Clear Sky Science · de
BiG-SCAPE 2.0 und BiG-SLiCE 2.0: skalierbare, präzise und interaktive Sequenz-Clustering von Stoffwechsel-Genclustern
Verborgene chemische Schätze in mikrobieller DNA
Viele der Medikamente und Pflanzenschutzmittel, auf die wir angewiesen sind, stammen von kleinen Molekülen, die von Mikroben produziert werden. Diese Organismen verbergen die Baupläne für solche Moleküle in DNA-Abschnitten, die man Gencluster nennt. Während die DNA-Sequenzierung rasch voranschreitet, stehen Forschende vor einer Datenflut und kennen dennoch nur einen kleinen Bruchteil dessen, was Mikroben herstellen können. Dieser Artikel stellt BiG-SCAPE 2.0 und BiG-SLiCE 2.0 vor, zwei verbesserte Softwarewerkzeuge, die Wissenschaftlern helfen, enorme genomische Archive zu durchforsten, diese verborgenen „molekularen Fabriken“ zu kartieren, zu vergleichen und zu ordnen und damit die Entdeckung der nächsten Generation von Antibiotika und Agrarchemikalien zu beschleunigen.
Warum Gencluster für Gesundheit und Landwirtschaft wichtig sind
Mikroben nutzen spezialisierte kleine Moleküle, um zu konkurrieren, zu kommunizieren und sich an ihre Umgebung anzupassen. Die DNA-Baupläne zur Herstellung oder zum Abbau dieser Moleküle sind häufig in metabolischen Genclustern gebündelt. Dazu gehören biosynthetische Gencluster, die komplexe Naturstoffe erzeugen, und katabolische Gencluster, die Mikroben erlauben, bestimmte Verbindungen oder Wurzelexsudate zu verwerten. Da Gene innerhalb eines Clusters gemeinsam wirken, ist das Auffinden eines solchen Abschnitts im Genom vergleichbar mit dem Entdecken einer selbstständigen „Produktionslinie“, die Hinweise auf Struktur und Funktion eines Moleküls geben kann. Genome-Mining-Werkzeuge erkennen solche Fabriken bereits in Bakterien und Pilzen, aber die eigentliche Herausforderung besteht darin, hunderte Tausende von Clustern zu vergleichen, um ihre Verwandtschaft und das chemische Diversitätspotenzial zu verstehen.
Zwei Motoren zum Sortieren molekularer Fabriken
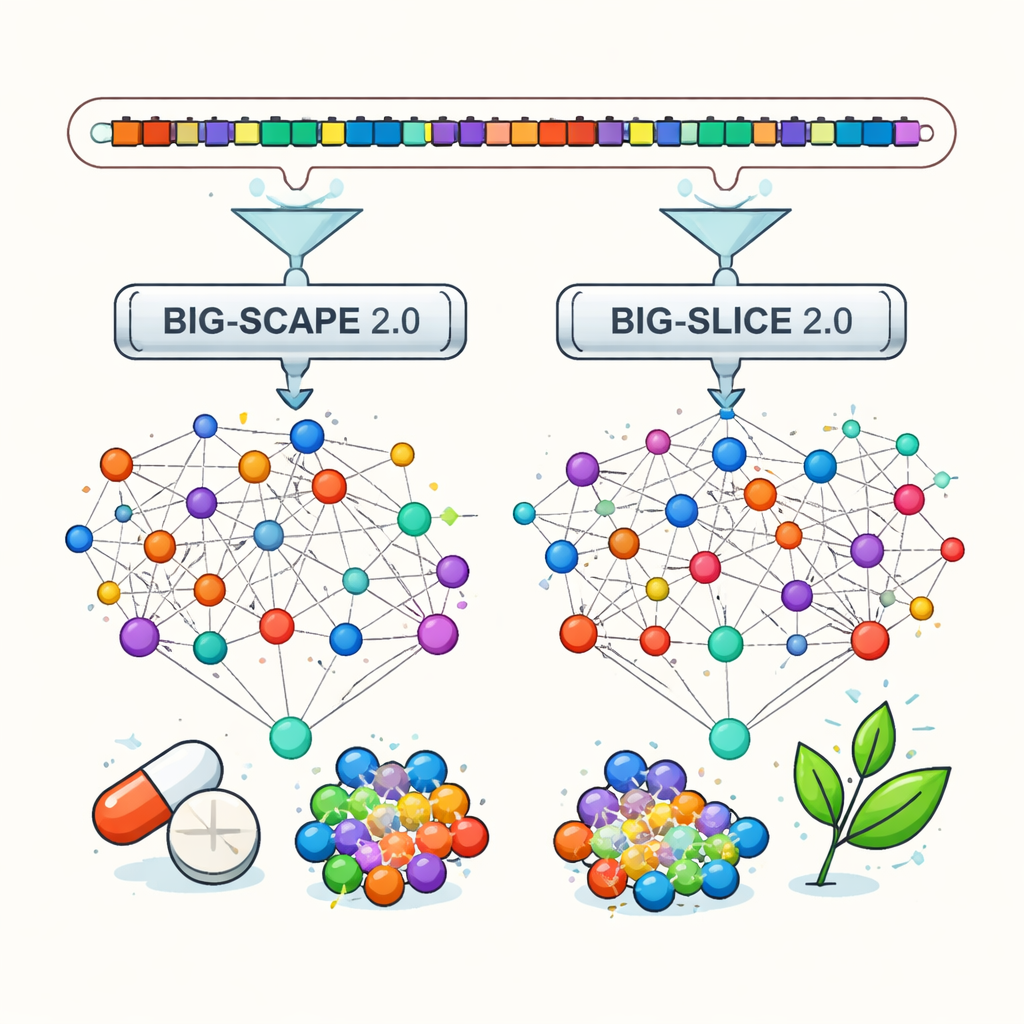
