Clear Sky Science · de
Ein kontextbewusster Dual‑Basecaller für Nanopore‑Direktrna‑Sequenzierung
Warum das Entziffern der RNA‑Buchstaben wichtig ist
Jede Zelle in Ihrem Körper liest und kopiert ständig Nachrichten, die in RNA geschrieben sind — die Arbeitskopie unserer Gene. Neue „Nanopore“-Geräte können einzelne RNA‑Moleküle direkt lesen und versprechen, zu zeigen, wie Gene ein‑ oder ausgeschaltet werden, wie RNAs gespleißt werden und wie chemische Markierungen auf RNA Gesundheit und Krankheit beeinflussen. Es gibt jedoch einen Haken: Diese Geräte messen tatsächlich winzige elektrische Ströme, die dann in die vertrauten Buchstaben A, C, G und U „übersetzt“ — also basecalled — werden müssen. Ist diese Übersetzung fehlerhaft, kann die daraus abgeleitete biologische Geschichte stark verzerrt sein. Dieser Artikel stellt Coral vor, ein neues KI‑System, das diese Übersetzung deutlich präziser macht.
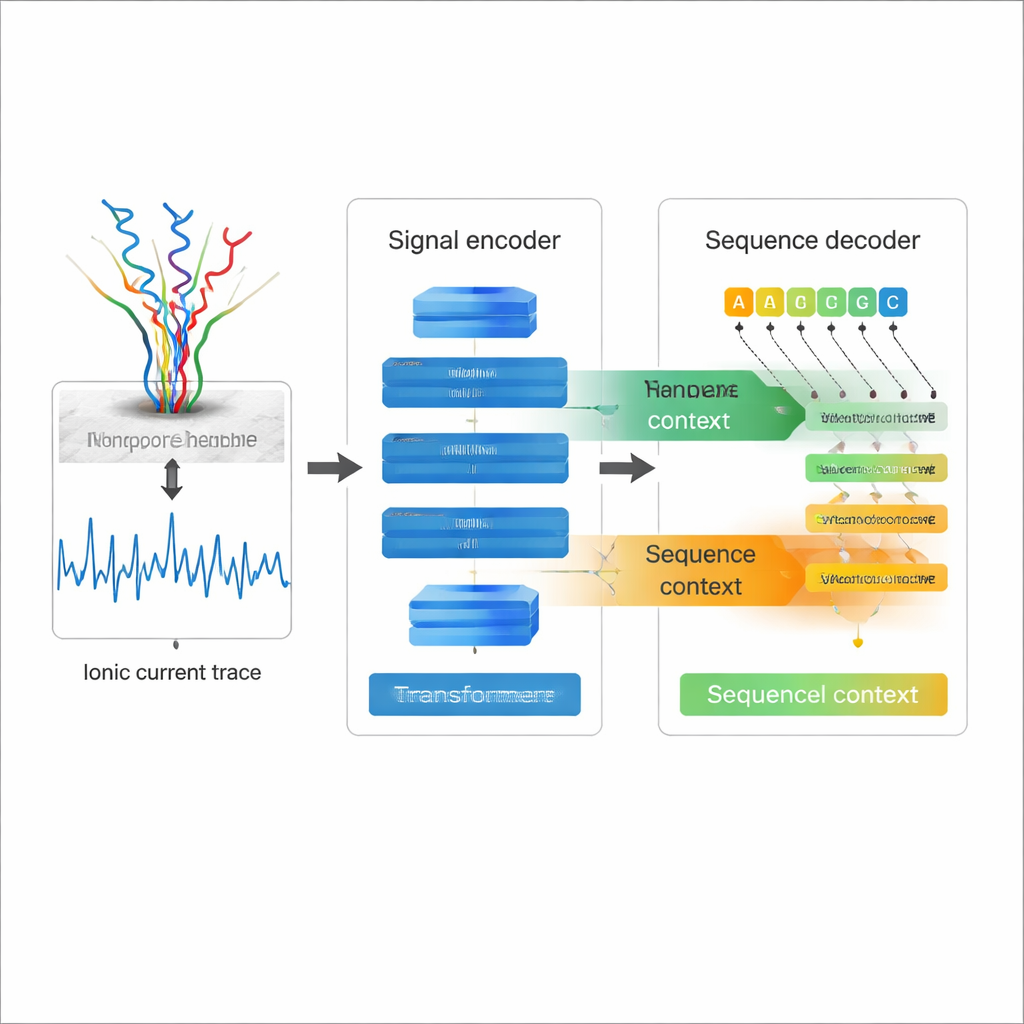
Elektrizität lesen statt Buchstaben
Die Nanopore‑Direktrna‑Sequenzierung funktioniert, indem ein einzelner RNA‑Strang durch ein molekulares Loch — eine Nanopore — gezogen wird, während gemessen wird, wie sich der elektrische Strom ändert, wenn jeweils eine Nukleotid durch die Pore passiert. Diese gewellten Stromverläufe enthalten die Informationen über die RNA‑Sequenz und ihre chemischen Modifikationen. Traditionelle RNA‑Sequenzierung wandelt RNA hingegen in DNA um und amplifiziert sie, Schritte, die Verzerrungen einführen und viele natürliche chemische Markierungen löschen können. Direkte RNA‑Sequenzierung vermeidet diese Probleme, doch der Preis war bislang eine vergleichsweise hohe Fehlerrate bei der Umwandlung von Stromverläufen in Sequenzen, insbesondere bei schwierigen Merkmalen wie Wiederholungssequenzen und komplexen RNA‑Strukturen. Besseres Basecalling ist entscheidend, wenn Wissenschaftler den feinen Details dieser langen RNA‑Reads vertrauen wollen.
Ein klügerer Übersetzer, der zwei Kontextarten nutzt
