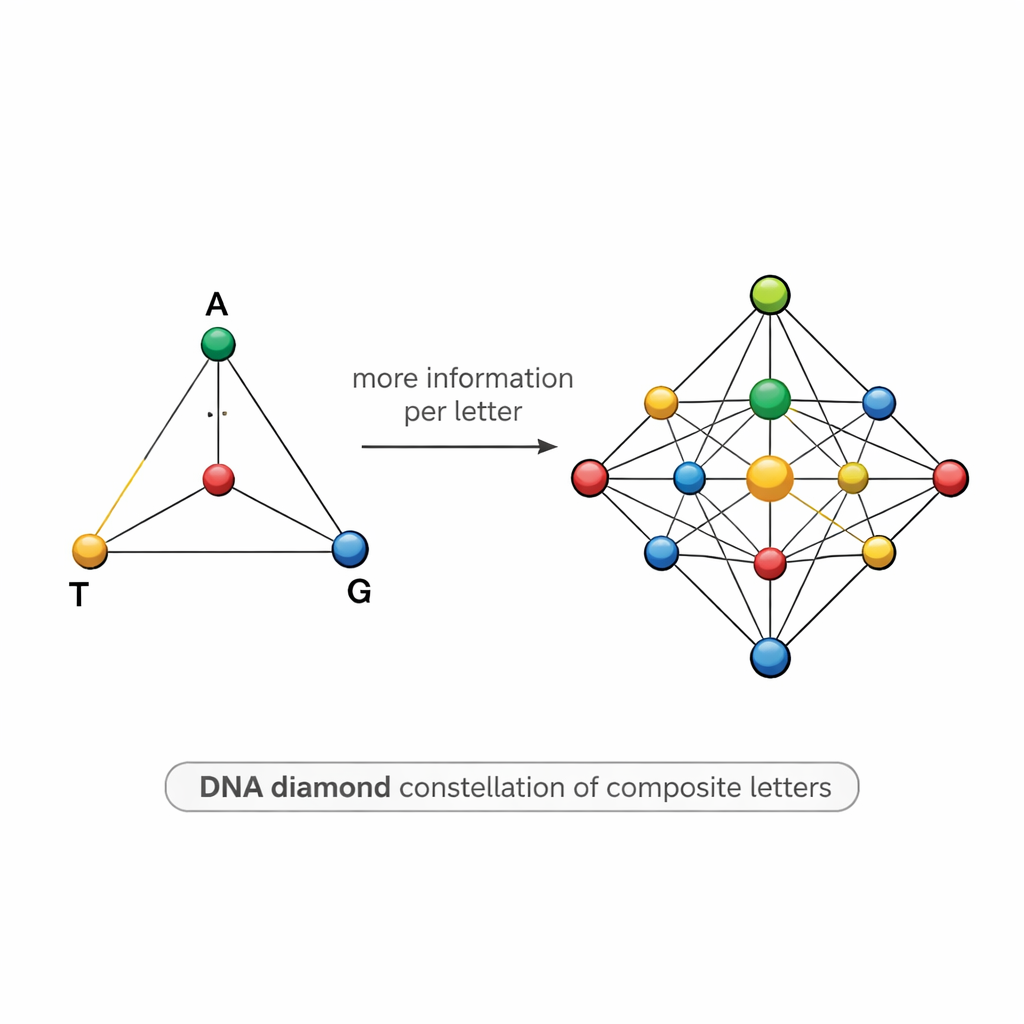
Eine diamantförmige Karte von DNA-Symbolen
Die Gestaltung solcher Mischungen ist knifflig. Wenn zwei Symbole sich zu ähnlich sind — etwa eines mit 50 % A und 50 % T und ein anderes mit 55 % A und 45 % T — kann Rausch in der Sequenzierung sie verschmieren, was zu Fehlern führt und die Wissenschaftler zwingt, deutlich mehr Kopien zu sequenzieren, als ihnen lieb ist. Um dem zu begegnen, schlägt das Team ein strukturiertes „DNA-Diamant“-Modell vor: eine Menge von 15 zusammengesetzten Buchstaben, angeordnet wie Punkte auf einem Tetraeder, dessen Ecken A, T, G und C sind. Die Menge umfasst reine Basen an den Ecken, gleiche Mischungen aus zwei Basen entlang der Kanten, Mischungen aus drei Basen auf jeder Fläche und eine vollkommen gleichmäßige Mischung aller vier Basen im Zentrum. Diese sorgfältig gewählte Konstellation erhöht die theoretische Information pro Position auf etwa 3,9 Bits, während die Symbole ausreichend unterscheidbar bleiben, um in der Praxis getrennt zu werden.
