Clear Sky Science · de
Bewertung von Single‑Cell‑ATAC‑seq‑Atlasing‑Technologien mithilfe von Sequence‑to‑Function‑Modellen
Das Bedienungsbuch der Zelle lesen
Jede Zelle in Ihrem Körper liest dieselbe DNA, doch Nervenzellen, Muskelzellen und Immunzellen verhalten sich sehr unterschiedlich. Dieses Paper geht ein zentrales Rätsel dieser Vielfalt an: wie kurze DNA‑Abschnitte, sogenannte Enhancer, als Schalter fungieren und Gene in bestimmten Zelltypen an‑ oder ausschalten. Die Autorinnen und Autoren zeigen, dass neue, kostengünstigere Labortechniken die massiven Datensätze liefern können, die nötig sind, um moderne Tiefenlernmodelle zu trainieren, die DNA‑Sequenzen lesen und vorhersagen, welche Enhancer in welchen Zellen aktiv sind — ein Schritt näher an der Entschlüsselung der regulatorischen "Grammatik" des Genoms.
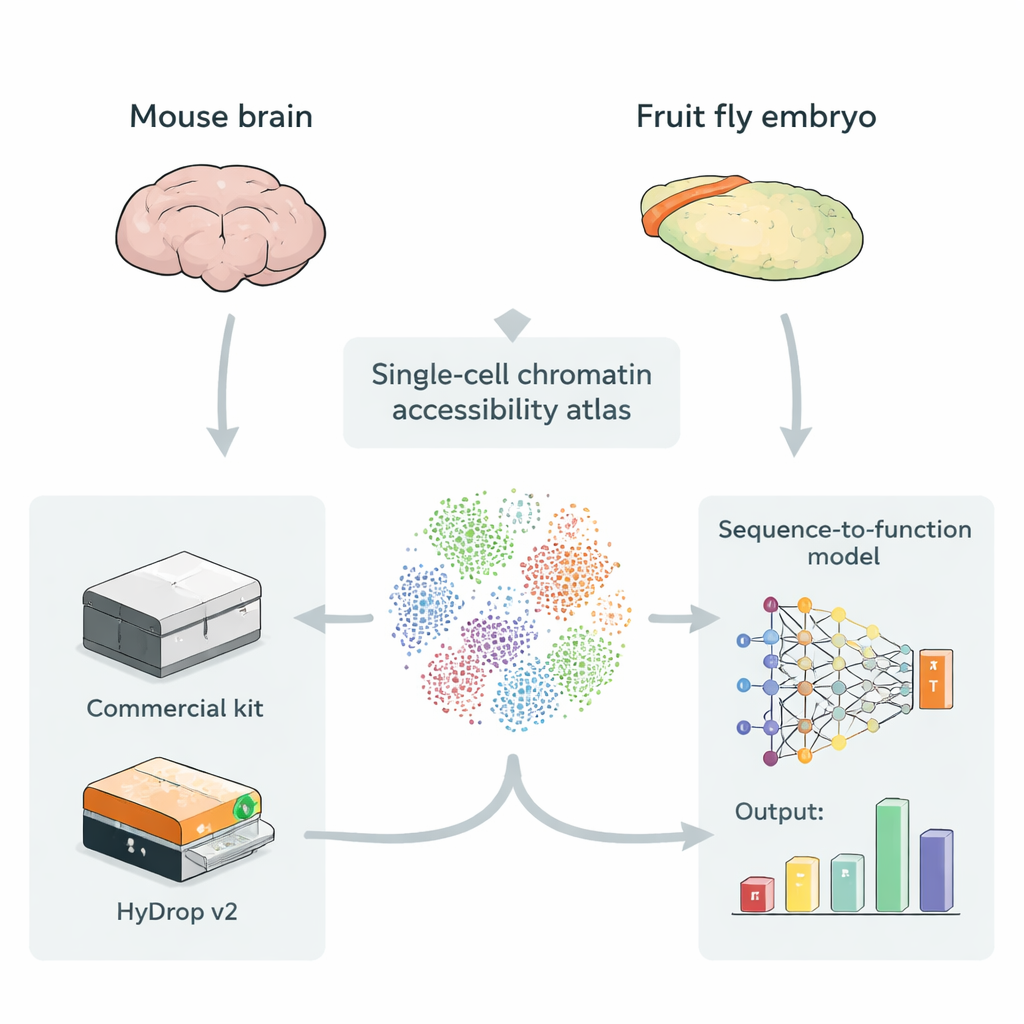
Karten offener DNA in Einzelzellen erstellen
Enhancer liegen meist in DNA‑Bereichen, die offener und zugänglicher sind, sodass regulatorische Proteine dort leichter binden können. Eine Methode namens Single‑Cell ATAC‑seq misst, welche Genomabschnitte in tausenden bis hunderttausenden einzelner Zellen offen sind und erstellt so einen „Atlas“ zugänglicher DNA über viele Zelltypen hinweg. Solche Atlanten sind ideale Trainingsdaten für Tiefenlernmodelle, die rohe DNA‑Sequenz als Eingabe nehmen und lernen, wie stark jede kleine Region in jedem Zelltyp als Enhancer wirkt. Bisher basierten die meisten dieser Atlanten jedoch auf teuren kommerziellen Instrumenten, sodass die Frage offen blieb, ob kostengünstige Open‑Source‑Methoden Trainingsdaten von vergleichbarem Wert liefern können.