Die meisten vorhandenen Nanopore‑Basecaller behandeln das elektrische Signal als die Hauptinformationsquelle und dekodieren jede Position nahezu unabhängig, was ihre Fähigkeit einschränkt, die Struktur der RNA‑Sequenz selbst zu nutzen. Coral geht einen anderen Weg. Es verwendet eine Transformer‑basierte Encoder‑Decoder‑Architektur, ähnlich modernen Sprachmodellen. Zuerst verarbeitet ein Encoder‑Netzwerk aus Faltungen und Self‑Attention‑Schichten das rohe Stromsignal zu einer kompakten Beschreibung darüber, wie sich das Signal im Zeitverlauf ändert. Dann sagt ein Decoder Schritt für Schritt jedes neue RNA‑Basenzeichen voraus, wobei er gleichzeitig rückblickend auf die bereits geschriebenen Basen und seitlich auf das kodierte Signal schaut. Zwei Arten von Attention — innerhalb der wachsenden RNA‑Sequenz und zwischen Sequenz und Signal — ermöglichen es Coral, sowohl elektrischen als auch sequenziellen Kontext zu gewichten, wenn entschieden wird, welcher Buchstabe als nächstes kommt.
Schärfere Sequenzen und weniger verlorene Moleküle
Die Autoren verglichen Coral mit mehreren führenden Basecallern, einschließlich kommerzieller Werkzeuge von Oxford Nanopore, anhand von RNA aus Menschen und anderen Organismen sowie auf unterschiedlichen Nanopore‑Chemien. Über sechs Arten und ältere RNA‑Sequenzierungskits hinweg erreichte Coral eine typische mediane Read‑Genauigkeit von rund 97 %, deutlich höher als konkurrierende Methoden. Mit dem neuesten RNA‑Kit überstieg die Genauigkeit 99 %. Coral produzierte weniger Mismatches, Insertionen und Deletionen und lieferte längere, besser ausgerichtete Reads mit weniger Sequenzen, die sich überhaupt nicht zuordnen ließen. Es war besonders gut im Umgang mit kurzen Wiederholungsfolgen — sehr häufig in realen Daten — die für andere Werkzeuge eine häufige Fehlerquelle sind. Indem längere Abschnitte korrekter Sequenz zuverlässiger erfasst wurden, schnitt Coral auch bei der Vorhersage kurzer Sequenzmuster (k‑mer) besser ab und blieb robust, selbst wenn frühere Dekodierschritte kleine Fehler enthielten.
