Clear Sky Science · de
Physische neuronale Netze mit schärfeempfindlichem Training
Warum das für die Zukunft der KI‑Hardware wichtig ist
Während künstliche Intelligenz immer leistungsfähiger wird, wird sie zunehmend nicht mehr durch clevere Algorithmen, sondern durch die Chips, die sie ausführen, begrenzt. Ein vielversprechender Ausweg besteht darin, neuronale Netze direkt in physischer Hardware mit Licht, analogen Elektronikschaltungen oder anderen wellenbasierten Systemen zu realisieren. Dieser Artikel stellt eine neue Methode vor, solche „physischen neuronalen Netze“ so zu trainieren, dass sie genau bleiben, auch wenn die reale Welt unordentlich ist – wenn Geräte leicht fehlerhaft gebaut sind, sich die Temperatur verschiebt oder Bauteile aus der Ausrichtung geraten.
Von digitalen Gehirnen zu physischen Maschinen
Moderne KI läuft meist auf digitaler Hardware wie Grafikprozessoren, wobei das Training auf dem Backpropagation‑Algorithmus beruht, um Millionen numerischer Gewichte anzupassen. Physische neuronale Netze versuchen, diese Berechnungen in echte Materialien und Geräte auszulagern – etwa photonische Chips, Interferometer‑Netze oder diffraktive optische Anordnungen –, deren Verhalten die Mathematik neuronaler Netze natürlicherweise nachahmt. Weil diese Systeme Informationen dort verarbeiten, wo sie gespeichert sind, können sie wesentlich schneller und energieeffizienter sein als konventionelle Chips. Das Training ist jedoch schwierig: Entweder trainiert man ein digitales Modell und hofft, dass es mit der Hardware übereinstimmt, oder man trainiert direkt am Gerät. Beide Wege geraten ins Stocken, wenn reale Geräte von idealen Modellen abweichen oder im Laufe der Zeit driften.
Zwei fehlerhafte Wege, physische Netze zu lehren
Der erste Ansatz, in silico Training genannt, lernt alle Parameter an einem Computermodell und überträgt sie dann auf die Hardware. Das funktioniert nur gut, wenn das mathematische Modell nahezu mit dem gefertigten Gerät übereinstimmt, was selten der Fall ist, sobald Herstellungsvariationen, elektrische Störungen und thermische Effekte hinzukommen. Der zweite Ansatz, in situ Training, bindet das physische Gerät direkt in den Lernprozess ein und misst wiederholt Ausgaben, während Parameter angepasst werden. Zwar umgeht dies Modellierungsfehler, erzeugt aber andere Probleme: Gradienteninformationen sind schwer und teuer zu erhalten, das Training wird gerätespezifisch, und die resultierenden Parameter lassen sich meist nicht auf einen anderen nominal identischen Chip übertragen. In beiden Fällen können kleine Änderungen nach der Inbetriebnahme – etwa eine geringe Temperaturverschiebung oder eine Fehlausrichtung – die Genauigkeit drastisch reduzieren und teures Retraining erzwingen.
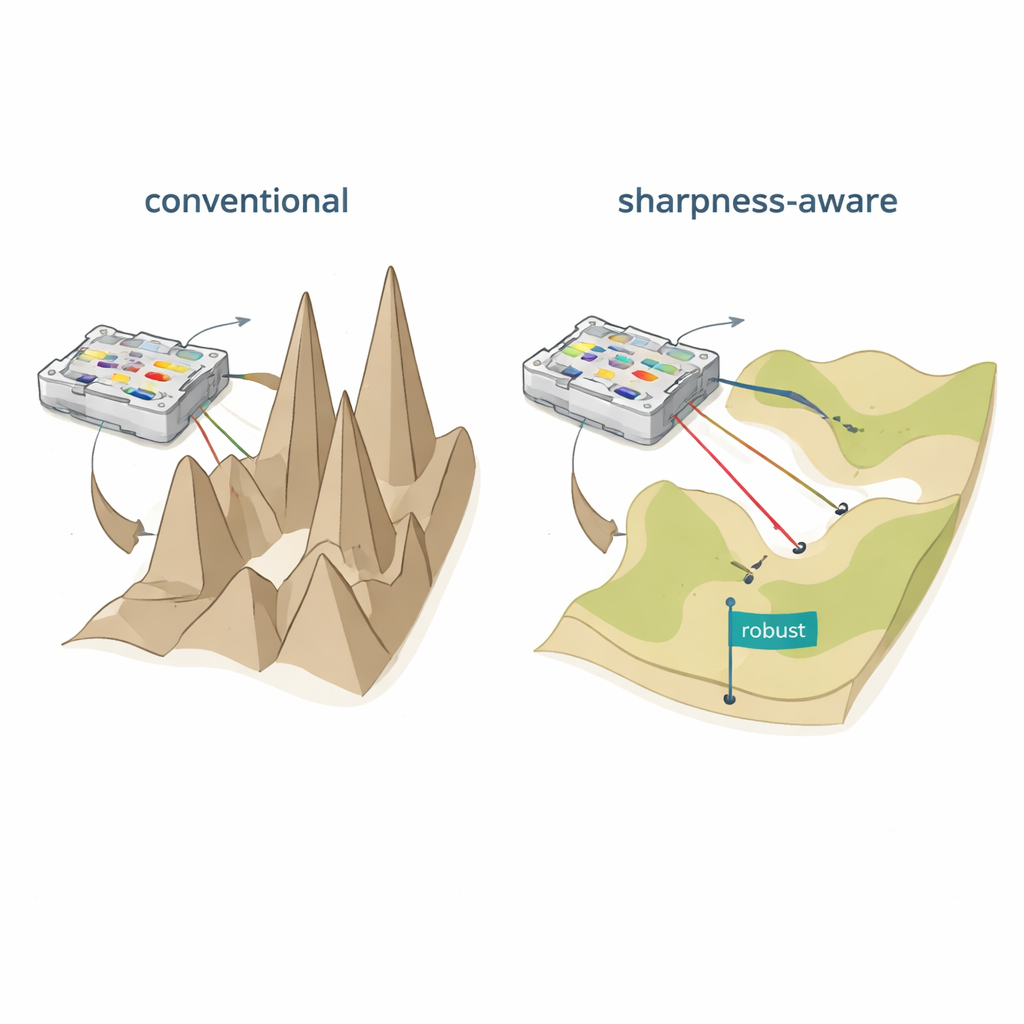
Die Lernlandschaft abflachen
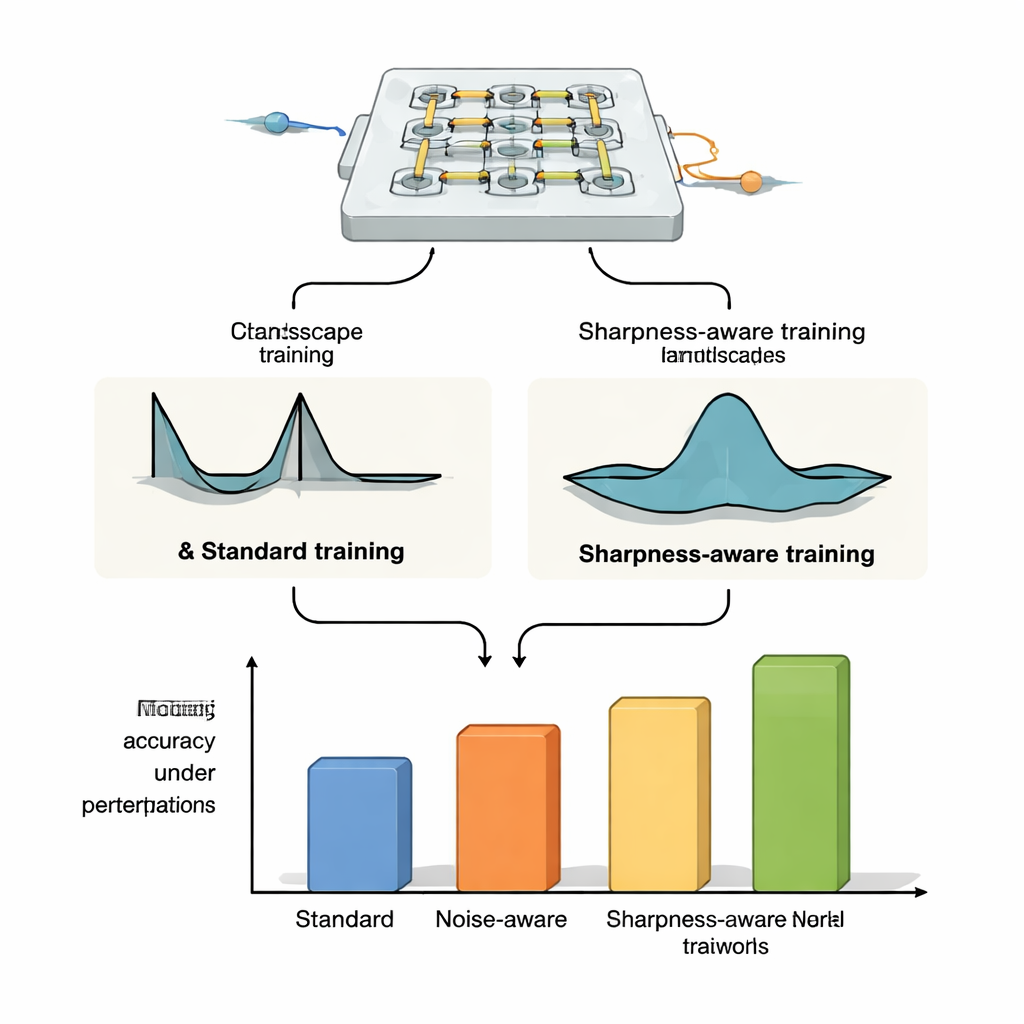
Die Autoren schlagen schärfeempfindliches Training (SAT) vor, inspiriert von einer Idee aus dem maschinellen Lernen namens Sharpness‑Aware Minimization. Statt nur Einstellungen zu finden, die auf den Trainingsdaten geringe Fehler liefern, sucht SAT zusätzlich nach Bereichen, in denen der Fehler sich nur langsam ändert, wenn die zugrunde liegenden physischen Parameter leicht verschoben werden. Geometrisch betrachtet findet traditionelles Training oft ein tiefes, aber schmales Tal in der „Loss‑Landschaft“, in dem schon winzige Verschiebungen von Strömen, Phasen oder Positionen die Leistung zusammenbrechen lassen. SAT sucht bewusst nach breiten, flachen Tälern, in denen die Leistung bei solchen Störungen hoch bleibt. Mathematisch fügt es dem Trainingsziel einen Term hinzu, der scharfe, stark gekrümmte Regionen im Parameterraum bestraft, und es approximiert diese Bestrafung effizient mit zwei sorgfältig gewählten Gradientenschritten statt mit teuren Berechnungen zweiter Ableitungen.
Robustheit auf verschiedenen optischen Plattformen nachweisen
Um zu zeigen, dass SAT nicht an ein bestimmtes Gerät gebunden ist, wenden die Autoren es auf drei verschiedene optische neuronale Netzwerk‑Plattformen an. Bei Mikroring‑Resonator‑Gewichtsbänken – winzige Siliziumschleifen, die Licht bei unterschiedlichen Wellenlängen lenken – zeigen sie, dass SAT‑trainierte Systeme hohe Klassifikationsgenauigkeit beibehalten, selbst