Clear Sky Science · de
Wettstreitende kognitive Anreize bei menschlicher Exploration ohne Trade‑off mit Exploitation
Warum wir erkunden, selbst wenn nichts auf dem Spiel steht
Stellen Sie sich vor, Sie scrollen Restaurantbewertungen oder schlendern durch unbekannte Straßen einer Stadt: Sie erkunden, doch Ihre Klicks oder Schritte bringen Ihnen nicht unmittelbar Gewinn oder Verlust. Diese Studie fragt, wie unsere Neugier in solchen Niedrig‑Einsatzeinstellungen aussieht und ob sie sich von der Art unterscheidet, wie wir erkunden, wenn jede Entscheidung Auszahlung oder Kosten nach sich zieht. Indem die Autorinnen und Autoren unmittelbare Belohnungen in einem sorgfältig kontrollierten Experiment entfernen, decken sie verborgene Tauziehen in unserer Entscheidungsfindung zwischen zwei Arten der Informationssuche auf.
Belohnungen in Farben verwandeln
Die meisten Laborexperimente zur Exploration verwenden Glücksspiel‑artige Aufgaben, in denen jede Wahl Punkte oder Geld einbringt. Dadurch ist schwer zu unterscheiden, ob Menschen wirklich neugierig sind oder einfach nur den Auszahlungen nachjagen. Hier entwarfen die Forschenden eine neue Aufgabe, bei der die „Belohnungen“ lediglich Farbtöne waren, keine Punkte. In jedem Durchgang wählten die Versuchspersonen zwischen zwei abstrakten Formen, die jeweils mit einem Beutel verbunden waren, der überwiegend bläuliche oder überwiegend orangefarbene Ergebnisse lieferte. Wichtig war, dass das Sehen einer Farbe nicht unmittelbar Geld gab oder nahm; stattdessen offenbarte es nur das statistische Muster hinter dieser Option, ähnlich dem Lernen, wie ein einarmiger Bandit sich verhält. 
Drei Wege, dieselbe Frage zu stellen
Die clevere Wendung bestand darin, die Stichprobenerfahrung gleich zu halten und nur die Instruktionen sowie den Zeitpunkt der Belohnungen zu ändern. In der MATCH‑Bedingung wurde den Teilnehmenden gesagt, eine Ziel‑Farbe zu sammeln, und jedes ergebnis, das dieser Ziel‑Farbe näherkam, brachte sofort Punkte — analog zu klassischen „explore–exploit“‑Dilemmas. In der GUESS‑Bedingung gab es während der Stichproben keinen Zielwert; erst am Ende der Sequenz wurden die Teilnehmenden gefragt, welche Option überwiegend blau oder überwiegend orange war, und bezahlt wurde nur für diese finale Antwort. Die FIND‑Bedingung lag dazwischen: Die Ziel‑Farbe war von Beginn an bekannt, aber die Belohnung hing trotzdem nur von einer einzigen abschließenden Wahl ab. Über mehrere unabhängige Gruppen hinweg zeigte das Team, dass die Leistung in allen Bedingungen deutlich über Zufall lag, was bestätigt, dass die Teilnehmenden die Farb‑Option Zuordnungen gelernt hatten.
Chunking versus Unsicherheitsjagd