Intelligenteres Decoding mit Entropie und Indizierung
Daten aus DNA zurückzulesen bedeutet, aus verrauschten Messungen der Basenhäufigkeiten zu schließen, welcher zusammengesetzte Buchstabe an jeder Position gemeint war. Die Autoren übernehmen eine Strategie aus der Telekommunikation, das Set-Partitioning. Zuerst betrachten sie, wie «gemischt» eine Position erscheint, mithilfe einer Größe namens Entropie, die für reine Basen niedrig und für komplexe Mischungen höher ist. Das weist jede Position schnell einer von vier Gruppen zu: reine Basen, Zwei-Basen-Mischungen, Drei-Basen-Mischungen oder die Vier-Basen-Mischung. Innerhalb der gewählten Gruppe wählt dann eine genauere Likelihood-Berechnung den wahrscheinlichsten Buchstaben. Dieser zweistufige Ansatz verringert Verwechslungen zwischen Symbolen und reduziert die Rechenzeit im Vergleich zu früheren Methoden. Um zusätzlich zu verhindern, dass Stränge miteinander verwechselt werden, trägt jedes DNA-Stück fehlergeschützte Indexsequenzen an beiden Enden, und Reads falscher Länge — oft verursacht durch Insertionen oder Deletionen — werden vor dem Decoding herausgefiltert.
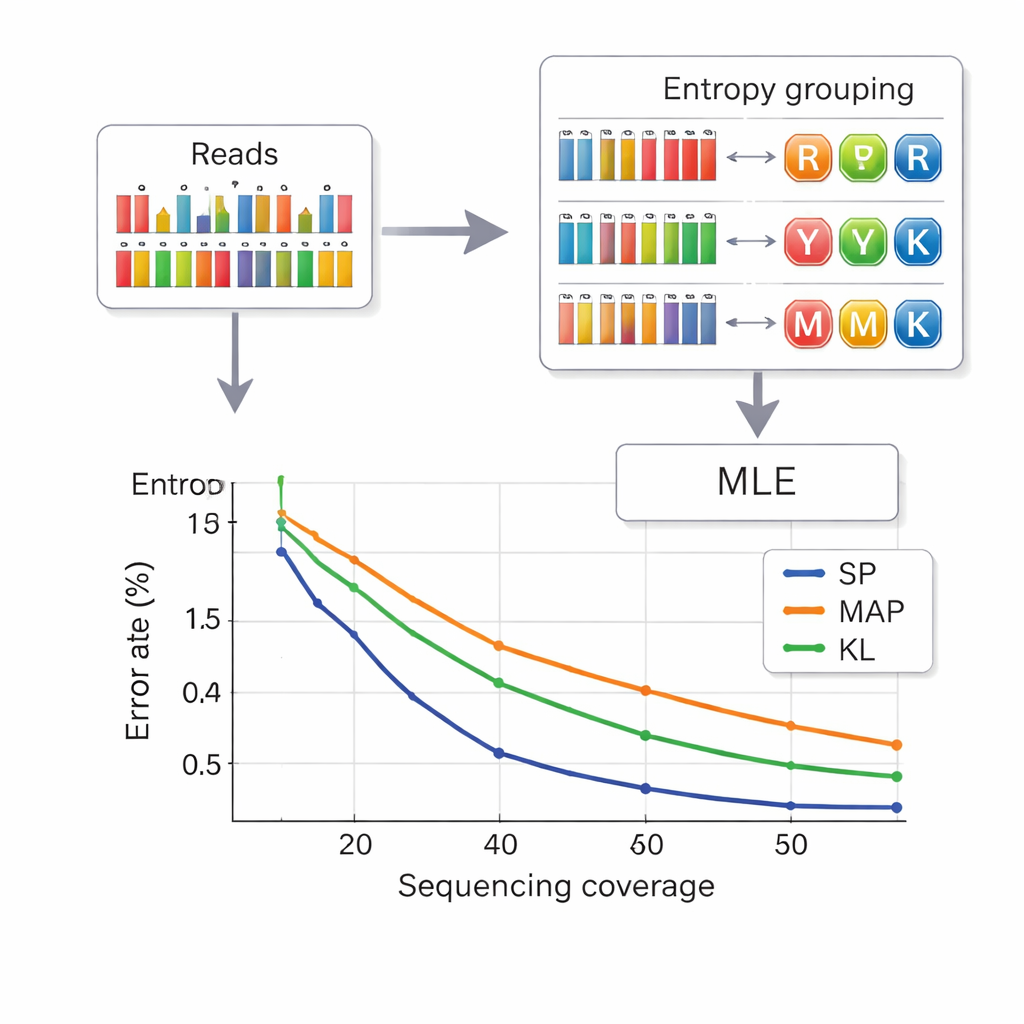
Mehr Daten mit weniger Reads packen
Die Forschenden testeten ihr System sowohl in kleinen als auch in großen DNA-Pools unter Verwendung kommerzieller Syntheseplattformen. Mit einem achtstufigen zusammengesetzten Alphabet erreichten sie eine Nutzlastdichte von 2,5 Bits pro DNA-Position und konnten Dateien bei durchschnittlich 14 Sequenzier-Reads pro Strang fehlerfrei wiederherstellen — bessere Dichte als frühere Sechs-Buchstaben-Schemata