BiG-SCAPE und BiG-SLiCE wurden ursprünglich entwickelt, um Gencluster mit ähnlichen Kernmerkmalen in „Gencluster-Familien“ zu gruppieren. Von jeder Familie wird erwartet, dass sie dieselben oder nahe verwandte Moleküle produziert. BiG-SCAPE erstellt detaillierte Ähnlichkeitsnetzwerke zwischen Clustern, während BiG-SLiCE auf Geschwindigkeit ausgerichtet ist und Millionen von Clustern verarbeiten kann, indem es diese in einfache numerische Fingerprints umwandelt und diese dann clustert. Zusammen bilden sie die Grundlage eines wachsenden Ökosystems aus Genome-Mining-Pipelines, Datenbanken und interaktiven Betrachtern, die Forschenden helfen, die mikrobiellen chemischen Landschaften in planetarem Maßstab zu navigieren.
Was neu ist in BiG-SCAPE 2.0
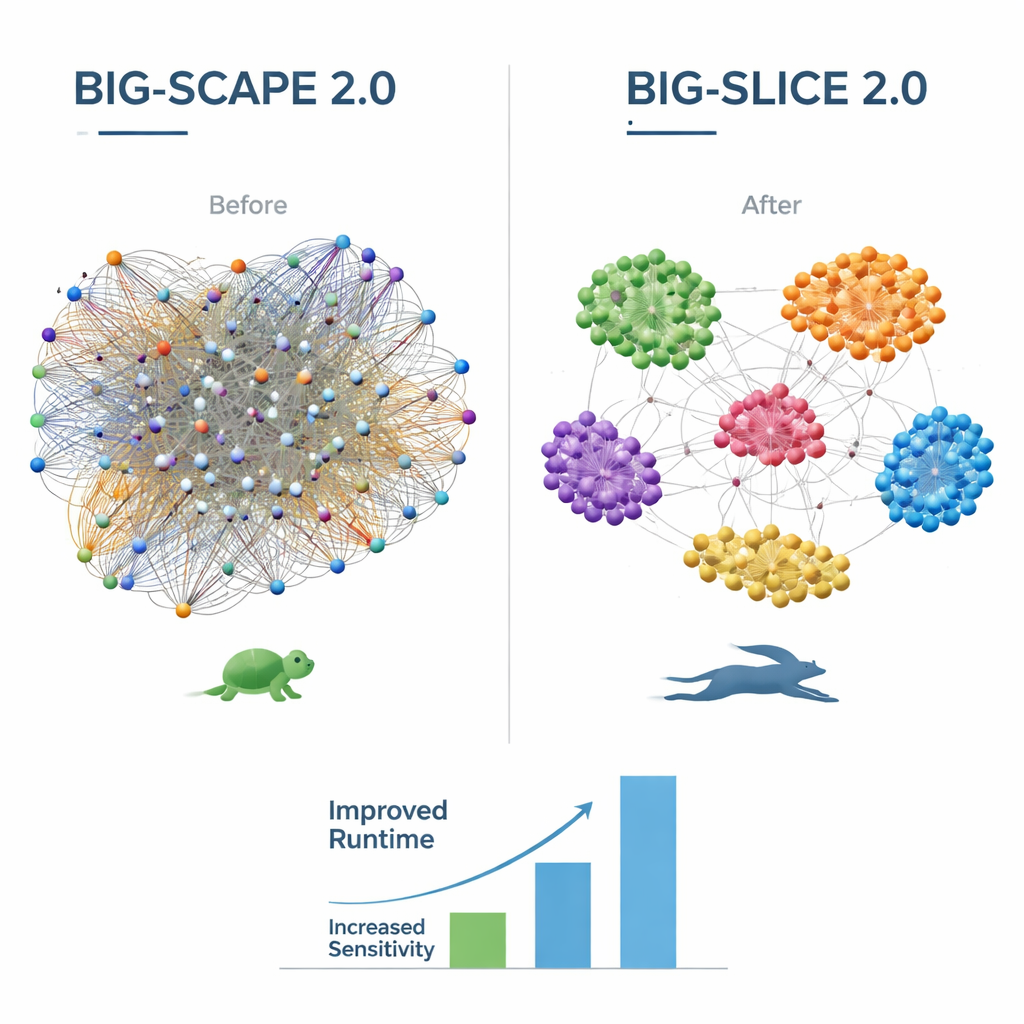
Version 2.0 von BiG-SCAPE bringt eine Reihe von Verbesserungen für Biologie und Informatik. Sie unterstützt nun das verfeinerte „Region“-Konzept des weit verbreiteten Tools antiSMASH, das überlappende oder hybride Gencluster in kleinere, sinnvollere Bausteine namens Protocluster unterteilt. Neue Alignierungsmodi und Strategien erlauben es BiG-SCAPE 2.0, sich auf die tatsächlich wichtigen Kern-Gene innerhalb jedes Clusters zu fokussieren und besser mit umgestellten Genen und unscharfen Clustergrenzen umzugehen. Im Inneren wurde der Code vollständig neu geschrieben, um Geschwindigkeit und Wartbarkeit zu erhöhen, mit einer gemeinsam genutzten SQLite-Datenbank und einer modernen Python-Bibliothek für Profil-Suchen. Dadurch läuft BiG-SCAPE 2.0 bis zu achtmal schneller als sein Vorgänger, nutzt etwa die Hälfte des Arbeitsspeichers und bietet nun mehrere vorgefertigte Workflows zum Clustern, Abfragen, Deduplizieren und Benchmarken von Genclustern über eine verbesserte interaktive Weboberfläche.
Wie BiG-SLiCE 2.0 mit der Datenflut Schritt hält