Eine Open‑Source‑Alternative zu kommerziellen Plattformen
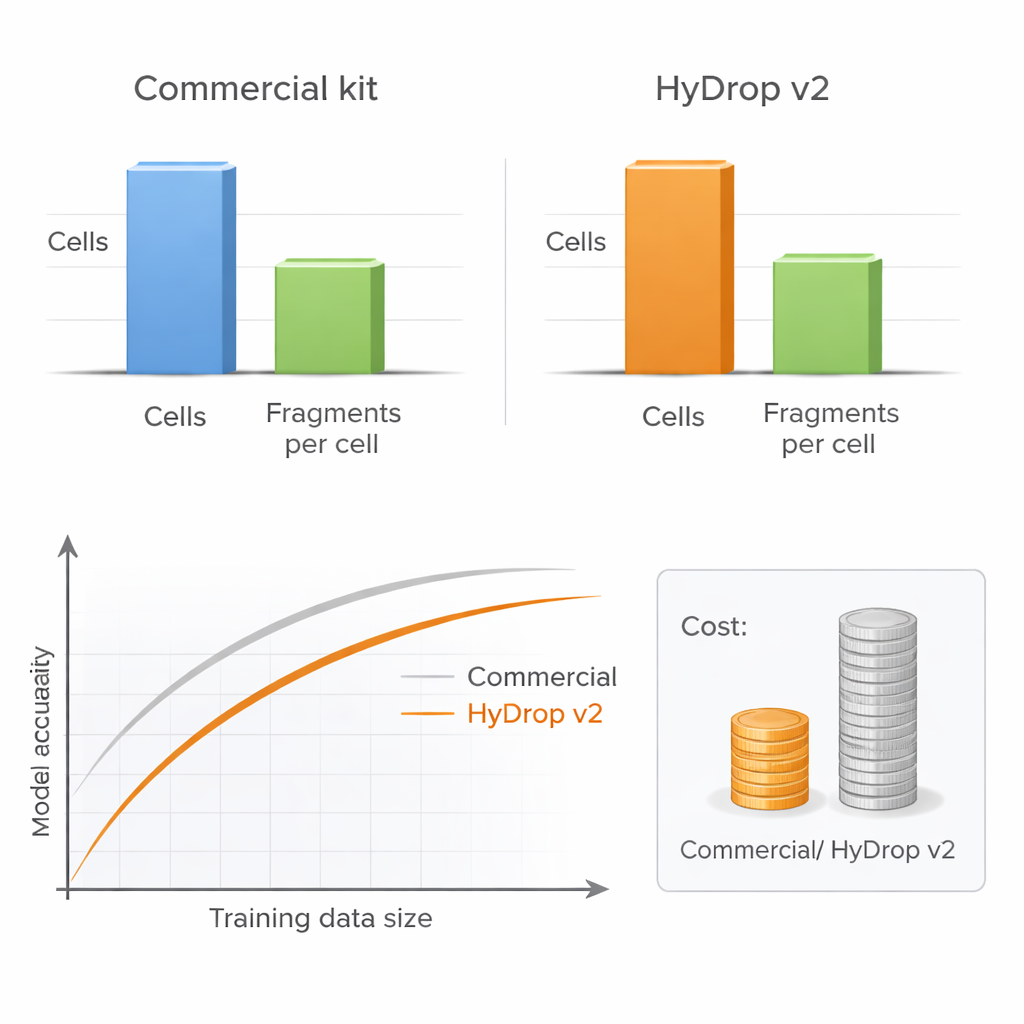
Die Autorinnen und Autoren stellen HyDrop v2 vor, eine verbesserte Tropfen‑basierte Methode für Single‑Cell ATAC‑seq, die kundenspezifische Hydrogel‑Beads zur Barcodekennzeichnung einzelner Zellen verwendet. Sie vergleichen HyDrop v2 mit einem weit verbreiteten kommerziellen Kit, indem sie große Atlanten aus zwei sehr unterschiedlichen Systemen erstellen: dem motorischen Cortex erwachsener Mäuse und Embryonen der Fruchtfliege im Spätstadium. HyDrop v2 liefert vergleichbare Datenqualität — es werden dieselben großen Zelltypen und sehr ähnliche Mengen zugänglicher DNA‑Regionen gefunden — und kostet pro Mausgehirnprobe etwa vierzehnmal weniger. Wichtig ist auch, dass HyDrop‑v2‑Daten sich nahtlos mit kommerziellen Daten integrieren lassen, so dass Forschende Plattformen beim Aufbau sehr großer Atlanten mischen können.