und zugleich mit weniger benötigten Reads. Mit dem vollständigen 15-Buchstaben-DNA-Diamant-Alphabet erzielten sie 3,125 Bits pro Position für die Hauptdaten und konnten dennoch bei 33-facher Abdeckung alles fehlerfrei rekonstruieren. Simulationen und Experimente zeigten außerdem, dass ihre auf Entropie basierende Methode nahezu so gut performt wie der genaueste, aber langsamere Decodierungsansatz und deutlich besser als ältere Techniken, insbesondere bei geringerer Sequenziertiefe.
Was das für zukünftigen Speicher bedeutet
Für eine nicht fachkundige Leserschaft ist die Kernbotschaft: Die Autoren haben einen Weg gefunden, DNA «neue Tricks» beizubringen, ohne neue Chemie zu erfinden: Durch geschicktes Mischen der vorhandenen vier Basen und intelligenteres Decoding können sie mehr Bits pro Molekül speichern und gleichzeitig die Kosten kontrollieren. Ihr diamantförmiges Alphabet, kombiniert mit robuster Indizierung und Fehlerkorrektur, zeigt, dass hochkapazitiver DNA-Datenspeicher mit vergleichsweise moderatem Sequenzieraufwand möglich ist. Wenn DNA-Synthese und -Sequenzierung weiter billiger werden, könnten solche Designs helfen, DNA von einer Labor-Neugier zu einem realistischen Medium zur Archivierung der digitalen Erinnerungen der Welt zu machen.
Zitation: Ge, Q., Ren, M., Qi, T. et al. DNA diamond formulates a decomposable composite letter constellation model for DNA data storage. Nat Commun 17, 1704 (2026). https://doi.org/10.1038/s41467-026-68861-y
Schlüsselwörter: DNA-Datenspeicherung, Zusammengesetzte Buchstaben, Informationsdichte, Fehlerkorrektur, digitale Archivierung