BiG-SLiCE 2.0 konzentriert sich darauf, sehr große Analysen genauer zu machen, ohne die charakteristische Geschwindigkeit zu verlieren. Frühere Versionen behandelten alle Genclustertypen gleich, was unbeabsichtigt einige Familien bevorzugte. Durch den Wechsel zu einer cosine-ähnlichen Distanzmessung und die Aktualisierung seiner Bibliothek biosynthetischer Proteinsignaturen auf den neuesten Stand gruppiert BiG-SLiCE 2.0 nun sehr unterschiedliche Clustertypen gleichmäßiger. Code-Optimierungen und der Umstieg auf dieselbe schnelle Profil-Suchbibliothek wie BiG-SCAPE bringen zusätzliche Beschleunigungen, und neue Optionen, alle Ergebnisse als einfache Texttabellen zu exportieren, erleichtern die Einbindung von BiG-SLiCE in andere Analyse-Pipelines. Tests an neun Datensätzen manuell kuratierter Genfamilien zeigen, dass die Genauigkeit von BiG-SLiCE 2.0 nun an die von BiG-SCAPE heranreicht, insbesondere für kürzere und schwer fassbare Gencluster.
Aufdeckung eines riesigen, ungenutzten chemischen Universums
Die Autoren nutzten beide Werkzeuge, um 260.630 biosynthetische Regionen aus einer öffentlichen Datenbank mikrobieller Genome zu analysieren. BiG-SCAPE 2.0 und BiG-SLiCE 2.0 lieferten bemerkenswert ähnliche Schätzungen zur Anzahl unterschiedlicher Gencluster-Familien in diesem Datensatz und stützen frühere Befunde, wonach nur etwa 3 % des biosynthetischen Potenzials in bakteriellen Genomen bislang charakterisiert sind. Mit anderen Worten: Die überwältigende Mehrheit der mikrobenproduzierten Chemikalien bleibt unbekannt. Indem sie das präzise Clustern und Visualisieren von Genclustern über Hunderttausende—und künftig Millionen—von Genomen ermöglichen, bieten BiG-SCAPE 2.0 und BiG-SLiCE 2.0 leistungsfähige Linsen zur Erforschung dieses unerforschten chemischen Universums und ebnen den Weg für neue Arzneimittel, sicherere Pflanzenschutzmittel und tiefere Einblicke darin, wie Mikroben Ökosysteme und unsere Gesundheit beeinflussen.
Zitation: Draisma, A., Loureiro, C., Louwen, N.L.L. et al. BiG-SCAPE 2.0 and BiG-SLiCE 2.0: scalable, accurate and interactive sequence clustering of metabolic gene clusters. Nat Commun 17, 2000 (2026). https://doi.org/10.1038/s41467-026-68733-5
Schlüsselwörter: biosynthetische Gencluster, Entdeckung natürlicher Produkte, Genome-Mining, mikrobielle Metaboliten, computationales Clustering