Clear Sky Science · de
Drei offene Fragen zur Übertragbarkeit polygenetischer Scores
Warum Gesundheitsprognosen aus DNA schwieriger sind, als sie scheinen
Ärztinnen, Ärzte und Forschende hoffen zunehmend, mithilfe DNA-basierter „polygenetischer Scores“ das Risiko einer Person für häufige Erkrankungen wie Diabetes, Herzkrankheiten oder Asthma vorherzusagen. Diese Scores funktionieren jedoch oft nur gut bei Personen, die denen der ursprünglichen Studienteilnehmer ähneln, meist Menschen europäischer Abstammung. Dieser Artikel fragt, warum diese Vorhersagen nicht zuverlässig auf Personen mit unterschiedlichem genetischen Hintergrund oder anderen Lebensumständen „übertragbar“ sind und welche Konsequenzen das für den fairen Einsatz genetischer Risikoscores in der Medizin hat.
Was polygenetische Scores versprechen – und wo sie versagen
Polygenetische Scores fassen die winzigen Effekte vieler genetischer Varianten über das gesamte Genom in einer einzigen Zahl zusammen, die ein Merkmal vorhersagen soll, etwa Körpergröße oder Blutdruck. Sie werden aus großen genomweiten Assoziationsstudien (GWAS) gewonnen, die DNA-Marker mit Merkmalen in Hunderttausenden von Freiwilligen verknüpfen. Werden diese Scores jedoch auf neue Personen angewendet, schwankt ihre Genauigkeit dramatisch. Typischerweise nimmt die Vorhersageleistung ab, je stärker sich die neue Gruppe genetisch oder sozial von den ursprünglichen GWAS-Teilnehmenden unterscheidet. Dies ist das Problem der Übertragbarkeit: Ein Score, der in einem Kontext funktioniert, kann in einem anderen irreführend sein und potenziell gesundheitliche Ungleichheiten vertiefen, wenn er unkritisch eingesetzt wird.
Weiter als die Abstammung: Entfernung auf der genetischen Landkarte
Um dieses Problem zu untersuchen, nutzten die Autorinnen und Autoren Daten der UK Biobank, die genetische und Gesundheitsdaten von über 400.000 Menschen enthält. Sie erstellten polygenetische Scores für 15 stark vererbbare Merkmale wie Körpergröße, Gewicht, Blutbildwerte und Cholesterinwerte, basierend auf einer großen Gruppe überwiegend weißer britischer Teilnehmender. Anschließend prüften sie, wie gut diese Scores Merkmale bei 69.500 weiteren Teilnehmenden vorhersagten, die ein breites Spektrum genetischer Hintergründe abdeckten. Anstatt Menschen in grobe Abstammungskategorien einzuteilen, platzierten die Forschenden jede Person auf einer kontinuierlichen Skala der „genetischen Distanz“: wie weit das DNA-Profil einer Person vom Durchschnitt der GWAS-Teilnehmer entfernt lag, wenn man es auf einer genetischen Landkarte basierend auf Hauptkomponenten projizierte.
