Clear Sky Science · de
Analoges In‑Memory-Computing für nicht-negative Matrixfaktorisierung
Warum das Aufteilen großer Datenmengen wichtig ist
Alltägliche Dienste wie Filmempfehlungen, Foto‑Apps und genetische Analysen basieren alle darauf, in riesigen Zahlentabellen verborgene Muster zu finden. Eine verbreitete Methode dafür heißt nicht‑negative Matrixfaktorisierung (NMF), die eine große Datentabelle in einfachere Bausteine zerlegt, die leichter zu interpretieren sind. Wenn Datensätze jedoch auf Millionen von Nutzern, Objekten oder Pixeln anwachsen, stoßen heutige digitale Chips in Echtzeit an ihre Grenzen. Diese Arbeit zeigt, wie ein analoges In‑Memory‑Computing‑Konzept diese rechenintensive Aufgabe deutlich schneller und mit wesentlich geringerem Energieaufwand ausführen kann, und so den Weg zu reaktionsschnelleren und effizienteren KI‑gestützten Diensten ebnet.
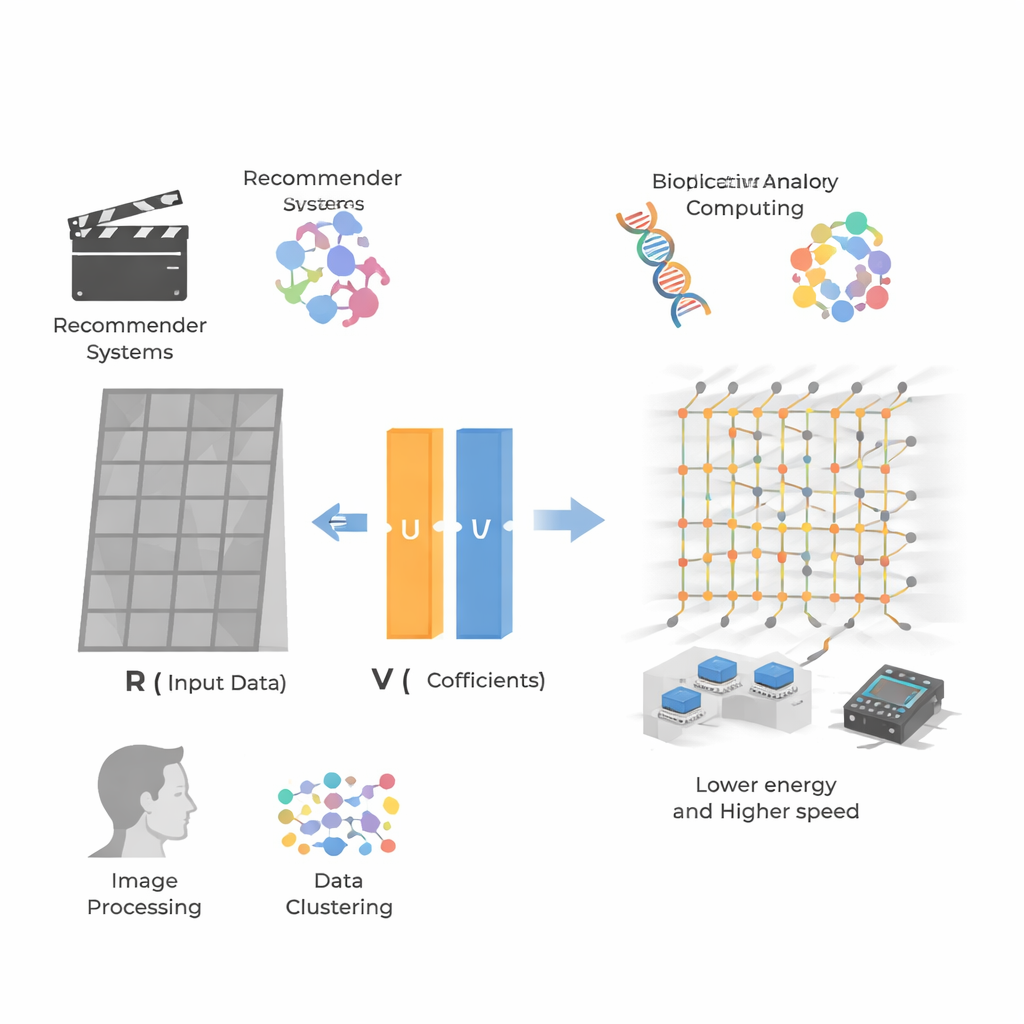
Muster aus riesigen Tabellen extrahieren
Kern der Arbeit ist die nicht‑negative Matrixfaktorisierung (NMF), ein Verfahren, das ein großes Gitter nicht‑negativer Zahlen — etwa Nutzer‑Film‑Bewertungen oder Bildpixelwerte — als Produkt zweier kleinerer Gitter umschreibt. Ein Gitter steht für versteckte „Merkmale“ (zum Beispiel die Vorliebe eines Nutzers für Action versus Romantik), das andere dafür, wie stark jedes Element oder Pixel diese Merkmale ausprägt. Da alle Werte nicht negativ bleiben, sehen diese Merkmale oft wie intuitive Teile aus: Gesichtskomponenten in Bildern oder Präferenzprofile in Empfehlungsdaten. Das macht NMF in Empfehlungssystemen, Bioinformatik, Bildverarbeitung und Clustering beliebt, führt aber bei sehr großen, dünnbesetzten Datensätzen zu hohen Rechenanforderungen.