wenn die Temperatur um mehrere Grad Celsius driftet, während Standard‑Training und Rauschinjektion dramatisch versagen. Sie erweitern dies auf anspruchsvollere Aufgaben wie Bildklassifikation auf CIFAR‑10, Bildkompression und ‑rekonstruktion sowie Bildgenerierung, wobei SAT die Leistung stabil hält, während konventionelle Methoden bei moderaten thermischen Verschiebungen einbrechen. In Simulationen von Mach‑Zehnder‑Interferometer‑Netzen sind SAT‑trainierte Modelle deutlich toleranter gegenüber realistischen Herstellungsfehlern und – entscheidend – Parameter, die auf einem Gerät trainiert wurden, lassen sich auf andere Chips mit unterschiedlichen Imperfektionen übertragen, ohne Genauigkeit einzubüßen. Schließlich verbessert SAT in einer Freiraum‑diffraktiven optischen Anordnung mit OLED‑Display, Linsen und einem räumlichen Lichtmodulator die Toleranz gegenüber physischen Fehlausrichtungen wie Rotation, Pixelverschiebungen und Skalierung, obwohl die genaue Beziehung zwischen diesen Fehlausrichtungen und den Netzwerkparametern nicht explizit modelliert wird.
Ein praktischer Weg zu zuverlässiger physischer KI
Einfach ausgedrückt zeigt diese Arbeit, wie man Hardware‑Neuronale Netze so trainiert, dass sie die unvermeidlichen Eigenheiten realer Geräte „verzeiht“. Indem das Lernen auf flache, stabile Regionen der Fehlerslandschaft gelenkt wird, macht schärfeempfindliches Training physische neuronale Netze sowohl genauer als auch robuster gegenüber Fertigungsvariationen, Temperaturschwankungen und mechanischen Fehlausrichtungen. Weil es mit oder ohne detaillierte physikalische Modelle einsetzbar ist und über mehrere optische Hardwaretypen hinweg funktioniert, bietet SAT ein praktisches Rezept, um schnelle, energieeffiziente physische KI‑Systeme von Laborversuchen in reale Anwendungen zu skalieren.
Zitation: Xu, T., Luo, Z., Liu, S. et al. Physical neural networks using sharpness-aware training. Nat Commun 17, 1766 (2026). https://doi.org/10.1038/s41467-026-68470-9
Schlüsselwörter: physische neuronale Netze, photonisches Rechnen, robustes Training, schärfeempfindliche Optimierung, neuromorphische Hardware