Vorhersagekraft schwindet – aber nicht auf einfache oder faire Weise
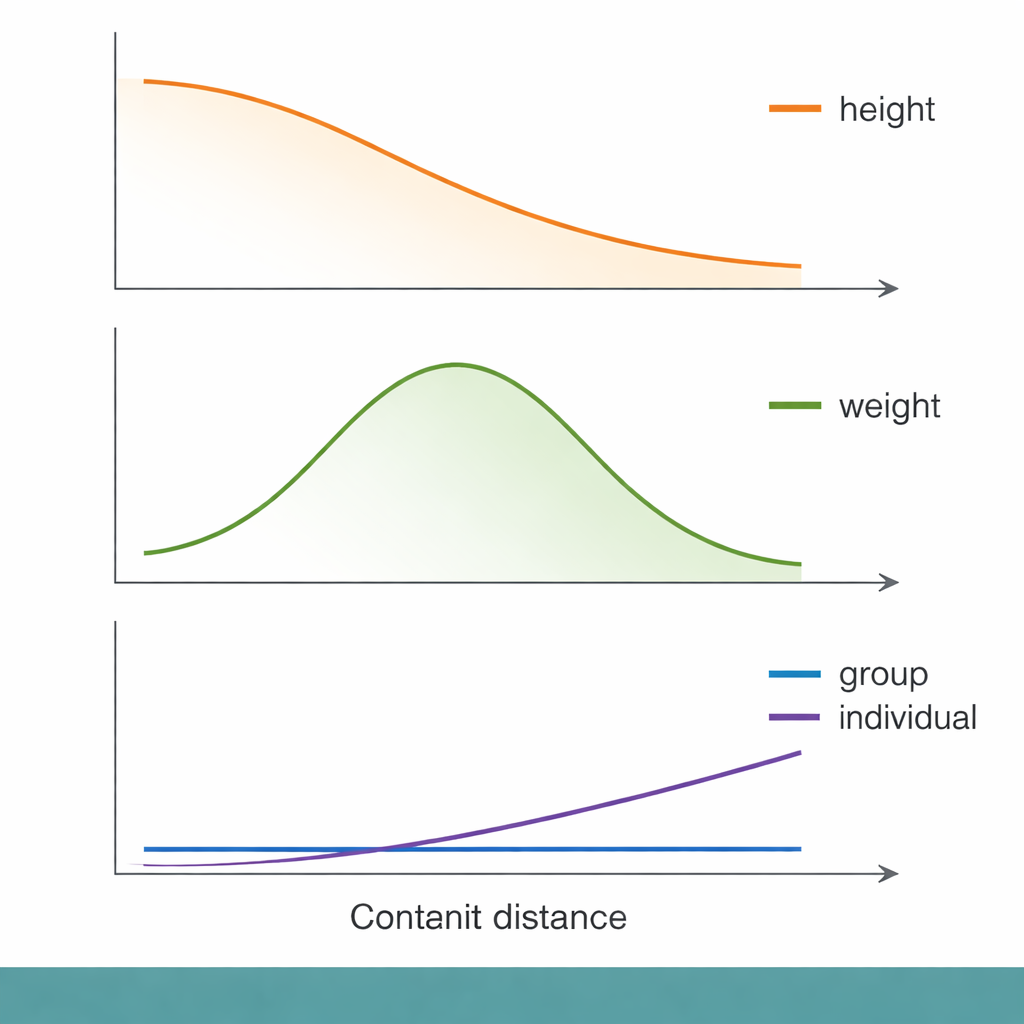
Entlang dieser genetischen Distanzskala zeigten sich einige vertraute Muster. Bei der Körpergröße etwa nahm die Gruppen-Genauigkeit der Vorhersage gleichmäßig ab, je weiter Menschen genetisch vom GWAS-Kollektiv entfernt waren. Auf individueller Ebene erklärte die genetische Distanz jedoch nur einen winzigen Bruchteil der Variabilität in der Vorhersagequalität. Sozioökonomische Maße wie der Townsend Deprivation Index (ein nachbarschaftsbezogener Indikator materieller Benachteiligung) erklärten etwa genauso gut – oder etwas besser –, wer schlechte Vorhersagen erhielt. Anders gesagt: Personen mit niedrigerem sozioökonomischem Status bekamen tendenziell ungenauere genetische Vorhersagen, selbst innerhalb derselben genetischen Distanzbandbreite, was zeigt, dass der soziale Kontext mindestens so wichtig sein kann wie die DNA dafür, ob ein Score nützlich ist.