Warum digitale Chips an eine Grenze stoßen
Traditionelle Prozessoren — CPUs, GPUs und sogar FPGAs — behandeln Matrixoperationen als lange Folgen von Grundschritten und bewegen Daten ständig zwischen Speicher und Recheneinheiten hin und her. Bei moderaten Problemen funktioniert das gut, aber bei modernen Datensätzen mit Millionen von Zeilen und Spalten werden Zeit‑ und Energiekosten enorm. Das Verlangsamen von Moores Gesetz und der sogenannte von‑Neumann‑Flaschenhals, bei dem Speicherzugriffe Leistung und Verzögerung dominieren, erschweren es zunehmend, NMF auf Echtzeitanwendungen wie Live‑Empfehlungen oder schnelle Bildanalyse zu skalieren. Selbst clevere digitale Algorithmen haben noch polynomiale Laufzeitkomplexität und erzeugen starken Speicherverkehr, sobald Matrizen wiederholt aktualisiert werden müssen.
Rechnen im Speicher mit analogen Signalen
Die Autoren wählen einen anderen Weg und nutzen analoges Matrix‑Computing auf Basis resistiver Speicherbauelemente, den sogenannten Memristoren. Diese Bauteile lassen sich in dichten Crossbar‑Arrays anordnen, wobei jeder Kreuzungspunkt einen Leitwert speichert. Wenn an einer Seite Spannungen angelegt werden, führen die an der anderen Seite fließenden Ströme natürlicherweise viele Multiplizier‑und‑Add‑Operationen parallel aus. Durch Verschaltung dieser Arrays in einer geschlossenen Schleife mit einer kleinen Anzahl Operationsverstärker baut das Team eine kompakte generalisierte Inversen‑(GINV‑)Schaltung, die ganze Regressionsprobleme im Wesentlichen in einem analogen Schritt löst, statt in vielen digitalen Iterationen. Sie verfeinern das Design mit einem Leitwert‑Kompensationsschema, das die Schaltung stabil hält und zugleich die Anzahl der Verstärker deutlich reduziert, was Fläche und Leistung spart.
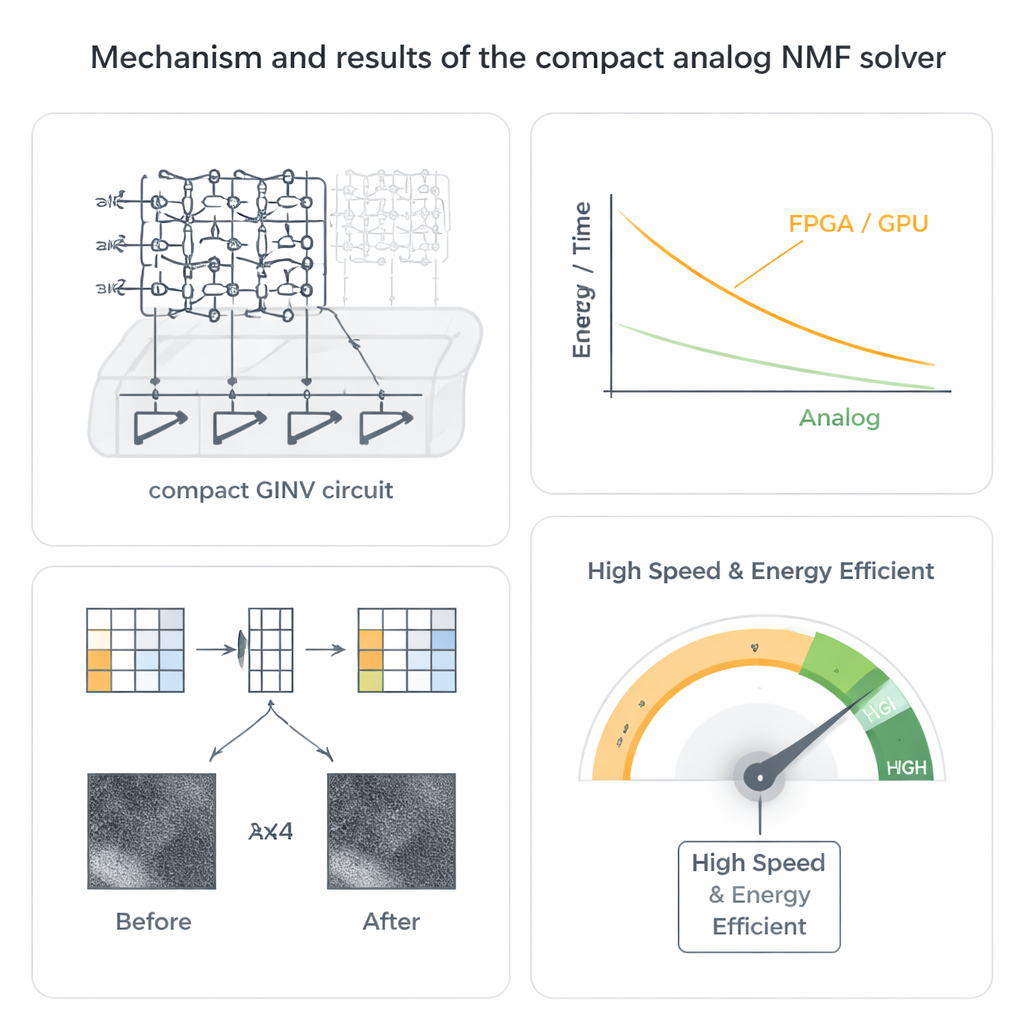
Vom mathematischen Trick zur funktionierenden Hardware
Um dies für NMF praktikabel zu machen, koppeln die Forscher ihre kompakte GINV‑Schaltung mit einer bekannten Strategie namens alternierende nicht‑negative Kleinste‑Quadrate. Statt zu versuchen, beide Faktormatrizen gleichzeitig zu lösen — ein schwieriges nichtkonvexes Problem — verbessert die Methode abwechselnd eine Matrix, während die andere festgehalten wird, und zerlegt die Aufgabe so in eine Kette einfacher nicht‑negativer Regressionsprobleme, die die analoge Schaltung lösen kann. Sie fertigen Hafnium‑oxid‑Memristorarrays an und bauen eine Leiterplattenplattform und demonstrieren dann zwei Schlüsselanwendungen. Bei der Bildkompression wird ein Nebelfoto in kleine Patches aufgeteilt und faktorisiert, wodurch der Speicherbedarf halbiert wird und das Bild nur mit minimalem Qualitätsverlust rekonstruiert wird. Bei Empfehlungssystemen faktorisieren sie Nutzer‑Item‑Bewertungsdaten wie den MovieLens‑100k‑Datensatz und sagen fehlende Bewertungen genau voraus, obwohl die Matrix extrem dünn besetzt ist.