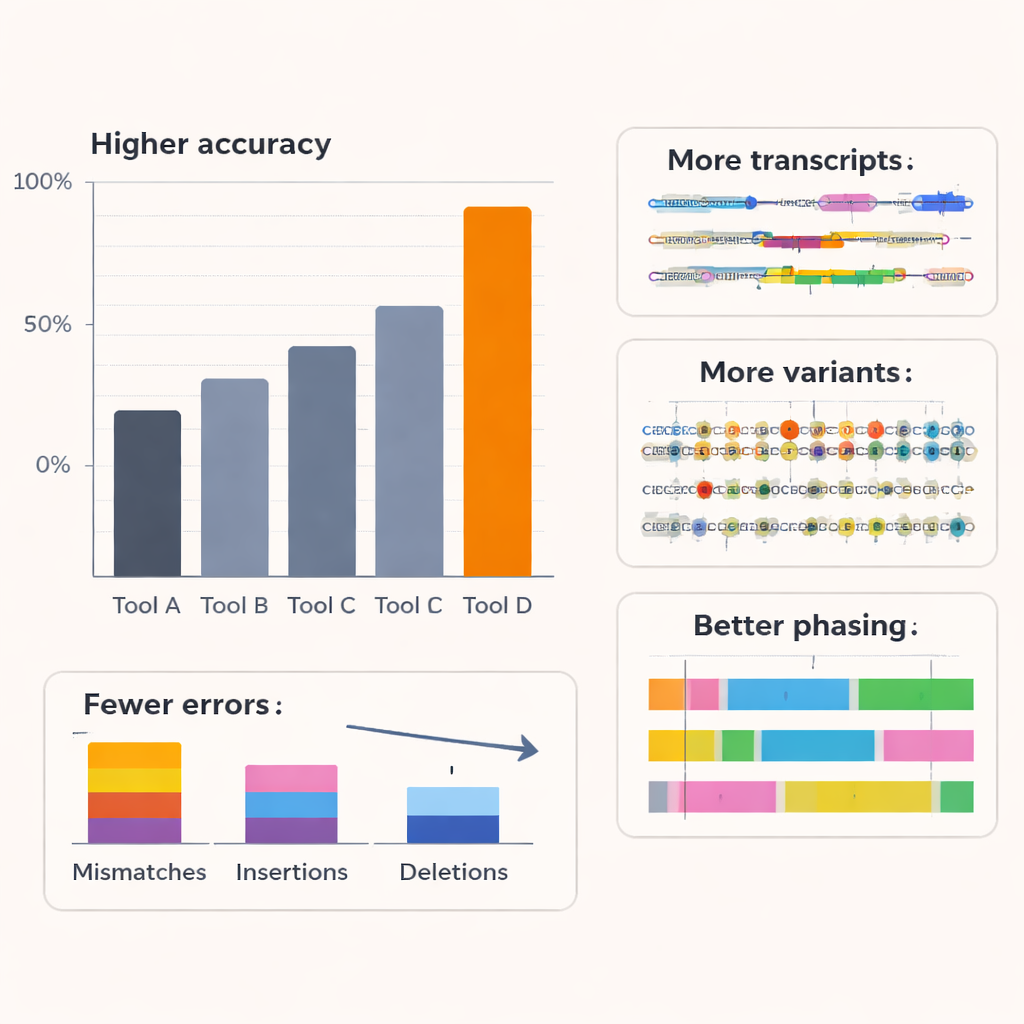
Mehr versteckte Details des Transkriptoms sehen
Verbessertes Basecalling ist nur dann wertvoll, wenn es zu besserer Biologie führt. Um das zu prüfen, untersuchte das Team, wie Corals Ergebnisse nachgelagerte Analysen in menschlichen Zelllinien beeinflussten. Mit einem spezialisierten Werkzeug zur Rekonstruktion vollständiger RNA‑Isoforme — der unterschiedlichen Spleißvarianten jedes Gens — fanden sie, dass Corals Reads mehr bekannte Transkriptstrukturen und viele zusätzliche, niedrig abundant vorkommende Isoforme offenlegten, die andere Basecaller verpassten. Viele Coral‑spezifische Transkripte wurden durch unabhängige Short‑Read‑Daten gestützt, was darauf hindeutet, dass sie echt und keine Artefakte sind. Coral erkannte außerdem mehr künstliche Referenztranskripte mit bekannten Konzentrationen in einem Spike‑in‑Experiment und schätzte deren Häufigkeit genauer. Über die Transkriptentdeckung hinaus verbesserte Coral die Erkennung von Genfusionen in einer Brustkrebs‑Zelllinie und erhöhte Anzahl und Zuverlässigkeit von Genen mit allel‑spezifischer Expression, bei der eine elterliche Kopie eines Gens aktiver ist als die andere.
