Clear Sky Science · de
Fortschritte und Herausforderungen bei der Datenspeicherung in nicht-kanonischen Nukleinsäuren
Warum es wichtig ist, Daten in Molekülen zu speichern
Jedes Foto, jede Nachricht und jeder Film muss irgendwo gespeichert werden, und derzeit liegen die meisten dieser Daten in riesigen Lagerhallen voller Festplatten, die viel Strom verbrauchen und innerhalb von Jahrzehnten verschleißen. Dieser Artikel untersucht einen sehr anderen Ansatz: speziell konstruierte genetische Moleküle als winzige Datenträger zu verwenden. Indem man die bekannten Bausteine von DNA und RNA verändert, wollen Wissenschaftler eine Informationsspeicherung schaffen, die dichter, belastbarer und sicherer ist als jeder Siliziumchip oder magnetische Datenträger.
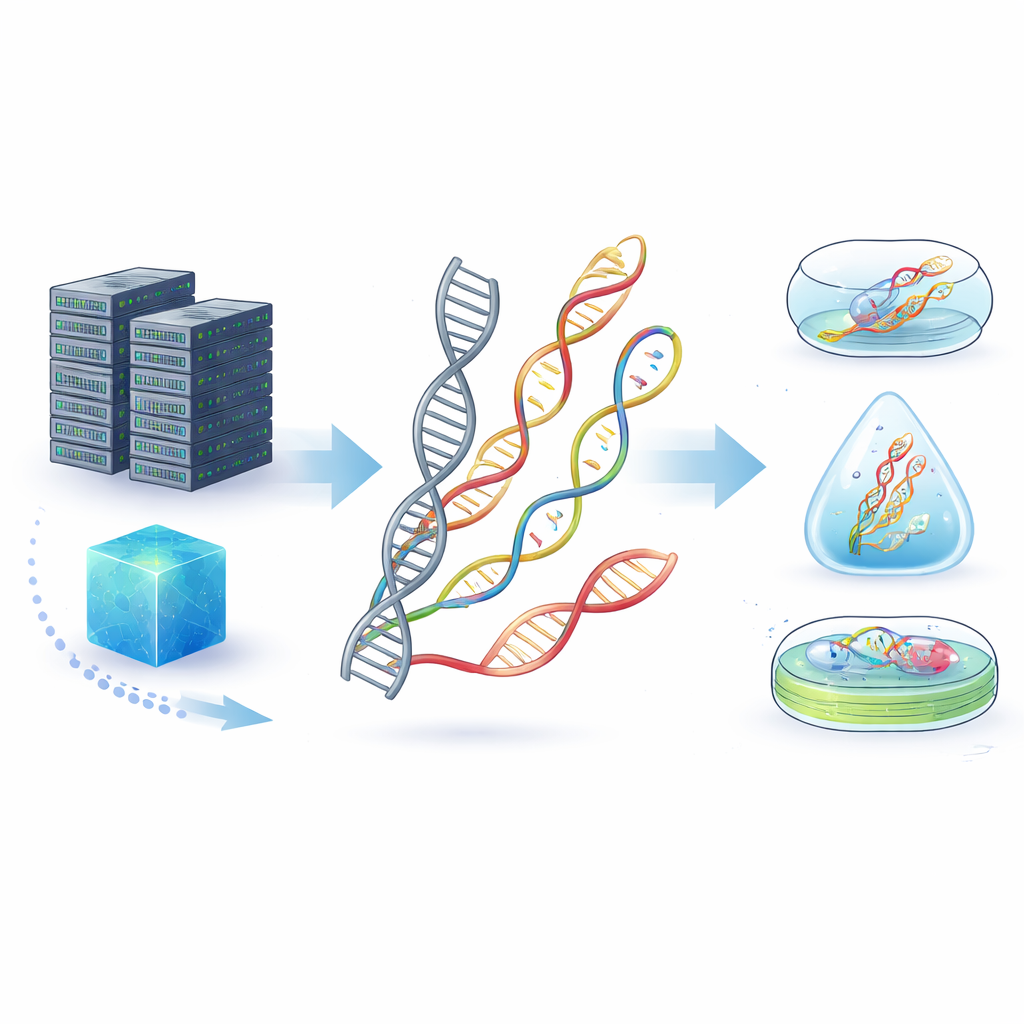
Von empfindlicher DNA zu robusten neuen Molekülen
Natürliche DNA ist bereits ein beeindruckendes Speichermedium: Sie packt enorme Informationsmengen auf kleinem Raum und kann in Fossilien zehntausende Jahre überdauern. Unter Alltagsbedingungen – Hitze, Feuchtigkeit, Fremdstoffe oder Enzyme, die DNA abbauen – kann sie jedoch schnell degradiert werden. Die Autoren stellen „nicht-kanonische Nukleinsäuren“ (ncNAs) vor: DNA- und RNA-ähnliche Moleküle, deren Basen, Zucker oder Rückgrat chemisch verändert oder sogar gespiegelt wurden, um neue Eigenschaften zu erhalten. Solche Änderungen können die Moleküle weniger anfällig für enzymatischen Abbau machen, sie widerstandsfähiger gegen Säuren oder Laugen machen und ihnen erlauben, in rauen Umgebungen besser zu überdauern als gewöhnliche DNA.