Geschwindigkeit, Effizienz und Robustheit in der Praxis
Über die grundsätzliche Korrektheit hinaus zeigt der analoge Solver bemerkenswerte Vorteile in Geschwindigkeit und Energieverbrauch. Da der Strom durch das Crossbar viele Operationen gleichzeitig repräsentiert, wird die Zeit zur Lösung eines Regressionsproblems nahezu unabhängig von der Matrixgröße — ein deutlicher Kontrast zu digitalen Methoden. Systemniveau‑Schätzungen deuten auf Beschleunigungen von Hunderten bis Tausenden Mal gegenüber fortgeschrittenen FPGA‑ und GPU‑Implementierungen hin, zusammen mit Verbesserungen um mehrere Größenordnungen in der Energieeffizienz. Vielleicht überraschend ist die analoge Natur der Hardware keine Schwäche, sondern eine Stärke: Der NMF‑Algorithmus toleriert Geräte‑Rauschen und Programmierfehler natürlicherweise, und in Simulationen bleiben Bild‑ und Empfehlungsergebnisse selbst dann hoch, wenn die zugrunde liegenden Memristor‑Werte recht ungenau sind oder mit der Temperatur driftieren.
Was das für alltägliche Technik bedeutet
Einfach gesagt zeigt die Studie, dass eine neue Art von „Rechner im Speicher“ eines der Arbeitspferde der modernen Datenwissenschaft viel schneller und effizienter handhaben kann als die heutigen digitalen Chips. Indem Matrixfaktorisierung direkt in kompakte analoge Schaltungen eingebettet wird, könnten Dienste wie Streaming‑Empfehlungen, personalisierte Inhaltsrankings und On‑Device‑Bildverarbeitung künftig in Echtzeit laufen und dabei deutlich weniger Energie verbrauchen. Die Arbeit liefert sowohl einen Schaltungsbauplan als auch experimentelle Belege dafür, dass solches analoges In‑Memory‑Computing realistische Datensätze mit Genauigkeit nahe der vollpräzisen Software bewältigen kann und auf zukünftige Hardware hinweist, die massive Datenströme so mühelos durchsieben kann wie Licht Glas durchdringt.
Zitation: Wang, S., Luo, Y., Zuo, P. et al. In-memory analog computing for non-negative matrix factorization. Nat Commun 17, 1881 (2026). https://doi.org/10.1038/s41467-026-68609-8
Schlüsselwörter: analoges In‑Memory-Computing, nicht-negative Matrixfaktorisierung, Memristor-Crossbar, Bildkompression, Empfehlungssysteme