Klarere genetische Varianten und familiäre Linien
Weil lange RNA‑Reads entfernte genetische Varianten überspannen können, sind sie mächtige Werkzeuge, um zu bestimmen, welche Varianten gemeinsam auf derselben Chromosomenkopie vorkommen — ein Prozess, der Haplotyp‑Phasierung genannt wird. Anhand einer gut untersuchten menschlichen Probe mit einer Gold‑Standard‑Variantenkarte zeigten die Autoren, dass Corals höherwertige Reads zu genauerer Erkennung einzelner Nukleotidveränderungen führten und deutlich weniger Phasierungsfehler verursachten: Switch‑Fehler und die Gesamtfehlerrate innerhalb phasierter Blöcke sanken im Vergleich zu anderen Methoden um bis zu etwa drei Viertel, während deutlich mehr Varianten überhaupt phasiert werden konnten. Simulationen, die die zugrunde liegende Read‑Genauigkeit variierten, bestätigten, dass sich bei etwa 95 % Basecalling‑Genauigkeit die Leistung in Transkriptentdeckung, allel‑spezifischer Expression und Phasierung scharf verbessert und danach abflacht. Coral liegt in dieser Zone hoher Vorteile, was darauf hindeutet, dass es den Großteil der biologisch relevanten Informationen aus den verrauschten Nanopore‑Signalen erfasst.
Was das für die zukünftige RNA‑Forschung bedeutet
Für Nicht‑Spezialisten lautet die Kernaussage, dass Coral wie ein deutlich verlässlicherer Übersetzer zwischen der elektrischen Sprache von Nanopore‑Sequenzierern und der genetischen Sprache der RNA wirkt. Durch bessere Nutzung des Kontexts sowohl im Signal als auch in der wachsenden Sequenz produziert es sauberere Reads, die mehr Transkriptvarianten aufdecken, seltene Fusionsgene erkennen und sicherer verfolgen, welche Varianten von welchem Elternteil stammen. Die Software ist Open‑Source, sodass Forscher sie an neue Organismen, Chemien oder sogar zur Untersuchung chemischer Markierungen auf der RNA selbst anpassen können. Während sich die Nanopore‑Technologie weiter verbessert, werden Werkzeuge wie Coral helfen, rohe Stromverläufe in vertrauenswürdige, detaillierte Karten der RNA‑Welt innerhalb von Zellen zu verwandeln.
Zitation: Xie, S., Ding, L., Yu, Y. et al. A dual context-aware basecaller for nanopore direct RNA sequencing. Nat Commun 17, 1851 (2026). https://doi.org/10.1038/s41467-026-68566-2
Schlüsselwörter: Nanopore‑RNA‑Sequenzierung, Basecalling, Transformer‑Modell, Transkript‑Isoforme, Haplotyp‑Phasierung