Neue Buchstaben zum genetischen Alphabet hinzufügen
Eine der stärksten Ideen in der Übersichtsarbeit ist die Erweiterung des genetischen Alphabets über die üblichen vier Buchstaben A, T, G und C hinaus. Chemiker haben zusätzliche Basenpaare geschaffen, die zwar in Doppelhelices passen, in der Natur aber nicht vorkommen. Mit 8, 12 oder mehr Buchstaben kann jede Position entlang eines Strangs mehr Bits Information kodieren, wodurch die Speicherkapazität weit über das hinaus anwächst, was Standard-DNA bieten kann. Einige dieser neuen Basen sind so entworfen, dass sie über hydrophobe Wechselwirkungen zusammenhalten statt über die üblichen Wasserstoffbrücken, und zeigen damit, dass sich die Naturregeln fürs Paaren biegen lassen, während die Lesbarkeit erhalten bleibt.
Das molekulare Skelett neu aufbauen
Neben der Veränderung der „Buchstaben“ arbeiten Forscher auch am Zucker und Rückgrat, die einen genetischen Strang zusammenhalten. Das Ersetzen des üblichen Zuckers durch Alternativen wie Threose oder Hexitol oder der Austausch geladener Phosphatverbindungen gegen neutrale oder schwefelhaltige Verbindungen kann das Verhalten des Strangs drastisch verändern. Viele solcher ncNAs zeigen bemerkenswerte Stabilität unter heißen, sauren oder enzymreichen Bedingungen, unter denen natürliche DNA schnell zerfällt. Einige spiegelbildliche Versionen, etwa L-DNA, sind für normale Enzyme und Immunabwehr unsichtbar, was sie vielversprechend für extrem sichere Datenspeicherung und versteckte Botschaften macht – obwohl sie derzeit schwer und teuer herzustellen und auszulesen sind.
Wie Daten geschrieben, aufbewahrt und gelesen werden
Die Umwandlung digitaler Dateien in molekulare Form folgt einem vierstufigen Zyklus: Kodierung, Synthese, Konservierung und Auslesen. Bits werden zuerst in Sequenzen oder Strukturen übersetzt, die dann als ncNA-Stränge mittels chemischer Methoden oder speziell entwickelter Enzyme synthetisiert werden. Diese Stränge können außerhalb von lebenden Zellen gelagert werden – eingekapselt in Glas, Siliziumdioxid oder Polymere – oder innerhalb von Zellen und sogar veränderten Pflanzen, wo natürliche Reparaturmechanismen bei der Erhaltung helfen können. Zum Auslesen der Daten werden vertraute DNA-Sequenzer, fortschrittliche Nanoporen-Geräte, die jede Einheit beim Durchtritt durch ein winziges Loch „fühlen“, oder Mikroskope, die Formen in gefalteten Nanostrukturen erkennen, eingesetzt. Da viele ncNAs noch nicht direkt sequenziert werden können, werden sie häufig vor dem Auslesen zurück in reguläre DNA umgewandelt – ein Schritt, den die aktuelle Forschung zu vereinfachen und zu verbessern sucht.