Verschiedene Merkmale, verschiedene Geschichten, verschiedene Antworten
Nicht alle Merkmale verhielten sich gleich. Bei Körpergewicht und Körperfett erreichte die Vorhersagegenauigkeit tatsächlich an mittleren genetischen Distanzen einen Höhepunkt, bevor sie wieder abnahm, was das einfache Muster „weiter = schlechter“ bricht. Immunbezogene Merkmale wie weiße Blutkörperchen- und Lymphozytenzahlen zeigten besonders rätselhaftes Verhalten. Bei einigen dieser Merkmale sank die Gruppen-Genauigkeit der Vorhersage nahezu auf null, selbst für Personen, die genetisch nicht sehr weit vom GWAS-Sample entfernt waren. Die Autorinnen und Autoren vermuten, dass Immunmerkmale durch sich rasch ändernde evolutionäre Drücke – etwa durch frühere Infektionen – geprägt sind, die beeinflussen, welche DNA-Varianten in verschiedenen Populationen wichtig sind. In solchen Fällen kann sich die genetische Architektur so stark verschoben haben, dass ein auf einer Gruppe basierender Score in einer anderen Gruppe praktisch nutzlos wird.
Wie wir Leistung messen, kann die Geschichte umdrehen
Das Bild wird noch komplizierter, wenn wir ändern, wie „gute Vorhersage“ gemessen wird. Viel Vorarbeit stützte sich auf eine einzelne Kennzahl, R², die erfasst, wie viel Variation eines Merkmals ein Score in einer Gruppe erklärt. Die Autorinnen und Autoren zeigen, dass andere Metriken eine andere Geschichte erzählen können, besonders bei Erkrankungen. Bei Asthma etwa gingen sowohl Präzision (wie viele prognostizierte Fälle echte Fälle sind) als auch Trefferquote/Recall (wie viele echte Fälle gefunden werden) mit genetischer Distanz in ähnlicher Weise zurück. Bei Typ-2-Diabetes blieb die Präzision jedoch relativ konstant, während die Trefferquote mit zunehmender Distanz tatsächlich anstieg – das heißt, der Score fand in entfernteren Gruppen einen größeren Anteil der echten Fälle, obwohl er in einer genetisch näheren Gruppe entwickelt worden war. Je nachdem, ob eine Klinik mehr Wert darauf legt, alle Hochrisikopatienten zu erfassen oder Fehlalarme zu vermeiden, könnte sie zu gegensätzlichen Einschätzungen der Übertragbarkeit gelangen.
Was das für den Einsatz von DNA-Scores in der Praxis bedeutet
Insgesamt argumentiert die Studie, dass man die Nützlichkeit polygenetischer Scores nicht allein anhand breiter Abstammungslabel oder einer einzelnen Genauigkeitszahl beurteilen kann. Die individuelle Vorhersagequalität hängt von einem Mix aus Faktoren ab: feinen Mustern genetischer Ähnlichkeit, der evolutionären Geschichte jedes Merkmals, den Umgebungen und sozialen Bedingungen, in denen Menschen leben, und der konkreten Art, wie der Score und seine Leistungskennzahlen gewählt werden. Damit polygenetische Scores fair und effektiv in der Medizin eingesetzt werden können, brauchen Forschende bessere Methoden, um feinmaschige genetische Struktur zu erfassen, soziale und Umwelt-Einflüsse zu modellieren und Bewertungsmetriken an reale Entscheidungen anzupassen. Bis dahin sollten genetische Risikoscores vorsichtig eingesetzt werden, mit Blick auf die Personen – und Kontexte –, für die sie schlecht funktionieren, ebenso wie auf diejenigen, für die sie nützlich sind.
Zitation: Wang, J.Y., Lin, N., Zietz, M. et al. Three open questions in polygenic score portability. Nat Commun 17, 942 (2026). https://doi.org/10.1038/s41467-026-68565-3
Schlüsselwörter: polygenetische Scores, genetische Vorhersage, gesundheitliche Ungleichheiten, genetische Abstammung, präzisionsmedizin