Tiefenlernmodelle trainieren, um Enhancer‑Logik zu lesen
Um zu prüfen, ob günstigere Daten für fortgeschrittene Modelle ausreichen, trainiert das Team Sequence‑to‑Function‑Tiefenlernmodelle entweder auf kommerziellen oder auf HyDrop‑v2‑Atlanten. Diese Modelle lernen direkt aus der DNA‑Sequenz, vorherzusagen, wie zugänglich jede Region in jedem Zelltyp ist, und können kurze Sequenzmuster hervorheben, die vermutlich Bindungsstellen für bestimmte regulatorische Proteine darstellen. Im Mauscortex erreichen Modelle, die auf HyDrop‑v2‑Daten trainiert wurden, dieselbe Gesamtgenauigkeit wie Modelle auf kommerziellen Daten und können bekannte Enhancer‑"Schalter" wiederfinden, die zuvor in lebenden Tieren validiert wurden. In der Fliegenembryo‑Analyse ermöglichen beide Plattformen Modelle, die in 2.000 Basenpaare große Regionen hereinzoomen und die etwa 500 Basenpaare langen Kernsegmente ausmachen, die tatsächlich die gewebespezifische Enhancer‑Aktivität antreiben — etwa Regionen, die die Expression von Neuroblast‑ oder Muskelgenen steuern.
Mehr Zellen können größere Tiefe übertreffen
Eine wichtige praktische Frage für jedes Labor ist, ob jede Zelle sehr tief sequenziert werden sollte oder ob man lieber mehr Zellen mit geringerer Tiefe profiliert. Durch systematisches Variieren der Zellzahlen und der Anzahl der DNA‑Fragmente pro Zelle zeigen die Autorinnen und Autoren, dass die Modellleistung kaum leidet, wenn die Sequenzierungstiefe auf ein moderates Niveau reduziert wird, vorausgesetzt, es sind genügend Zellen enthalten. Im Gegensatz dazu schadet eine Verringerung der Zellzahl klar der Modellgenauigkeit, besonders wenn die Leistung über viele Zelltypen gleichzeitig bewertet wird. Da HyDrop v2 pro Zelle deutlich billiger ist, können Forschende problemlos Zehntausende zusätzlicher Zellen hinzufügen und so die Leistung kommerzieller Modelle zu einem Bruchteil der Kosten erreichen oder übertreffen.
Proteinfussabdrücke auf DNA sehen
Die Studie untersucht außerdem, ob verschiedene Laborplattformen subtile Verzerrungen darin einführen, wie das ATAC‑seq‑Enzym DNA schneidet, was Modelle irreführen könnte, die versuchen, Proteinbindungsstellen im Genom abzuleiten. Mit einem separaten neuronalen Netz, das für Enzympräferenzen korrigiert, zeigen die Autorinnen und Autoren, dass HyDrop v2 und kommerzielle Kits nahezu identische Muster enzymatischer Aktivität in Maus‑ und Fliegenzellen erzeugen. Nach der Korrektur zeigen beide Datensätze fein‑skalige „Fußabdrücke“, in denen regulatorische Proteine und Nukleosome die DNA vor dem Schnitt zu schützen scheinen, und diese Fußabdrücke stimmen mit den von den Sequence‑to‑Function‑Modellen hervorgehobenen Sequenzmustern überein. Diese Übereinstimmung legt nahe, dass Open‑Source‑ und kommerzielle Plattformen gleichermaßen für detaillierte Studien zur Wechselwirkung von Proteinen mit DNA geeignet sind.
Warum das wichtig für die Entschlüsselung des Genoms ist
Für Nicht‑Spezialisten lautet die Kernbotschaft: Wir können jetzt sehr große, erschwingliche Karten erstellen, wie DNA in Einzelzellen genutzt wird, und starke Tiefenlernmodelle auf diesen Karten trainieren, ohne ausschließlich auf teure proprietäre Hardware angewiesen zu sein. HyDrop v2 liefert Daten, die Enhancer‑Vorhersage, Interpretation von Sequenzmustern und Protein‑Bindungsfußabdrücke in gleicher Qualität wie führende kommerzielle Methoden unterstützen, sofern genügend Zellen profiliert werden. Das eröffnet die Möglichkeit, organismenweite Atlanten regulatorischer Elemente in Gesundheit und Krankheit zu erstellen, beschleunigt Bemühungen, die regulatorischen Anweisungen des Genoms zu lesen, und erleichtert das Design neuer, präzise zielgerichteter genetischer Schalter für Forschung und künftige Therapien.
Zitation: Dickmänken, H., Wojno, M., Mahieu, L. et al. Evaluating single-cell ATAC-seq atlasing technologies using sequence-to-function modeling. Nat Commun 17, 1951 (2026). https://doi.org/10.1038/s41467-026-68742-4
Schlüsselwörter: Single‑Cell‑ATAC‑seq, Enhancer, Tiefenlernmodelle, Genregulation, Open‑Source‑Genomik