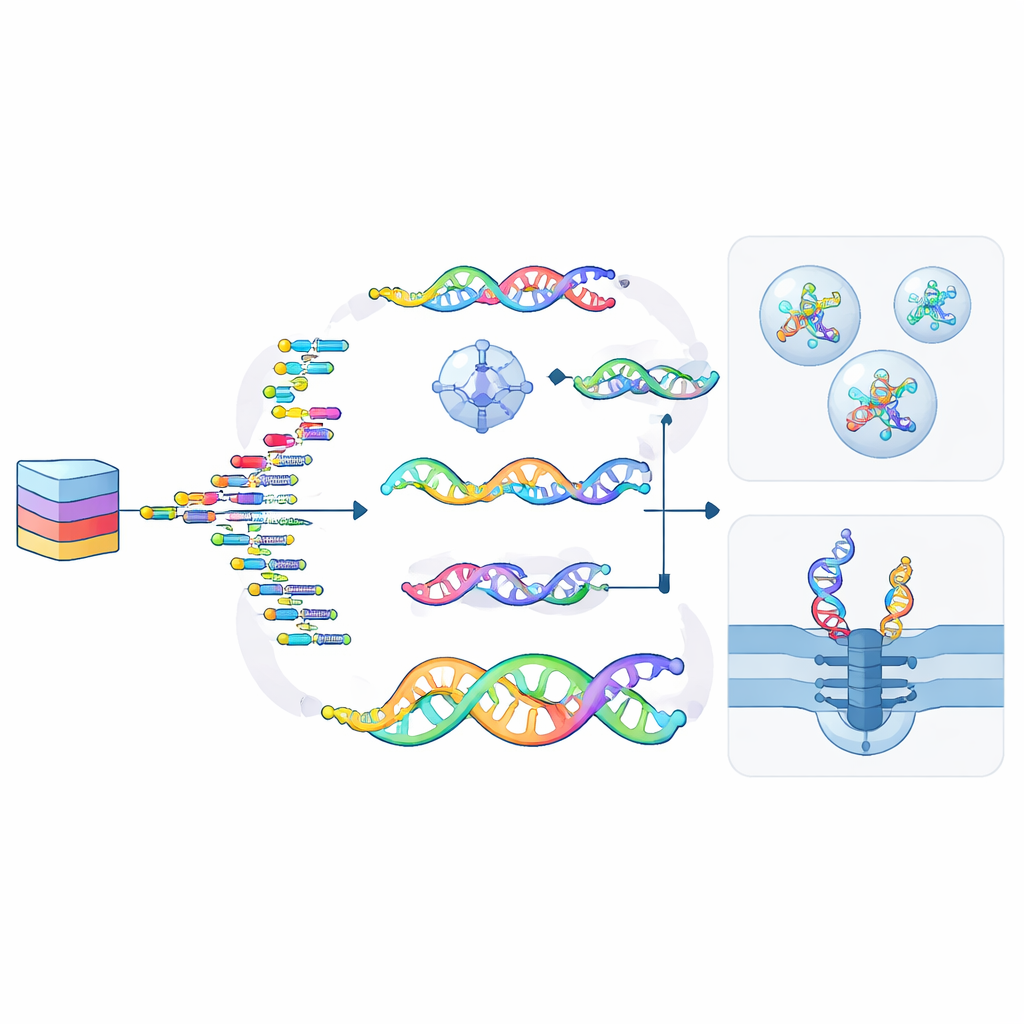
Neue Möglichkeiten: Rechnen, Sicherheit und paralleles Schreiben
Der Artikel betont, dass ncNAs mehr können als nur Daten speichern – sie können diese auch verarbeiten. Auf DNA basierende Logikschaltungen und neuronale Netze existieren bereits, und chemisch unterscheidbare Alphabete erleichtern es, viele Operationen parallel auszuführen, ohne unerwünschte Wechselwirkungen. Bestimmte Modifikationen wirken wie unsichtbare Tinte und erlauben es, Informationen in Strängen oder Strukturen zu verbergen, die nur spezielle Enzyme oder Bedingungen offenlegen. Andere, etwa reversible chemische Additive oder Muster von Methylgruppen, verhalten sich wie bewegliche Lettern auf einer Druckerpresse: Sie können Daten parallel in bestehende Stränge einprägen, sie löschen und neu schreiben, ohne das gesamte Molekül von Grund auf neu herzustellen.
Herausforderungen und welche Bedeutung Erfolg hätte
Trotz des Potenzials betonen die Autoren, dass die Datenspeicherung in nicht-kanonischen Nukleinsäuren noch in einem frühen Stadium ist. Lange, fehlerfreie Stränge herzustellen ist kosten- und technisch aufwendig, und viele der attraktivsten Chemien sind noch nicht mit schnellen, erschwinglichen Lesetechnologien kompatibel. Es gibt zudem wichtige Sicherheits- und Ethikfragen beim Einbringen hochstabiler, teilweise unnatürlicher Moleküle in lebende Systeme. Dennoch skizziert die Übersicht einen Fahrplan, in dem schnellere Synthese, intelligentere Verkapselung und KI-gestützte Nanoporen-Leser ncNA-basierte Speicherung in den kommenden Jahrzehnten praktikabel machen könnten. Wenn das gelingt, könnten wir eines Tages unsere digitale Zivilisation nicht auf rotierenden Scheiben, sondern in winzigen, robusten Strängen maßgeschneiderter Moleküle sichern.
Zitation: Wang, Y., Pei, Y., Tang, L. et al. Advances and challenges in non-canonical nucleic acids data storage. Nat Commun 17, 2354 (2026). https://doi.org/10.1038/s41467-026-68708-6
Schlüsselwörter: DNA-Datenspeicherung, nicht-kanonische Nukleinsäuren, molekularer Speicher, unnatürliche Basenpaare, Nanoporen-Sequenzierung