Wenn Exploration nicht mit unmittelbarer Belohnung konkurrierte, verhielten sich Menschen überraschend strukturiert. In der GUESS‑Bedingung begannen sie jede neue Sequenz, indem sie dieselbe Option mehrfach hintereinander wählten, als wollten sie sich zuerst einen soliden Eindruck von genau dieser Option verschaffen. Erst nach diesem „Chunk“ wiederholter Wahl wechselten sie und begannen später in der Sequenz, diejenige Option zu bevorzugen, die aktuell am unsichersten war. Die Autorinnen und Autoren bezeichnen die erste Neigung als lokale Unsicherheitsminimierung: Reduziere Zweifel an der Option, die du gerade anfasst. Die spätere Neigung ist globale Unsicherheitsminimierung: gezielt die Option beproben, über deren Verhalten man insgesamt am wenigsten weiß. Im Gegensatz dazu zogen Menschen in der MATCH‑Bedingung, in der jedes Ergebnis klaren Wert hatte, schnell zu der Option, die am besten zum Ziel passte, und zeigten deutlich weniger dieses anfängliche Chunking‑Muster. 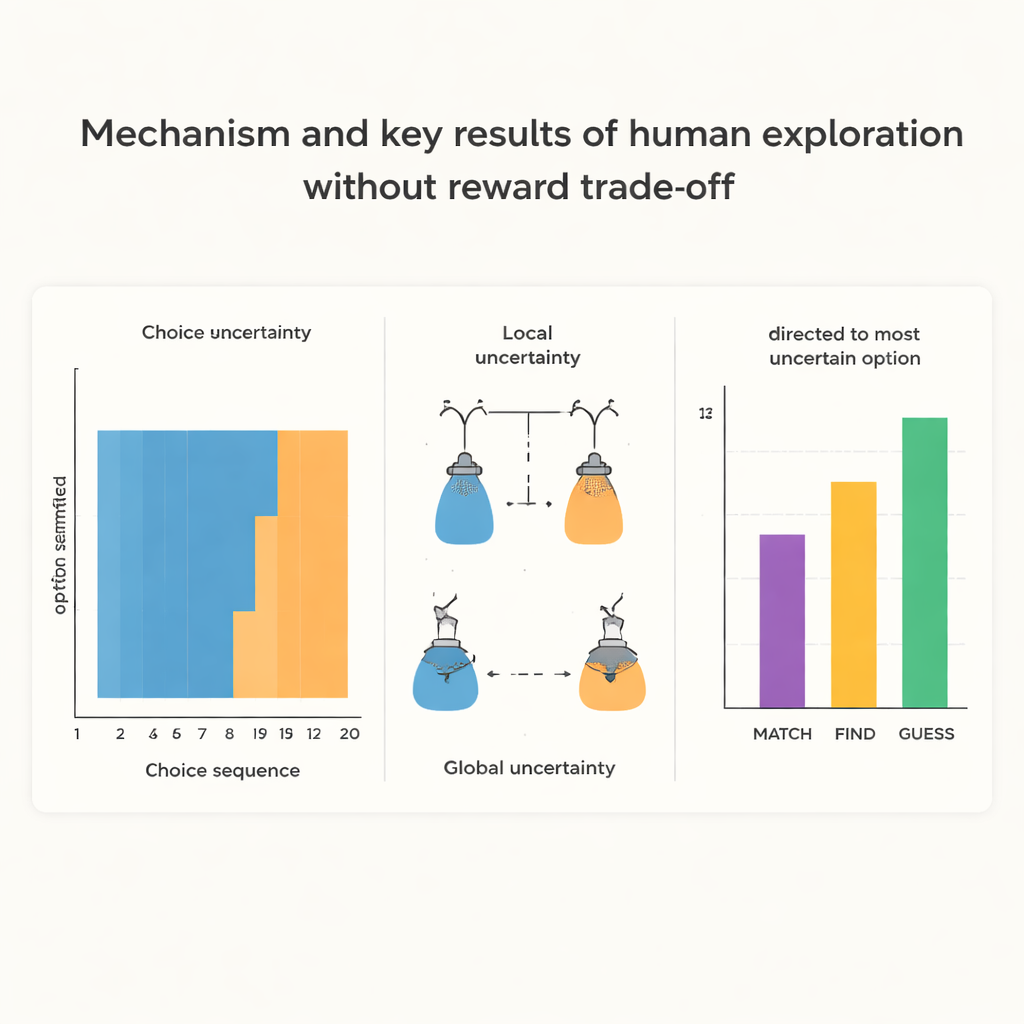
Einen Blick unter die Haube mit Rechenmodellen
Um diese Muster tiefer zu verstehen, bauten die Forschenden mathematische Modelle, die Entscheidungen aus der Historie beobachteter Farben vorhersagen. Ein „optimaler“ Sampler, dem mentale Kosten egal wären, würde immer die unsicherste Option wählen, um Informationen so effizient wie möglich zu gewinnen. Die menschlichen Teilnehmenden verhielten sich nicht wie dieser ideale Agent. Modellanpassungen zeigten, dass Menschen zusätzlich zu einer moderaten Neigung, Unsicherheit zu jagen, wenn Belohnungen verzögert waren, eine starke Verzerrung hatten, die vorherige Wahl zu wiederholen und in vielen Fällen so lange zu wiederholen, bis sie eine persönliche Vertrauensschwelle für diese Option erreicht hatten. Interessanterweise zeigten Personen, die stärkeres frühes Chunking aufwiesen, oft auch später eine stärker gerichtete Exploration und insgesamt bessere Leistung, was darauf hindeutet, dass diese scheinbar suboptimale Strategie angesichts menschlicher kognitiver Beschränkungen tatsächlich ein nützlicher Kompromiss sein kann.
Warum das für alltägliche Neugier wichtig ist
Diese Ergebnisse legen nahe, dass beim Explorieren ohne Sorge um unmittelbare Auszahlungen zwei Kräfte unsere Neugier formen. Die eine treibt uns dazu, bei dem zu bleiben, was wir gerade untersuchen, um sicherzugehen, dass wir es wirklich verstanden haben; die andere schubst uns in Richtung dessen, worüber wir insgesamt am wenigsten wissen. Im Alltag — beim Durchstöbern von Bewertungen, beim Erkunden einer neuen Stadt oder beim Ausprobieren neuer Werkzeuge — spiegelt sich wahrscheinlich dieselbe Balance zwischen lokalem und globalem Informationsstreben wider. Die Studie zeigt, dass wir die Art und Weise, wie Menschen Wissen um seiner selbst willen suchen, möglicherweise missverstehen, wenn wir Exploration nur in belohnungsintensiven Aufgaben untersuchen.
Zitation: Alméras, C., Chambon, V. & Wyart, V. Competing cognitive pressures on human exploration in the absence of trade-off with exploitation. Nat Commun 17, 883 (2026). https://doi.org/10.1038/s41467-026-68639-2
Schlüsselwörter: menschliche Exploration, Entscheidungsfindung, Unsicherheit, Informationssuche, kognitive Modellierung